Сохраните таблицу "Out[]" информационного кадра pandas как рисунок
Это может показаться бесполезной функцией, но это было бы очень полезно для меня. Я хотел бы сохранить вывод, который я получаю внутри Canopy IDE. Я не думаю, что это специфично для Canopy, но для ясности я использую это. Например, моя консоль Out[2] - это то, что я хотел бы получить от этого:
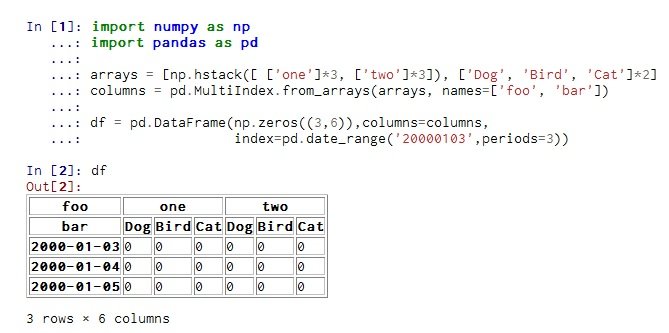
Я думаю, что форматирование довольно приятное, и воспроизводить его каждый раз вместо сохранения результата было бы пустой тратой времени. Итак, мой вопрос, как я могу справиться с этой фигурой? В идеале имплиментация должна быть аналогична стандартным методам, так что это можно сделать так:
from matplotlib.backends.backend_pdf import PdfPages
pp = PdfPages('Output.pdf')
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
df.plot(how='table')
pp.savefig()
pp.close()
ПРИМЕЧАНИЕ: я понимаю, что ранее был задан очень похожий вопрос ( Как сохранить данные из серии / серии данных Pandas в виде рисунка?), Но он так и не получил ответа, и я думаю, что сформулировал вопрос более четко.
3 ответа
Вот несколько хакерское решение, но оно выполняет свою работу. Вы хотели.pdf, но вы получаете бонус.png.:)
import numpy as np
import pandas as pd
from matplotlib.backends.backend_pdf import PdfPages
import matplotlib.pyplot as plt
from PySide.QtGui import QImage
from PySide.QtGui import QPainter
from PySide.QtCore import QSize
from PySide.QtWebKit import QWebPage
arrays = [np.hstack([ ['one']*3, ['two']*3]), ['Dog', 'Bird', 'Cat']*2]
columns = pd.MultiIndex.from_arrays(arrays, names=['foo', 'bar'])
df =pd.DataFrame(np.zeros((3,6)),columns=columns,index=pd.date_range('20000103',periods=3))
h = "<!DOCTYPE html> <html> <body> <p> " + df.to_html() + " </p> </body> </html>";
page = QWebPage()
page.setViewportSize(QSize(5000,5000))
frame = page.mainFrame()
frame.setHtml(h, "text/html")
img = QImage(1000,700, QImage.Format(5))
painter = QPainter(img)
frame.render(painter)
painter.end()
a = img.save("html.png")
pp = PdfPages('html.pdf')
fig = plt.figure(figsize=(8,6),dpi=1080)
ax = fig.add_subplot(1, 1, 1)
img2 = plt.imread("html.png")
plt.axis('off')
ax.imshow(img2)
pp.savefig()
pp.close()
Редактирование приветствуется.
Я считаю, что это HTML-таблица, которую визуализирует ваша IDE. Это то, что делает ноутбук ipython.
Вы можете справиться с этим таким образом:
from IPython.display import HTML
import pandas as pd
data = pd.DataFrame({'spam':['ham','green','five',0,'kitties'],
'eggs':[0,1,2,3,4]})
h = HTML(data.to_html())
h
и сохраните в файл HTML:
my_file = open('some_file.html', 'w')
my_file.write(h.data)
my_file.close()
Я думаю, что здесь необходим согласованный способ вывода таблицы в файл PDF среди графиков, выводимых в файл PDF.
Моя первая мысль - не использовать бэкэнд matplotlib, т.е.
from matplotlib.backends.backend_pdf import PdfPages
потому что он казался несколько ограниченным в параметрах форматирования и склонялся к форматированию таблицы как изображения (таким образом, отображая текст таблицы в невыбираемом формате)
Если вы хотите смешать выходные данные с данными и графики Matplotlib в формате PDF без использования PDF-файла Matplotlib, я могу подумать о двух способах.
- Создайте свой pdf из рисунков matplotlib, как и раньше, а затем вставьте страницы с таблицей данных. Я рассматриваю это как сложный вариант.
- Используйте другую библиотеку для создания PDF. Я проиллюстрирую один вариант сделать это ниже.
