Извлечение данных Python из зашифрованного PDF-файла
Я недавно получил высшее образование в области чистой математики и прошел всего несколько базовых курсов программирования. Я прохожу стажировку и у меня есть проект по внутреннему анализу данных. Мне нужно проанализировать внутренние PDF-файлы последних лет. PDF-файлы "защищены". Другими словами, они зашифрованы. У нас нет паролей PDF, более того, мы не уверены, существуют ли пароли. Но у нас есть все эти документы, и мы можем читать их вручную. Мы также можем их распечатать. Наша цель - прочитать их с помощью Python, потому что это язык, который у нас есть.
Сначала я попытался прочитать PDF-файлы с помощью некоторых библиотек Python. Однако обнаруженные мной библиотеки Python не читают зашифрованные PDF-файлы. В то время я также не мог экспортировать информацию с помощью Adobe Reader.
Во-вторых, я решил расшифровать PDF-файлы. Мне удалось использовать библиотеку Python pykepdf. Pykepdf работает очень хорошо! Однако расшифрованные PDF-файлы также нельзя прочитать с помощью библиотек Python из предыдущего пункта (PyPDF2 и Tabula). На данный момент мы сделали некоторые улучшения, потому что с помощью Adobe Reader я могу экспортировать информацию из расшифрованных PDF-файлов, но цель состоит в том, чтобы делать все с помощью Python.
Код, который я показываю, отлично работает с незашифрованными PDF-файлами, но не с зашифрованными PDF-файлами. Он также не работает с расшифрованными PDF-файлами, полученными с помощью pykepdf.
Я не писал код. Я нашел его в документации библиотек Python Pykepdf и Tabula. Решение PyPDF2 было написано Элом Свигартом в его книге "Автоматизируйте скучную работу с помощью Python", которую я настоятельно рекомендую. Я также проверил, что код работает нормально, с ограничениями, которые я объяснил ранее.
Первый вопрос, почему я не могу прочитать расшифрованные файлы, если программы работают с файлами, которые никогда не были зашифрованы?
Второй вопрос: можем ли мы как-нибудь прочитать расшифрованные файлы с помощью Python? Какая библиотека может это сделать, а какая нет? Все ли расшифрованные PDF-файлы можно извлечь?
Спасибо за ваше время и помощь!!!
Я нашел эти результаты, используя Python 3.7, Windows 10, Jupiter Notebooks и Anaconda 2019.07.
Python
import pikepdf
with pikepdf.open("encrypted.pdf") as pdf:
num_pages = len(pdf.pages)
del pdf.pages[-1]
pdf.save("decrypted.pdf")
import tabula
tabula.read_pdf("decrypted.pdf", stream=True)
import PyPDF2
pdfFileObj=open("decrypted.pdf", "rb")
pdfReader=PyPDF2.PdfFileReader(pdfFileObj)
pdfReader.numPages
pageObj=pdfReader.getPage(0)
pageObj.extractText()
С Tabula я получаю сообщение "выходной файл пуст".
С PyPDF2 я получаю только '/n'
ОБНОВЛЕНИЕ 03.10.2019 Pdfminer.six (версия от ноября 2018 г.)
Я получил лучшие результаты, используя решение, опубликованное DuckPuncher. Для расшифрованного файла я получил метки, но не данные. То же самое происходит с зашифрованным файлом. Для файла, который никогда не был зашифрован, отлично работает. Поскольку мне нужны данные и метки зашифрованных или расшифрованных файлов, этот код мне не подходит. Для этого анализа я использовал pdfminer.six, библиотеку Python, выпущенную в ноябре 2018 года. Pdfminer.six включает библиотеку pycryptodome. Согласно их документации "PyCryptodome - это автономный пакет Python низкоуровневых криптографических примитивов.."
Код находится в вопросе обмена стеком: извлечение текста из файла PDF с помощью PDFMiner в Python?
Я буду рад, если вы захотите повторить мой эксперимент. Вот описание:
1) Запустите коды, упомянутые в этом вопросе, с любым PDF-файлом, который никогда не был зашифрован.
