Как перенести мои данные cassandra в pyspark с помощью процессоров QueryCassandra и ExecutePySpark Nifi?
Я просто запрашиваю таблицу cassandra с помощью процессора querycassandra, но я не понимаю, как передать выходной файл Json в процессор ExecutePyspark в качестве входного файла, а затем мне нужно передать выходные данные Spark в Hive. Пожалуйста, помогите мне в этом, спасибо.
My Query Cassandra Свойства:

Pyspark Свойства: 
1 ответ
Рассмотрим этот поток, который использует 4 процессора, как показано ниже:
QueryCassandra -> UpdateAttribute -> PutFile -> ExecutePySpark
Шаг 1: QueryCassandra процессор: выполнить CQL на Cassandra и вывести результат в файл потока.
Шаг 2: UpdateAttribute процессор: назначить свойство filename значение, содержащее имя для временного файла на диске, который будет содержать результаты запроса. Используйте язык выражений NiFi для генерации имени файла, чтобы оно было разным для каждого запуска. Создать недвижимость result_directory и назначьте значение для папки на диске, для которой у NiFi есть права на запись.
- имущество:
filename значение:
cassandra_result_${now():toNumber()}имущество:
result_directory- значение:
/tmp

Шаг 3: PutFile процессор: настроить Directory свойство со значением ${result_directory} заселено в Шаг 2.

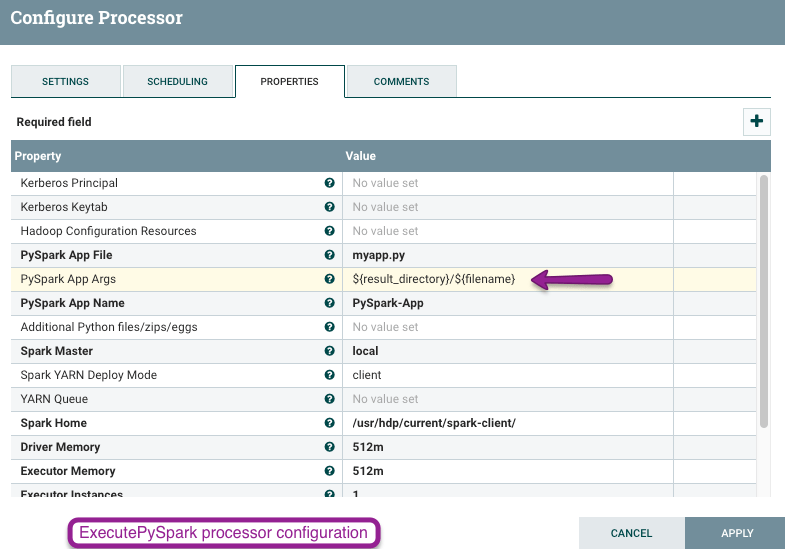
Шаг 4: ExecutePySpark процессор: передайте имя файла с его местоположением в качестве аргумента в приложение PySpark через PySpark App Args свойство процессора. Затем приложение может иметь код для чтения данных из файла на диске, их обработки и записи в Hive.
- имущество:
PySpark App Args - значение:
${result_directory}/${filename}
Кроме того, вы можете настроить дополнительные атрибуты на шаге 2 (UpdateAttribute), которые затем могут быть переданы в качестве аргументов на шаге 4 (ExecutePySpark) и рассмотрены приложением PySpark при записи в Hive (например, база данных Hive и имя таблицы).