NonePyspark bluedata hdfs проблема с доступом для записи: hdfs_access_control_exception: разрешение отклонено
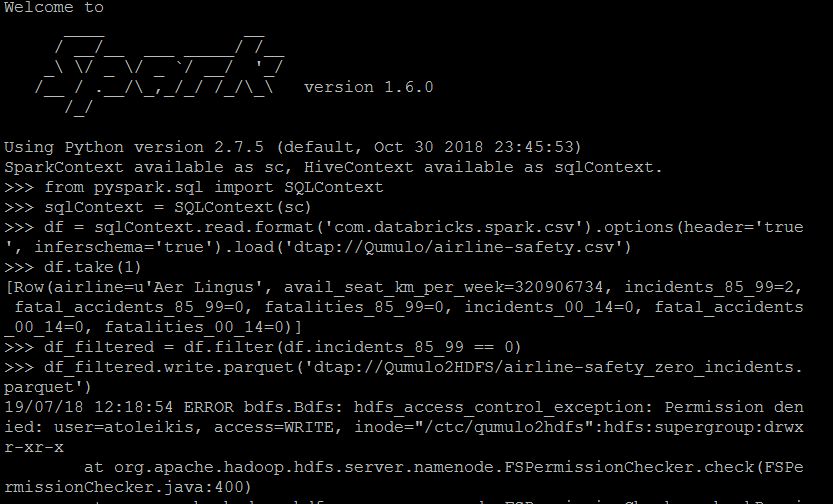
У нас работает BlueData 3.7, и я запустил кластер Cloudera 5.14 с Spark и YARN. Я получаю CSV-файл из Qumulo по NFS для DTAP в контейнер Spark и просто выполняю небольшой фильтр и сохраняю результат в виде файла паркета для DTAP в нашем внешнем HDFS Cloudera Cluster. Все работает, НО запись файла во внешний кластер HDFS. Я могу полностью читать по DTAP из HDFS и записывать по DTAP в Qumulo NFS. Просто запись в HDFS для DTAP не работает. Я получаю сообщение о том, что мой пользователь, входящий в группу AD EPIC, не имеет права писать (как вы видите на следующем рисунке).
Есть идеи, почему это так? DTAP для HDFS НЕ настроен только для чтения. Так что я ожидал, что это будет читать и писать.
Примечание:
- Я уже проверил права доступа в Cloudera.
- Я проверил учетные данные AD в кластере BD.
- Я могу читать с этими учетными данными из HDFS.
Вот мой код:
$ pyspark --master yarn --deploy-mode client --packages com.databricks:spark-csv_2.10:1.4.0
>>> from pyspark.sql import SQLContext
>>> sqlContext = SQLContext(sc)
>>> df = sqlContext.read.format('com.databricks.spark.csv').options(header='true', inferschema='true').load('dtap://TenantStorage/file.csv')
>>> df.take(1)
>>> df_filtered = df.filter(df.incidents_85_99 == 0)
>>> df_filtered.write.parquet('dtap://OtherDataTap/airline-safety_zero_incidents.parquet')
сообщение об ошибке:
hdfs_access_control_exception: в представлении отказано
1 ответ
С помощью людей из службы поддержки BlueData я смог решить эту проблему! Я получил информацию: "Если правила ACL не применяются, то возможно свойство dfs.namenode.acls.enabled не установлен в true. Пожалуйста, измените его на enabled и перезапустите namenode, чтобы включить ACL, иначе настроенный ACL не будет действовать. "Я сделал это и все еще не мог получить доступ к HDFS с помощью команды записи.
Мне также пришлось изменить в самой HDFS права доступа к моей папке, чтобы права записи тоже. Задача решена.