Удаление повторяющихся строк в Notepad++
Можно ли удалить дублированные строки в Notepad++, оставив только одно вхождение строки?
17 ответов
Notepad++ может сделать это, если вы хотите сортировать по строкам и одновременно удалять дублирующиеся строки.
Вам понадобится плагин TextFX. Раньше это было включено в более старые версии Notepad++, но если у вас более новая версия, вы можете добавить ее из меню, перейдя в Plugins -> Plugin Manager -> Show Plugin Manager -> Available tab -> TextFX -> Install, В некоторых случаях это также можно назвать TextFX Characters, но это одно и то же
Флажки и необходимые кнопки теперь появятся в меню под: TextFX -> TextFX Tools,
Убедитесь, что установлен флажок "сортировать только уникальные выходные данные". Затем выберите блок текста (Ctrl+A, чтобы выделить весь документ). Наконец, нажмите "сортировать строки с учетом регистра" или "сортировать строки с учетом регистра"

Начиная с версии Notepad++ версии 6, вы можете использовать это регулярное выражение в диалоге поиска и замены:
^(.*?)$\s+?^(?=.*^\1$)
и заменить ничем. Это оставляет из всех повторяющихся строк последнее вхождение в файл.
Для этого не требуется сортировка, и повторяющиеся строки могут находиться в любом месте файла!
Вам необходимо проверить параметры "Регулярное выражение" и ". Соответствует новой строке":

^соответствует началу строки.(.*?)соответствует любому символу 0 или более раз, но как можно меньше (это соответствует точно в строке, это необходимо из-за опции ". соответствия новой строки"). Соответствующая строка сохраняется из-за квадратных скобок и доступна с помощью\1$соответствует концу строки.\s+?^эта часть сопоставляет все пробельные символы (символы новой строки!) до начала следующей строки ==> При этом удаляются символы новой строки после строки соответствия, так что после замены не остается пустой строки.(?=.*^\1$)это положительное прогнозное утверждение. Это важная часть в этом регулярном выражении, строка сопоставляется (и удаляется) только тогда, когда точно такая же строка следует в другом месте файла.
Если строки располагаются сразу после друг друга, то вы можете использовать регулярное выражение заменить
Шаблон поиска: ^(.*\r?\n)(\1)+
Заменить: \1
Начиная с Notepad++ версии 8.1, существует специальная команда, которая выполняет именно то, что задает этот популярный вопрос. Можно удалить повторяющиеся строки в текстовом файле с помощью команды меню
Edit > Line Operations > Remove Duplicate Lines.
Нет необходимости устанавливать плагин (как следует из принятого в настоящее время ответа), предварительно сортировать строки или использовать синтаксис регулярного выражения в диалоговом окне `` Заменить '', как предлагали другие ответы.

В версии 7.8 это можно сделать без каких-либо плагинов - Правка -> Операции с линиями -> Удалить последовательные повторяющиеся линии. Вам нужно будет отсортировать файл, чтобы разместить повторяющиеся строки в последовательном порядке, прежде чем это сработает, но это действительно работает как шарм.
Параметры сортировки доступны в меню Правка -> Операции с линиями -> Сортировать по...
Notepad ++
-> Заменить окно
Убедитесь, что в режиме поиска
Вы выбрали переключатель Регулярное выражение
Найти то, что:
^ (. *) (\ Г?\ П \1)+$
Заменить:
$ 1
до:
и мы думаем там
и мы думаем там
одна линия
Это возможно
Это возможно
после:
и мы думаем там
одна линия
Это возможно
Если вам не важен порядок строк (что, я думаю, вам не нужно), вы можете использовать Linux/FreeBSD/Mac OS X/Cygwin и сделать:
$ cat yourfile | sort | uniq > yourfile_nodups
Затем снова откройте файл в Notepad++.
Последние версии Notepad++, по-видимому, вообще не включают плагин TextFX. Чтобы использовать плагин для сортировки / устранения дубликатов, плагин должен быть либо загружен и установлен (более задействован), либо добавлен с помощью менеджера плагинов.
А) Простой способ (как описано здесь).
Плагины -> Диспетчер плагинов -> Показать диспетчер плагинов -> вкладка "Доступно" -> Символы TextFX -> Установить
Б) Более сложный способ, если нужна другая версия или простой способ не работает.
