Градиент политики потерь - обучение по усилению
Я тренирую свою сеть, используя градиент политики и определяя потери как:
self.loss = -tf.reduce_mean(tf.log(OUTPUT_NN)* self.REWARDS))
self.opt = tf.train.AdamOptimizer(self.lr).minimize(self.loss)
Что я не понимаю, так это то, что функция потерь иногда бывает положительной, а иногда отрицательной. Я не понимаю этот переворот в сигнале. Для меня это всегда должно быть отрицательным, так как у меня есть минус перед tf.reduce_mean.
Пример:
Train-> Reward: 0.257782, Hit Ration: 0.500564, True Positive: 0.433404, True Negative: 0.578182, loss: 6.698527
Train-> Reward: 0.257782, Hit Ration: 0.500564, True Positive: 0.433404, True Negative: 0.578182, loss: -11.804675
Это возможно, или я делаю что-то не так в моем коде?
Благодарю.
1 ответ
Не вдаваясь в подробности, вам нужно вычислить градиент уравнения:
где это действие, предпринятое в момент времени t, это состояние при т и является дисконтированным вознаграждением (или не дисконтированным до вас) снова для t.
Итак, в момент времени t вы знаете действие , который вы можете представить как закодированный вектор, верно? Теперь, если вы посмотрите на первый срок вашей потери:
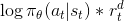
на самом деле это логарифмическая вероятность или перекрестная энтропия. Итак, ваше уравнение должно выглядеть так:
self.loss = -tf.reduce_mean(tf.multiply(tf.nn.softmax_cross_entropy_with_logits_v2(labels=ONE_HOT_ACTIONS, logits=OUTPUT_NN),REWARDS))
self.opt = tf.train.AdamOptimizer(self.lr).minimize(self.loss)