2) Сделайте то же самое с PDF-файлом "Защищенный" (это термин, который использует Adobe), я называю его зашифрованным PDF-файлом. Используйте общую форму, которую вы можете найти в Google. После того, как вы его скачаете, вам необходимо заполнить поля. В противном случае вы будете проверять метки, но не поля. Данные есть в полях.
3) Расшифруйте зашифрованный PDF с помощью Pykepdf. Это будет расшифрованный PDF-файл.
4) Снова запустите коды, используя расшифрованный PDF-файл.
ОБНОВЛЕНИЕ 04.10.2019 Камелот (Версия от июля 2019 г.)
Я нашел библиотеку Python Camelot. Будьте осторожны, вам понадобится camelot-py 0.7.3.
Он очень мощный и работает с Python 3.7. Кроме того, им очень легко пользоваться. Во-первых, вам также необходимо установить Ghostscript. Иначе ничего не получится. Вам также необходимо установить Pandas. Не используйте pip install camelot-py. Вместо этого используйте pip install camelot-py[cv]
Автор программы - Винаяк Мехта. Фрэнк Дю делится этим кодом в видео на YouTube "Извлечение табличных данных из PDF с помощью Camelot с использованием Python".
Я проверил код, он работает с незашифрованными файлами. Однако он не работает с зашифрованными и расшифрованными файлами, и это моя цель.
Камелот ориентирован на получение таблиц из PDF-файлов.
Вот код:
Python
import camelot
import pandas
name_table = camelot.read_pdf("uncrypted.pdf")
type(name_table)
#This is a Pandas dataframe
name_table[0]
first_table = name_table[0]
#Translate camelot table object to a pandas dataframe
first_table.df
first_table.to_excel("unencrypted.xlsx")
#This creates an excel file.
#Same can be done with csv, json, html, or sqlite.
#To get all the tables of the pdf you need to use this code.
for table in name_table:
print(table.df)
ОБНОВЛЕНИЕ 07.10.2019 Нашел одну хитрость. Если я открываю защищенный PDF-файл с помощью Adobe Reader, распечатываю его с помощью Microsoft в PDF и сохраняю его как PDF-файл, я могу извлечь данные, используя эту копию. Я также могу конвертировать PDF-файл в JSON, Excel, SQLite, CSV, HTML и другие форматы.Это возможное решение моего вопроса. Однако я все еще ищу возможность обойтись без этого трюка, потому что цель состоит в том, чтобы сделать это на 100% с помощью Python. Я также обеспокоен тем, что при использовании более совершенного метода шифрования уловка, возможно, не сработает. Иногда вам нужно использовать Adobe Reader несколько раз, чтобы получить извлекаемую копию.
ОБНОВЛЕНИЕ 08.10.2019. Третий вопрос. У меня третий вопрос. Все ли защищенные / зашифрованные PDF-файлы защищены паролем? Почему pikepdf не работает? Я предполагаю, что текущая версия pikepdf может взломать некоторые типы шифрования, но не все из них. @constt упомянул, что PyPDF2 может нарушить какой-либо тип защиты. Однако я ответил ему, что нашел статью о том, что PyPDF2 может взламывать шифрование, сделанное с помощью Adobe Acrobat Pro 6.0, но не с последующими версиями.
3 ответа
ПОСЛЕДНЕЕ ОБНОВЛЕНИЕ 10-11-2019
Я не уверен, что полностью понимаю ваш вопрос. Приведенный ниже код можно уточнить, но он читает либо зашифрованный, либо незашифрованный PDF-файл и извлекает текст. Пожалуйста, дайте мне знать, если я неправильно понял ваши требования.