Загрузите плагин от SourceForge:
Откройте zip-файл и распакуйте NppTextFX.dll
Поместите NppTextFX.dll в каталог плагинов Notepad++, например:
C: \ Program Files \ Notepad++ \ pluginsЗапустите Notepad++, и TextFX будет одним из пунктов меню файла (как видно из ответа №1 выше Колина Пикарда)
После установки плагина TextFX следуйте инструкциям в Ответе № 1, чтобы отсортировать и удалить дубликаты.
Кроме того, рассмотрите возможность настройки сочетания клавиш с помощью " Настройки"> "Сопоставление сокращений", если вы часто используете эту команду или хотите скопировать сочетания клавиш, например F9 в TextPad для сортировки.
На данный момент можно удалить все последовательные повторяющиеся строки с помощью встроенных функций Блокнота. Сначала отсортируйте строки:
Правка> Операции со строками> "Сортировка строк лексикографически",
тогда
Правка> Операции с линиями> "Удалить последовательные повторяющиеся линии".
Предложенное выше решение с регулярным выражением не удаляло для меня все повторяющиеся строки, но только последовательные.
Notepad++ имеет встроенные операции:
Edit -> Line Operations -> Sort Lines...
Edit -> Line Operations -> Remove Duplicate Lines
Возможно, это работает только с удалением повторяющихся строк, но мне нужно было убедиться, что операции работают, увидев, что сортировка работает.
Если это не работает, проблема может быть в другом окончании строк, с чем я столкнулся сейчас. Вы можете проверить это с помощьюView -> Show Symbol -> Show End of Line. Замените его, чтобы он был таким же.
Click on Search > Replace (or Ctrl + H)
Find what: \r\n
Replace with: \n
Search Mode: select Extended (\n, \r,...)
Replace All
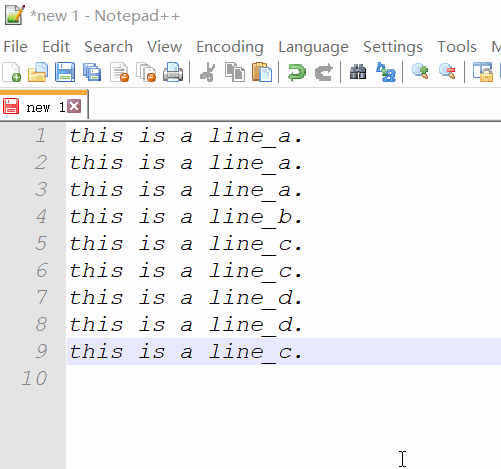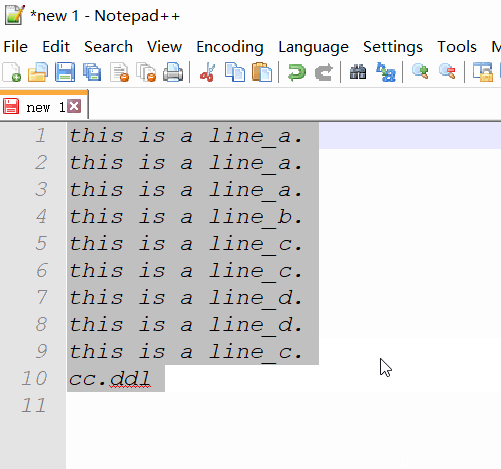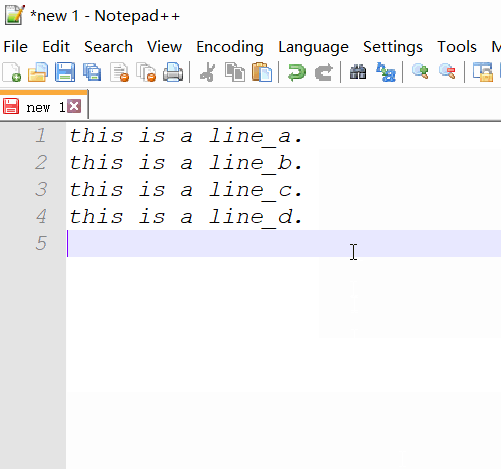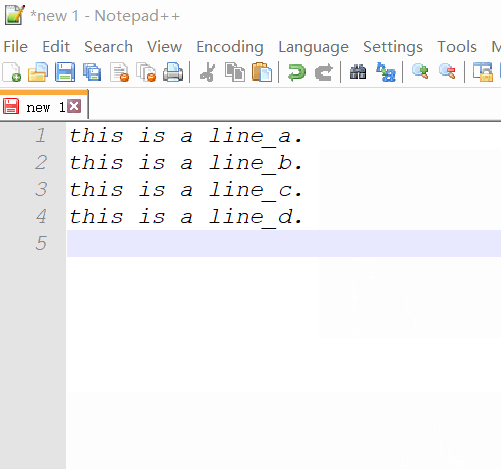
Вам может понадобиться плагин для этого. Вы можете попробовать командную строку cc.ddl(удалить дубликаты строк) ConyEdit. Это кросс-редактор плагин для текстовых редакторов, в том числе Notepad++.
