Лучшие типы данных для двоичных переменных в импорте Pandas CSV для уменьшения использования памяти
Мой оригинальный файл для учебных целей имеет 25Gb. Моя машина имеет 64 ГБ оперативной памяти. Импорт данных с параметрами по умолчанию всегда заканчивается "Ошибка памяти", поэтому после прочтения некоторых постов я обнаружил, что лучшим вариантом является определение всех типов данных.
Для целей этого вопроса я использую файл CSV: 100,7 МБ (это набор данных mnist, извлеченный из https://pjreddie.com/media/files/mnist_train.csv)
Когда я импортирую его с настройками по умолчанию в пандах:
keys = ['pix{}'.format(x) for x in range(1, 785)]
data = pd.read_csv('C:/Users/UI378020/Desktop/mnist_train.csv', header=None, names = ['target'] + keys)
# you can also use directly the data from the internet
#data = pd.read_csv('https://pjreddie.com/media/files/mnist_train.csv',
# header=None, names = ['target'] + keys)
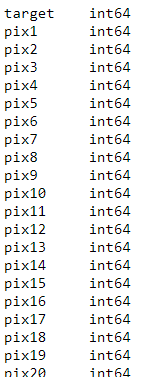
Dtypes по умолчанию для панд:
data.dtypes
Насколько он велик в памяти?
import sys
sys.getsizeof(data)/1000000
376.800104
Если бы я изменил dtypes на np.int8
values = [np.int8 for x in range(1, 785)]
data = pd.read_csv('C:/Users/UI378020/Desktop/mnist_train.csv', header=None, names = ['target'] + keys,
dtype = dict(zip(keys, values)))
Использование моей памяти уменьшается до:
47.520104
Мой вопрос заключается в том, что было бы еще лучше тип данных для двоичных переменных, чтобы уменьшить размер еще больше?
1 ответ
Ссылаясь на документ NumPy, здесь наименее возможным выбором для распределения элементов в массиве / списке является "int8" dtype numpy, который имеет соответствующий "int8_t" в C.
Для двоичных списков / объектов, похожих на списки, типы "uint8", "int8", "byte" или "bool" дают одинаковый размер (распределение) для элемента, который составляет 1 байт.