Сначала установите xhtml2pdf библиотека. Кажется, это немного поддерживается, но оно активно на Github и содержит некоторую базовую документацию по использованию. Вы можете установить его через pip т.е. pip install xhtml2pdf
Как только вы это сделаете, вот простой пример, в который встраивается фигура matplotlib, затем таблица (можно выбрать весь текст), затем другая фигура. Вы можете поэкспериментировать с CSS и т. Д., Чтобы изменить форматирование в соответствии с вашими точными спецификациями, но я думаю, что это выполнит краткое изложение:
from xhtml2pdf import pisa # this is the module that will do the work
import numpy as np
import pandas as pd
from matplotlib.backends.backend_pdf import PdfPages
import matplotlib.pyplot as plt
# Utility function
def convertHtmlToPdf(sourceHtml, outputFilename):
# open output file for writing (truncated binary)
resultFile = open(outputFilename, "w+b")
# convert HTML to PDF
pisaStatus = pisa.CreatePDF(
sourceHtml, # the HTML to convert
dest=resultFile, # file handle to recieve result
path='.') # this path is needed so relative paths for
# temporary image sources work
# close output file
resultFile.close() # close output file
# return True on success and False on errors
return pisaStatus.err
# Main program
if __name__=='__main__':
arrays = [np.hstack([ ['one']*3, ['two']*3]), ['Dog', 'Bird', 'Cat']*2]
columns = pd.MultiIndex.from_arrays(arrays, names=['foo', 'bar'])
df = pd.DataFrame(np.zeros((3,6)),columns=columns,index=pd.date_range('20000103',periods=3))
# Define your data
sourceHtml = '<html><head>'
# add some table CSS in head
sourceHtml += '''<style>
table, td, th {
border-style: double;
border-width: 3px;
}
td,th {
padding: 5px;
}
</style>'''
sourceHtml += '</head><body>'
#Add a matplotlib figure(s)
plt.plot(range(20))
plt.savefig('tmp1.jpg')
sourceHtml += '\n<p><img src="tmp1.jpg"></p>'
# Add the dataframe
sourceHtml += '\n<p>' + df.to_html() + '</p>'
#Add another matplotlib figure(s)
plt.plot(range(70,100))
plt.savefig('tmp2.jpg')
sourceHtml += '\n<p><img src="tmp2.jpg"></p>'
sourceHtml += '</body></html>'
outputFilename = 'test.pdf'
convertHtmlToPdf(sourceHtml, outputFilename)
Примечание. На момент написания статьи в xhtml2pdf, похоже, была ошибка, означающая, что некоторые CSS не соблюдаются. Особенно уместен этот вопрос в том, что невозможно получить двойные границы вокруг стола
РЕДАКТИРОВАТЬ
В ответных комментариях стало очевидно, что некоторые пользователи (по крайней мере, @Keith, которые и ответили, и присудили награду!) Хотят, чтобы таблица выбиралась, но определенно по оси matplotlib. Это несколько больше соответствует первоначальному методу. Следовательно - вот метод, использующий pdf бэкэнд только для объектов matplotlib и matplotlib. Я не думаю, что таблица выглядит так хорошо - в частности, отображение заголовков иерархических столбцов, но это вопрос выбора, я думаю. Я обязан этому ответу и комментариям о способе форматирования осей для отображения таблицы.
import numpy as np
import pandas as pd
from matplotlib.backends.backend_pdf import PdfPages
import matplotlib.pyplot as plt
# Main program
if __name__=='__main__':
pp = PdfPages('Output.pdf')
arrays = [np.hstack([ ['one']*3, ['two']*3]), ['Dog', 'Bird', 'Cat']*2]
columns = pd.MultiIndex.from_arrays(arrays, names=['foo', 'bar'])
df =pd.DataFrame(np.zeros((3,6)),columns=columns,index=pd.date_range('20000103',periods=3))
plt.plot(range(20))
pp.savefig()
plt.close()
# Calculate some sizes for formatting - constants are arbitrary - play around
nrows, ncols = len(df)+1, len(df.columns) + 10
hcell, wcell = 0.3, 1.
hpad, wpad = 0, 0
#put the table on a correctly sized figure
fig=plt.figure(figsize=(ncols*wcell+wpad, nrows*hcell+hpad))
plt.gca().axis('off')
matplotlib_tab = pd.tools.plotting.table(plt.gca(),df, loc='center')
pp.savefig()
plt.close()
#Add another matplotlib figure(s)
plt.plot(range(70,100))
pp.savefig()
plt.close()
pp.close()