Загрузчик данных Pytorch, слишком много потоков, слишком много памяти процессора
Я тренирую модель, используя PyTorch. Для загрузки данных я использую torch.utils.data.DataLoader, Загрузчик данных использует собственную базу данных, которую я реализовал. Странная проблема возникала, каждый раз, когда второй for в следующем коде выполняется, количество потоков / процессов увеличивается и выделяется огромный объем памяти
for epoch in range(start_epoch, opt.niter + opt.niter_decay + 1):
epoch_start_time = time.time()
if epoch != start_epoch:
epoch_iter = epoch_iter % dataset_size
for i, item in tqdm(enumerate(dataset, start=epoch_iter)):
Я подозреваю, что потоки и воспоминания предыдущих итераторов не освобождаются после каждого __iter__() вызовите загрузчик данных. Выделенная память близка к объему памяти, выделенной основным потоком / процессом при создании потоков. То есть в начальную эпоху основной поток использует 2 ГБ памяти, и поэтому создаются 2 потока размером 2 ГБ. В следующие эпохи основным потоком выделяется 5 ГБ памяти, и создаются два потока по 5 ГБ (num_workers это 2). Я подозреваю что fork() Функция копирует большую часть контекста в новые темы.
Ниже приведен монитор активности, показывающий процессы, созданные python, ZMQbg/1 процессы, связанные с питоном. 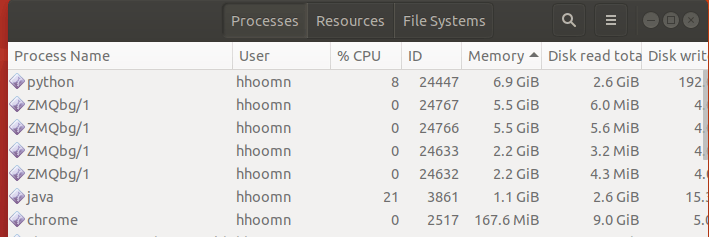
Мой набор данных, используемый загрузчиком данных, содержит 100 наборов данных, __getitem__ Вызов случайным образом выбирает один (игнорируя index). (наборы данных AlignedDataset из pix2pixHD GitHub репозитория):
1 ответ
Torch .utils.data.DataLoader prefetch 2*num_workers, так что у вас всегда будут данные, готовые для отправки в GPU/CPU, это может быть причиной увеличения памяти
https://pytorch.org/docs/stable/_modules/torch/utils/data/dataloader.html