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfpage import PDFPage
from io import StringIO
def extract_encrypted_pdf_text(path, encryption_true, decryption_password):
output = StringIO()
resource_manager = PDFResourceManager()
laparams = LAParams()
device = TextConverter(resource_manager, output, codec='utf-8', laparams=laparams)
pdf_infile = open(path, 'rb')
interpreter = PDFPageInterpreter(resource_manager, device)
page_numbers = set()
if encryption_true == False:
for page in PDFPage.get_pages(pdf_infile, page_numbers, maxpages=0, caching=True, check_extractable=True):
interpreter.process_page(page)
elif encryption_true == True:
for page in PDFPage.get_pages(pdf_infile, page_numbers, maxpages=0, password=decryption_password, caching=True, check_extractable=True):
interpreter.process_page(page)
text = output.getvalue()
pdf_infile.close()
device.close()
output.close()
return text
results = extract_encrypted_pdf_text('encrypted.pdf', True, 'password')
print (results)
Я заметил, что в вашем коде pikepdf, используемом для открытия зашифрованного PDF-файла, отсутствует пароль, который должен был вызвать это сообщение об ошибке:
pikepdf._qpdf.PasswordError: encrypted.pdf: неверный пароль
import pikepdf
with pikepdf.open("encrypted.pdf", password='password') as pdf:
num_pages = len(pdf.pages)
del pdf.pages[-1]
pdf.save("decrypted.pdf")
Вы можете использовать tika для извлечения текста из decrypted.pdf, созданного pikepdf.
from tika import parser
parsedPDF = parser.from_file("decrypted.pdf")
pdf = parsedPDF["content"]
pdf = pdf.replace('\n\n', '\n')
Кроме того, pikepdf в настоящее время не поддерживает извлечение текста, включая последнюю версию v1.6.4.
Я решил провести пару тестов с использованием различных зашифрованных файлов PDF.
Я назвал все зашифрованные файлы encrypted.pdf, и все они использовали один и тот же пароль для шифрования и дешифрования.
Adobe Acrobat 9.0 и новее - уровень шифрования 256-битный AES
- pikepdf смог расшифровать этот файл
- PyPDF2 не смог правильно извлечь текст
- Тика могла правильно извлечь текст
Adobe Acrobat 6.0 и новее - уровень шифрования 128-бит RC4
- pikepdf смог расшифровать этот файл
- PyPDF2 не смог правильно извлечь текст
- Тика могла правильно извлечь текст
Adobe Acrobat 3.0 и новее - уровень шифрования 40-бит RC4
- pikepdf смог расшифровать этот файл
- PyPDF2 не смог правильно извлечь текст
- Тика могла правильно извлечь текст
Adobe Acrobat 5.0 и новее - уровень шифрования 128-бит RC4
- создано с помощью Microsoft Word
- pikepdf смог расшифровать этот файл
- PyPDF2 мог правильно извлекать текст
- Тика могла правильно извлечь текст
Adobe Acrobat 9.0 и новее - уровень шифрования 256-битный AES
- создано с использованием pdfprotectfree
- pikepdf смог расшифровать этот файл
- PyPDF2 мог правильно извлекать текст
- Тика могла правильно извлечь текст
PyPDF2 смог извлечь текст из расшифрованных файлов PDF, созданных не с помощью Adobe Acrobat.
Я предполагаю, что сбои как-то связаны со встроенным форматированием в PDF-файлах, созданных Adobe Acrobat. Чтобы подтвердить это предположение о форматировании, требуется дополнительное тестирование.
tika удалось извлечь текст из всех документов, расшифрованных с помощью pikepdf.
import pikepdf
with pikepdf.open("encrypted.pdf", password='password') as pdf:
num_pages = len(pdf.pages)
del pdf.pages[-1]
pdf.save("decrypted.pdf")
from PyPDF2 import PdfFileReader
def text_extractor(path):
with open(path, 'rb') as f:
pdf = PdfFileReader(f)
page = pdf.getPage(1)
print('Page type: {}'.format(str(type(page))))
text = page.extractText()
print(text)
text_extractor('decrypted.pdf')
PyPDF2 не может расшифровать PDF-файлы Acrobat => 6.0
Этот вопрос открыт для владельцев модулей с 15 сентября 2015 года. В комментариях по этому поводу неясно, когда эта проблема будет исправлена владельцами проекта. Последняя фиксация произошла 25 июня 2018 года.
Проблемы с расшифровкой PyPDF4
PyPDF4 - это замена PyPDF2. Этот модуль также имеет проблемы с расшифровкой определенных алгоритмов, используемых для шифрования файлов PDF.