Когда ConyEdit работает в фоновом режиме, выполните следующие действия:
- введите командную строку
cc.ddlв конце текста. - Скопируйте текст и командную строку.
- Вставьте, тогда вы увидите, что вы хотите.
пример
Поиск регулярного выражения: \b(\w+)\b([\w\W]*)\b\1\b
Заменить его на: $1$2
Нажмите кнопку "Заменить", пока в вашем файле больше не будет совпадений для регулярного выражения.
Независимо от того, отсортирован файл или нет, вы можете использовать нижеприведенное регулярное выражение для удаления дубликатов в любом месте вашего файла.
Найти то, что:
^([^\r]*[^\n])(.*?)\r?\n\1$
Заменить:
\1\2
Режим поиска:
- " Регулярное выражение "
- Установите флажок " . Соответствует новой строке "
выполняйте «Заменить все» столько раз, сколько возможно, пока не увидите «0 вхождений было заменено»
Никто не работал для меня.
Решение:
замещать
^(.*)\s+(\r?\n\1\s+)+$
с
\1
Менеджер плагинов в настоящее время недоступен (не входит в дистрибутив) для Notepad++, вы должны установить его вручную ( https://github.com/bruderstein/nppPluginManager/releases), и даже если вы это сделаете, многие плагины недоступны больше (без TextFX) плагин.
Может быть, есть другой плагин, который содержит необходимые функции. Кроме этого, единственный способ сделать это в NotePad++ - использовать какое-то специальное регулярное выражение для сопоставления и последующей замены (CTRL + F -> вкладка Replace).
Хотя есть много функций, доступных через пункт меню Правка (обрезка, удаление пустых строк, сортировка, преобразование EOL), "уникальная" операция недоступна.
Если у вас Windows 10, вы можете включить Bash (просто введите Ubuntu в Microsoft Store и следуйте инструкциям в описании для его установки) и используйте cat your_file.txt | sort | uniq > your_file_edited.txt, Конечно, вы должны находиться в том же рабочем каталоге, что и "your_file.txt", или обращаться к нему по его пути.
Расширяя верхний ответ, вы также можете использовать второй просмотр вперед, чтобы найти строки, которые почти дублируют другие строки.
^(\s*(<PackageReference Include=".*" Version=).*)$\s+?^(?=.*^\2.*$)
Здесь я после нескольких ссылок на одно и то же
<PackageReference Include=".*" строка, независимо от ее версии.
Тестовые данные
<PackageReference Include="Package1" Version="2.2.1" />
<PackageReference Include="Package1" Version="2.2.1" /> // Match
<PackageReference Include="Package1" Version="2.2.2" />
<PackageReference Include="Package2" Version="5.1" /> // Match
<PackageReference Include="Package2" Version="5.2" />
<PackageReference Include="Package3" Version="2.2.1" /> // No match
<PackageReference Include="Package4" Version="2.2.1" />
Посмотрите, что означают термины регулярных выражений, и попробуйте свои собственные данные в этом общем ресурсе regex101 .
На АЭС это сделать сложно. Лучше всего следующий:
Скачайте утилиту cygwin , это простой Linux-терминал под windows. Это позволяет выполнять любую команду Linux в Windows. И у вас там вроде -u.