Расчет количества наблюдений на группу в R
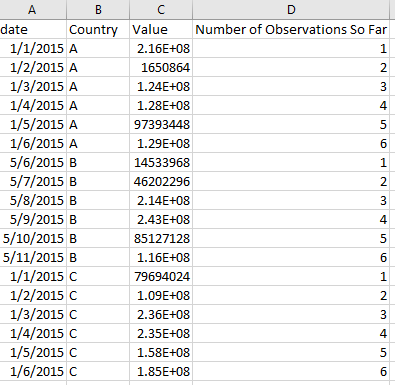
Я хотел бы рассчитать столбец D на основе столбца даты A. Столбец D должен представлять количество наблюдений, сгруппированных по столбцу B.
Изменить: поддельные данные ниже
data <- structure(list(date = structure(c(1L, 2L, 3L, 4L, 5L, 6L, 9L,
10L, 11L, 12L, 7L, 8L, 1L, 2L, 3L, 4L, 5L, 6L), .Label = c("1/1/2015",
"1/2/2015", "1/3/2015", "1/4/2015", "1/5/2015", "1/6/2015", "5/10/2015",
"5/11/2015", "5/6/2015", "5/7/2015", "5/8/2015", "5/9/2015"), class = "factor"),
Country = structure(c(1L, 1L, 1L, 1L, 1L, 1L, 2L, 2L, 2L,
2L, 2L, 2L, 3L, 3L, 3L, 3L, 3L, 3L), .Label = c("A", "B",
"C"), class = "factor"), Value = c(215630672L, 1650864L,
124017368L, 128073224L, 97393448L, 128832128L, 14533968L,
46202296L, 214383720L, 243346080L, 85127128L, 115676688L,
79694024L, 109398680L, 235562856L, 235473648L, 158246712L,
185424928L), Number.of.Observations.So.Far = c(1L, 2L, 3L,
4L, 5L, 6L, 1L, 2L, 3L, 4L, 5L, 6L, 1L, 2L, 3L, 4L, 5L, 6L
)), class = "data.frame", row.names = c(NA, -18L))
Какая функция в R создаст такой столбец D?
1 ответ
Решение
Мы можем сгруппировать по стране и создать столбец последовательности с row_number()
library(dplyr)
df1 %>%
group_by(Country) %>%
mutate(NumberOfObs = row_number())
Или с base R
df1$NumberOfObs <- with(df1, ave(seq_along(Country), Country, FUN = seq_along))
Или с table
df1$NumberOfObs <- sequence(table(df1$Country))
Или в data.table
library(data.table)
setDT(df1)[, NumberOfObs := rowid(Country)][]
данные
df1 <- read.csv('file.csv')