тестовый файл: Adobe Acrobat 9.0 и выше - уровень шифрования 256-битный AES
Сообщение об ошибке PyPDF2: поддерживаются только коды алгоритмов 1 и 2
Сообщение об ошибке PyPDF4: поддерживаются только коды алгоритмов 1 и 2. В этом PDF-файле используется код 5
ОБНОВЛЕНИЕ РАЗДЕЛА 10-11-2019
Этот раздел является ответом на ваши обновления 10-07-2019 и 10-08-2019.
В своем обновлении вы заявили, что можете открыть "защищенный PDF-файл с помощью Adobe Reader" и распечатать документ в другом PDF-файле, при этом будет удален флаг "ЗАЩИЩЕННЫЙ". После некоторого тестирования я считаю, что выяснил, что происходит в этом сценарии.
Уровень безопасности Adobe PDF
В Adobe PDF есть несколько типов элементов управления безопасностью, которые может включить владелец документа. Элементы управления могут быть реализованы с помощью пароля или сертификата.
Шифрование документа (принудительно с помощью пароля открытия документа)
- Зашифровать все содержимое документа (наиболее часто)
- Зашифровать все содержимое документа, кроме метаданных => Acrobat 6.0
- Шифровать только прикрепленные файлы => Acrobat 7.0
Ограниченное редактирование и печать (принудительно с паролем разрешений)
- Печать разрешена
- Изменения разрешены
На изображении ниже показан файл Adobe PDF, зашифрованный с помощью 256-битного шифрования AES. Чтобы открыть или распечатать этот PDF-файл, требуется пароль. Когда вы откроете этот документ в Adobe Reader с паролем, в заголовке будет указано ЗАЩИЩЕНО.
Для открытия этого документа с модулями Python, упомянутыми в этом ответе, требуется пароль. Если вы попытаетесь открыть зашифрованный PDF-файл с помощью Adobe Reader. Вы должны увидеть это:
Если вы не получаете это предупреждение, значит, в документе либо не включены элементы управления безопасностью, либо включены только ограничения на редактирование и печать.
На изображении ниже показано, что ограниченное редактирование включено с паролем в документе PDF. Печать заметок включена. Чтобы открыть или распечатать этот PDF-файл, пароль не требуется. Когда вы открываете этот документ в Adobe Reader без пароля, в заголовке будет указано ЗАЩИТНО. Это то же самое предупреждение, что и зашифрованный PDF-файл, открытый с паролем.
Когда вы печатаете этот документ в новом PDF- файле, предупреждение SECURED удаляется, потому что снято ограничивающее редактирование.
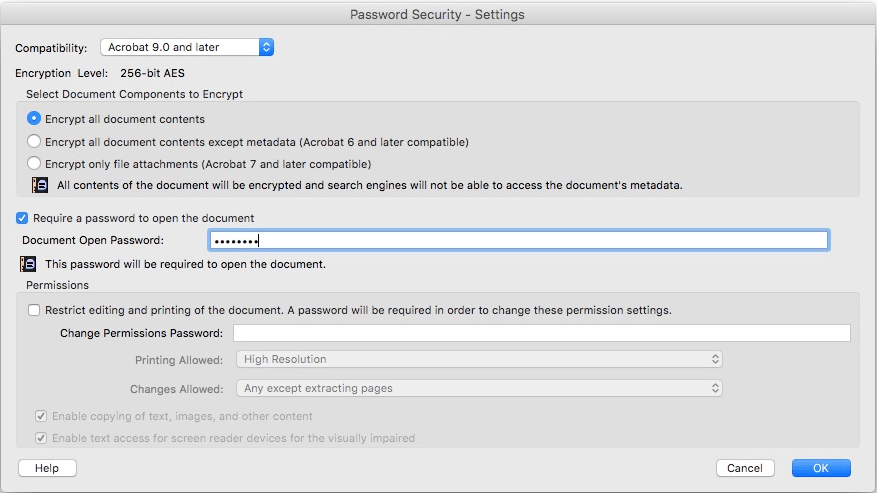
Во всех продуктах Adobe действуют ограничения, установленные паролем доступа. Однако, если сторонние продукты не поддерживают эти параметры, получатели документов могут обойти некоторые или все установленные ограничения.
