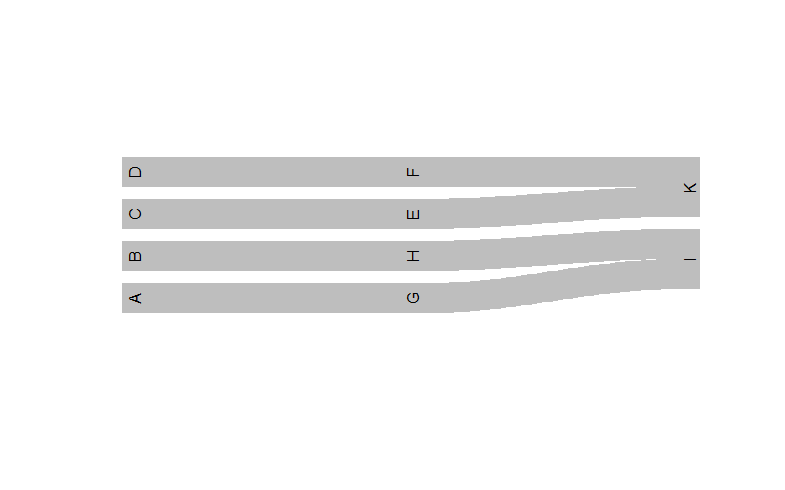
Упорядочение узлов в речном участке
Я в настоящее время разрабатываю riverplot схема с пакетом речного участка. Однако я изо всех сил пытаюсь упорядочить свои данные на участке. Позвольте мне объяснить на примере:
library(riverplot)
df.nodes <- cbind.data.frame(c("A", "B", "C", "D", "E", "F", "G", "H","I","K"), c(1,1,1,1,2,2,2,2,3,3))
colnames(df.nodes) <- c("ID", "x")
df.edges <- cbind.data.frame(c("A", "B", "C", "D", "E", "F", "G", "H"), c("G", "H", "E", "F", "K", "K","I","I"), rep(1, 8))
colnames(df.edges) <- c("N1", "N2", "Value")
ex.river <- makeRiver(df.nodes, df.edges)
plot(ex.river)

Как вы можете видеть, края в этом примере пересекаются друг с другом. Это становится очень запутанным, когда у вас больше узлов, чем в моем примере. Мой вопрос: есть ли у вас креативная идея, как упорядочить узлы, которые я получаю примерно так: (это не код, а порядок вывода на графике, который мне нужен)
D F
C E K
B H I
A G
Края должны пересекаться друг с другом как можно меньше. Как я понимаю df.nodes определяет порядок узлов, поэтому я должен изменить порядок df.nodes как-то. Конечно, я мог бы заказать df.nodes вручную, но если у вас много узлов, это становится сложно.
Любые идеи очень ценятся.
1 ответ
Это было сложно, это требует много операций объединения с использованием data.table, Возможно, есть более разумные решения. Тем не менее, этот работает для данного набора данных.
Основная идея заключается в сортировке узлов и ребер слева направо.
Данные
df.nodes <- data.frame(ID = c("A", "B", "C", "D", "E", "F", "G", "H","I","K"),
x = c(rep(1:2, each = 4L), 3L, 3L),
stringsAsFactors = FALSE)
df.edges <- data.frame(N1 = c("A", "B", "C", "D", "E", "F", "G", "H"),
N2 = c("G", "H", "E", "F", "K", "K","I","I"),
Value = rep(1L, 8),
stringsAsFactors = FALSE)
library(data.table) # CRAN version 1.10.4 used
# coerce to data.table and use abbreviated object names
edt <- setDT(df.edges)
ndt <- setDT(df.nodes)
Получить крайние позиции
# add x positions of nodes to edges
# two joins required for each of the two nodes of an edge
edt2 <- ndt[ndt[edt, on = c(ID = "N2")], on = c(ID = "N1")][
, setnames(.SD, c("N1", "x1", "N2", "x2", "Value"))]
# add unique id number for edge x-positions from left to right
# id reflects order of x pos 1-2, 2-3, ..., 10-11
edt2[order(x1, x2), e.pos := rleid(x1, x2)]
edt2
# N1 x1 N2 x2 Value e.pos
#1: A 1 G 2 1 1
#2: B 1 H 2 1 1
#3: C 1 E 2 1 1
#4: D 1 F 2 1 1
#5: E 2 K 3 1 2
#6: F 2 K 3 1 2
#7: G 2 I 3 1 2
#8: H 2 I 3 1 2
Сортировать слева направо
# initialize: get order of nodes in leftmost x position
# update edt2 with row number
edt2 <- ndt[x == 1L, .(N1 = ID, rn1 = .I)][edt2, on = "N1"]
# loop over edge positions
# determine row numbers (sort order) for nodes from left to right
for (p in edt2[, head(unique(e.pos), -1L)]) {
edt2[p == e.pos, rn2 := rn1]
edt2 <- edt2[p == e.pos, .(N1 = N2, rn1 = rn2)][edt2, on = "N1"]
edt2[, rn1 := dplyr::coalesce(rn1, i.rn1)][, i.rn1 := NULL]
}
edt2[e.pos == last(e.pos), rn2 := rn1]
edt2
# N1 rn1 x1 N2 x2 Value e.pos rn2
#1: A 1 1 G 2 1 1 1
#2: B 2 1 H 2 1 1 2
#3: C 3 1 E 2 1 1 3
#4: D 4 1 F 2 1 1 4
#5: E 3 2 K 3 1 2 3
#6: F 4 2 K 3 1 2 4
#7: G 1 2 I 3 1 2 1
#8: H 2 2 I 3 1 2 2
Извлечь порядок сортировки узлов из таблицы ребер
# extract sort order of all nodes from edge table,
# update node table
ndt <- unique(edt2[, .(ID = c(N1, N2), rn = c(rn1, rn2))], by = "ID")[ndt, on = "ID"]
ndt
# ID rn x
# 1: A 1 1
# 2: B 2 1
# 3: C 3 1
# 4: D 4 1
# 5: E 3 2
# 6: F 4 2
# 7: G 1 2
# 8: H 2 2
# 9: I 1 3
#10: K 3 3
Создать речной участок
library(riverplot)
# pass sorted node table
# coercion back to data.frame required due to type check in `makeRiver()`
ex.river <- makeRiver(setDF(ndt[order(x, rn), .(ID, x)]), setDF(edt))
plot(ex.river)