Сохраняйте функции в файле csv при нормализации текста машинного обучения с помощью python
Я действительно новичок в питоне. Я пытаюсь разобрать свой набор данных конкретным способом.
Итак, у меня есть файл.csv, например
Это должно быть похоже
Я использую этот блок кода для разбора слов;
dataset = pandas.read_csv('/root/Desktop/%20/%1004.csv' , encoding='cp1252')
for line in dataset['text']:
words = line.split()
for word in words:
tokenize = word_tokenize(word.translate(table))
stopwords= [w for w in tokenize if not w in stop_words]
punc = [token for token in stopwords if not all(char.isdigit() or char == '.' or char == '-' for char in token)]
lemmatized_word = [wordnet_lemmatizer.lemmatize(word) for word in punc]
stemmed_word = [snowball_stemmer.stem(word) for word in lemmatized_word]
print(stemmed_word)
Мой вывод:
Мой образец набора данных:
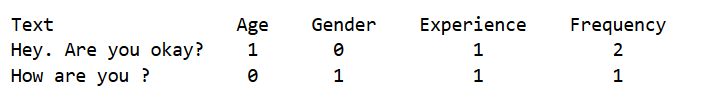
Итак, как я могу проанализировать свой набор данных, как я упоминал выше? и как их записать в файл csv?
Повторяющаяся тема на самом деле не является ответом на мой вопрос. Речь идет о падении.