Поэтому я предполагаю, что для документа, который вы распечатываете в PDF, включено ограничительное редактирование, и для него не включен пароль, необходимый для открытия.
О взломе PDF-шифрования
Ни PyPDF2, ни PyPDF4 не предназначены для взлома функции пароля открытия документа PDF-документа. Оба модуля выдадут следующую ошибку, если попытаются открыть зашифрованный файл PDF, защищенный паролем.
PyPDF2.utils.PdfReadError: файл не расшифрован
Функцию открытия пароля для зашифрованного файла PDF можно обойти с помощью различных методов, но один метод может не работать, а некоторые из них будут неприемлемы из-за нескольких факторов, включая сложность пароля.
Шифрование PDF внутренне работает с ключами шифрования 40, 128 или 256 бит в зависимости от версии PDF. Ключ двоичного шифрования является производным от пароля, предоставленного пользователем. Пароль зависит от длины и кодировки.
Например, PDF 1.7 Adobe Extension Level 3 (Acrobat 9 - AES-256) ввел символы Unicode (65536 возможных символов) и увеличил максимальную длину до 127 байтов в представлении пароля UTF-8.
Приведенный ниже код откроет PDF-файл с включенным ограничительным редактированием. Он сохранит этот файл в новом PDF-файле без добавления предупреждения SECURED. Код tika проанализирует содержимое нового файла.
from tika import parser
import pikepdf
# opens a PDF with restrictive editing enabled, but that still
# allows printing.
with pikepdf.open("restrictive_editing_enabled.pdf") as pdf:
pdf.save("restrictive_editing_removed.pdf")
# plain text output
parsedPDF = parser.from_file("restrictive_editing_removed.pdf")
# XHTML output
# parsedPDF = parser.from_file("restrictive_editing_removed.pdf", xmlContent=True)
pdf = parsedPDF["content"]
pdf = pdf.replace('\n\n', '\n')
print (pdf)
Этот код проверяет, требуется ли пароль для открытия файла. Этот код можно улучшить, и можно добавить другие функции. Есть несколько других функций, которые могут быть добавлены, но документация для pikepdf не соответствует комментариям в базе кода, поэтому необходимы дополнительные исследования для улучшения этого.
# this would be removed once logging is used
############################################
import sys
sys.tracebacklimit = 0
############################################
import pikepdf
from tika import parser
def create_pdf_copy(pdf_file_name):
with pikepdf.open(pdf_file_name) as pdf:
new_filename = f'copy_{pdf_file_name}'
pdf.save(new_filename)
return new_filename
def extract_pdf_content(pdf_file_name):
# plain text output
# parsedPDF = parser.from_file("restrictive_editing_removed.pdf")
# XHTML output
parsedPDF = parser.from_file(pdf_file_name, xmlContent=True)
pdf = parsedPDF["content"]
pdf = pdf.replace('\n\n', '\n')
return pdf
def password_required(pdf_file_name):
try:
pikepdf.open(pdf_file_name)
except pikepdf.PasswordError as error:
return ('password required')
except pikepdf.PdfError as results:
return ('cannot open file')
filename = 'decrypted.pdf'
password = password_required(filename)
if password != None:
print (password)
elif password == None:
pdf_file = create_pdf_copy(filename)
results = extract_pdf_content(pdf_file)
print (results)
Вы можете попытаться обработать ошибку, которую вызывают эти файлы, когда вы открываете эти файлы без пароля.
import pikepdf
def open_pdf(pdf_file_path, pdf_password=''):
try:
pdf_obj = pikepdf.Pdf.open(pdf_file_path)
except pikepdf._qpdf.PasswordError:
pdf_obj = pikepdf.Pdf.open(pdf_file_path, password=pdf_password)
finally:
return pdf_obj
Вы можете использовать возвращенный pdf_obj для анализа. Кроме того, вы можете указать пароль, если у вас есть зашифрованный PDF-файл.
Для tabula-py вы можете попробовать вариант пароля с read_pdf. Это зависит от функции tabula-java, поэтому я не уверен, какое шифрование поддерживается.