Переоснащение в API обнаружения объектов Tensorflow
I am training tensorflow object detection API model on the custom dataset i.e. License plate dataset. My goal is to deploy this model to the edge device using tensorflow lite so I can't use any RCNN family model. Because, I can't convert any RCNN family object detection model to tensorflow lite model (this is the limitation from tensorflow object detection API). I am using ssd_mobilenet_v2_coco model to train the custom dataset. Following is the code snippet of my config file:
model {
ssd {
num_classes: 1
box_coder {
faster_rcnn_box_coder {
y_scale: 10.0
x_scale: 10.0
height_scale: 5.0
width_scale: 5.0
}
}
matcher {
argmax_matcher {
matched_threshold: 0.5
unmatched_threshold: 0.5
ignore_thresholds: false
negatives_lower_than_unmatched: true
force_match_for_each_row: true
}
}
similarity_calculator {
iou_similarity {
}
}
anchor_generator {
ssd_anchor_generator {
num_layers: 6
min_scale: 0.2
max_scale: 0.95
aspect_ratios: 1.0
aspect_ratios: 2.0
aspect_ratios: 0.5
aspect_ratios: 3.0
aspect_ratios: 0.3333
}
}
image_resizer {
fixed_shape_resizer {
height: 300
width: 300
}
}
box_predictor {
convolutional_box_predictor {
min_depth: 0
max_depth: 0
num_layers_before_predictor: 0
use_dropout: false
dropout_keep_probability: 0.8
kernel_size: 1
box_code_size: 4
apply_sigmoid_to_scores: false
conv_hyperparams {
activation: RELU_6,
regularizer {
l2_regularizer {
weight: 0.00004
}
}
initializer {
truncated_normal_initializer {
stddev: 0.03
mean: 0.0
}
}
batch_norm {
train: true,
scale: true,
center: true,
decay: 0.9997,
epsilon: 0.001,
}
}
}
}
feature_extractor {
type: 'ssd_mobilenet_v2'
min_depth: 16
depth_multiplier: 1.0
conv_hyperparams {
activation: RELU_6,
regularizer {
l2_regularizer {
weight: 0.00004
}
}
initializer {
truncated_normal_initializer {
stddev: 0.03
mean: 0.0
}
}
batch_norm {
train: true,
scale: true,
center: true,
decay: 0.9997,
epsilon: 0.001,
}
}
}
loss {
classification_loss {
weighted_sigmoid {
}
}
localization_loss {
weighted_smooth_l1 {
}
}
hard_example_miner {
num_hard_examples: 3000
iou_threshold: 0.99
loss_type: CLASSIFICATION
max_negatives_per_positive: 3
min_negatives_per_image: 3
}
classification_weight: 1.0
localization_weight: 1.0
}
normalize_loss_by_num_matches: true
post_processing {
batch_non_max_suppression {
score_threshold: 1e-8
iou_threshold: 0.6
max_detections_per_class: 100
max_total_detections: 100
}
score_converter: SIGMOID
}
}
}
train_config: {
batch_size: 24
optimizer {
rms_prop_optimizer: {
learning_rate: {
exponential_decay_learning_rate {
initial_learning_rate: 0.004
decay_steps: 800720
decay_factor: 0.95
}
}
momentum_optimizer_value: 0.9
decay: 0.9
epsilon: 1.0
}
}
fine_tune_checkpoint: "/home/sach/DL/Pycharm_Workspace/TF1.14/License_Plate_F-RCNN/dataset/experiments/training_SSD/ssd_mobilenet_v2_coco_2018_03_29/model.ckpt"
fine_tune_checkpoint_type: "detection"
num_steps: 150000
data_augmentation_options {
random_horizontal_flip {
}
}
data_augmentation_options {
ssd_random_crop {
}
}
}
train_input_reader: {
tf_record_input_reader {
input_path: "/home/sach/DL/Pycharm_Workspace/TF1.14/License_Plate_F-RCNN/dataset/records/training.record"
}
label_map_path: "/home/sach/DL/Pycharm_Workspace/TF1.14/License_Plate_F-RCNN/dataset/records/classes.pbtxt"
}
eval_config: {
num_examples: 488
num_visualizations : 488
}
eval_input_reader: {
tf_record_input_reader {
input_path: "/home/sach/DL/Pycharm_Workspace/TF1.14/License_Plate_F-RCNN/dataset/records/testing.record"
}
label_map_path: "/home/sach/DL/Pycharm_Workspace/TF1.14/License_Plate_F-RCNN/dataset/records/classes.pbtxt"
shuffle: false
num_readers: 1
}
I have total 1932 images (train images: 1444 and val images: 448). I have trained the model for 150000 steps. Following is the output from tensorboard:
DetectionBoxes Точность mAP@0.5 IOU: после 150 000 шагов точность модели обнаружения объекта (mAP@0.5 IOU) составляет ~0,97, т. Е. 97%. Что, кажется, сейчас нормально.
Потери в обучении: после 150 000 шагов потеря в обучении составляет ~1,3. Вроде бы нормально.
Потеря оценки / проверки: после 150 тыс. Шагов потеря оценки / проверки составляет ~3,90, что довольно много. Однако существует огромная разница между обучением и потерей оценки. Есть ли переоснащение? Как я могу решить эту проблему? На мой взгляд, обучение и потеря оценки должны быть близки друг к другу.
