Как подсчитать наиболее часто встречающиеся слова из набора документов, а затем выполнить подгруппы
Из запроса Elasticsearch я могу создать, скажем, около 5000 документов. Теперь я пытаюсь определить, какие безостановочные слова (стоп-слова - это вспомогательные глаголы / незначащие слова) появляются чаще всего.
Так что я попробовал этот запрос, используя significant_text агрегации
$params2 = [
'index' => ["web", "print"],
'type' => 'index',
'from' => 0,
'size' => 10000,
'filter_path' => ['aggregations'],
'body' => [
"query" => //omitted query here
'aggs' => [
'SIGNIFICANT' => [
"significant_text" => [
"field" => "content"
]
]
]
]
];
К сожалению, он все еще отображает некоторые garbage wordsэто не имеет значения для меня
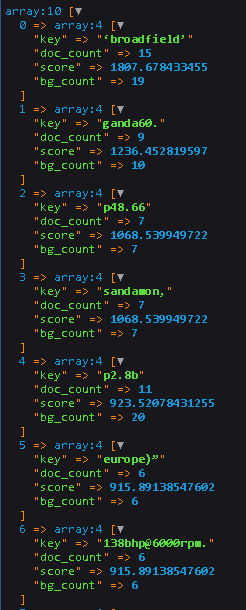
Мои вопросы:
1. Есть ли альтернатива дляsignificant_text агрегация?
- Я также хочу выполнить
termsподгруппа после этогоsignificant_textmain aggs, потому что я хочу объединить запрос, чтобы узнать популярные слова, а затем отфильтровать документы по другим полям
Был бы очень признателен, если бы у вас была идея, как выполнить этот желаемый процесс и вывести