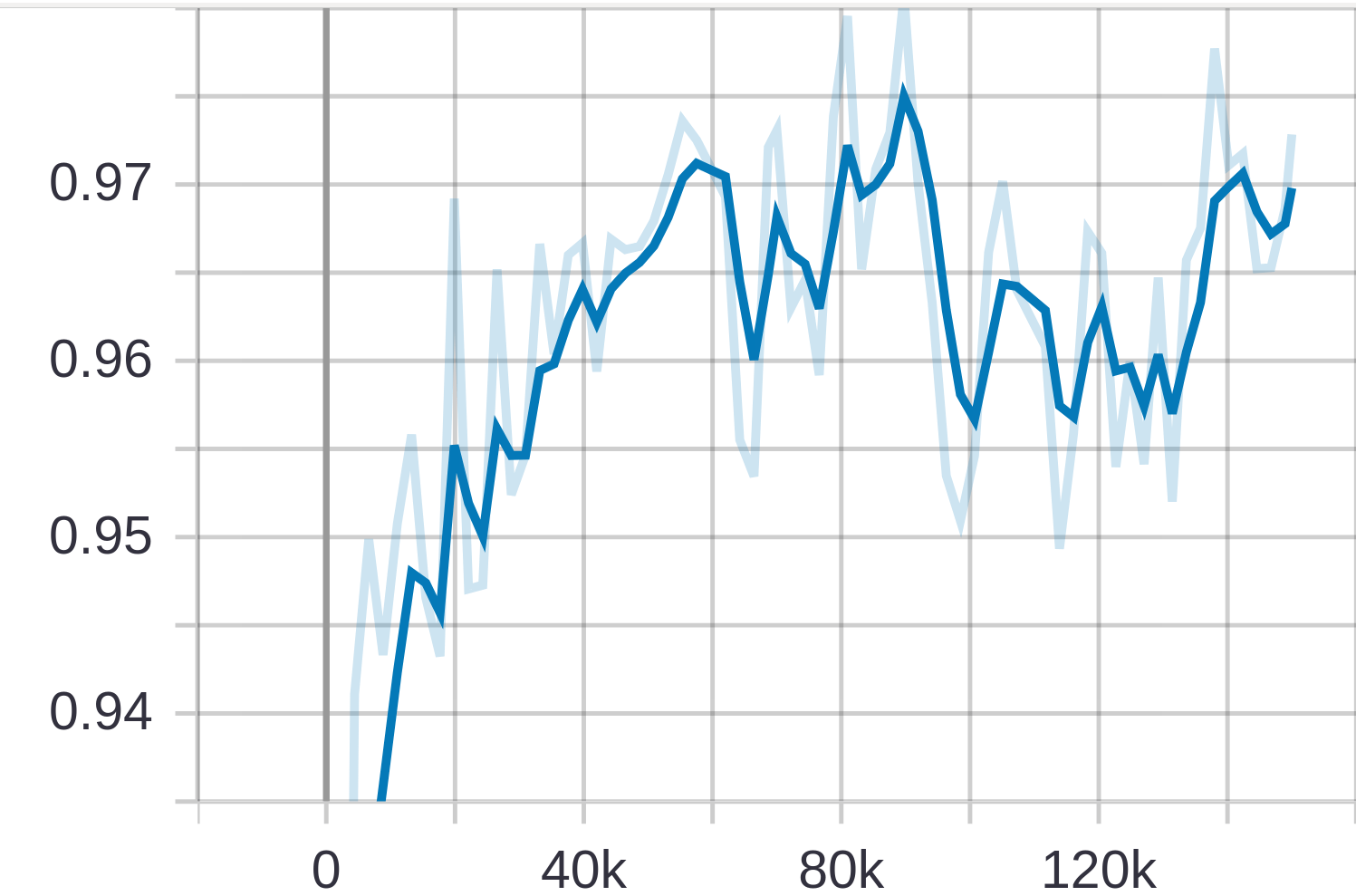
- Как я могу уменьшить потери при проверке / оценке?
- Я использую конфигурационный файл по умолчанию, поэтому по умолчанию
use_dropout: false. Должен ли я изменить его наuse_dropout: trueв случае переобучения? - Каким должен быть допустимый диапазон потерь при обучении и проверке для модели обнаружения объектов?
Пожалуйста, поделитесь своим мнением. Спасибо вам!
1 ответ
Существует несколько причин проблемы переобучения. В нейронных сетях, глядя на ваш файл конфигурации, я хотел бы предложить несколько вещей, чтобы попытаться избежать переобучения.
use_dropout: true так что это делает нейроны менее чувствительными к незначительным изменениям веса.
Попробуйте увеличить iou_threshold в batch_non_max_suppression.
Использовать l1 regularizer или комбинация l1 and l2 regularizer.
Измените оптимизатор на Nadam или Adam Оптимизаторы.
Включить больше Augmentation техники.
Вы также можете использовать Early Stopping чтобы отслеживать вашу точность.
В качестве альтернативы вы можете наблюдать Tensorboard визуализации, возьмите веса перед тем шагом, на котором потери проверки начинают расти.
Я надеюсь, что эти шаги помогут решить проблему переобучения вашей модели.