Как читать данные из DataTap, используя pyspark на Cloudera 5.x?
Я создал кластер Cloudera 5.x с установленным параметром Spark:
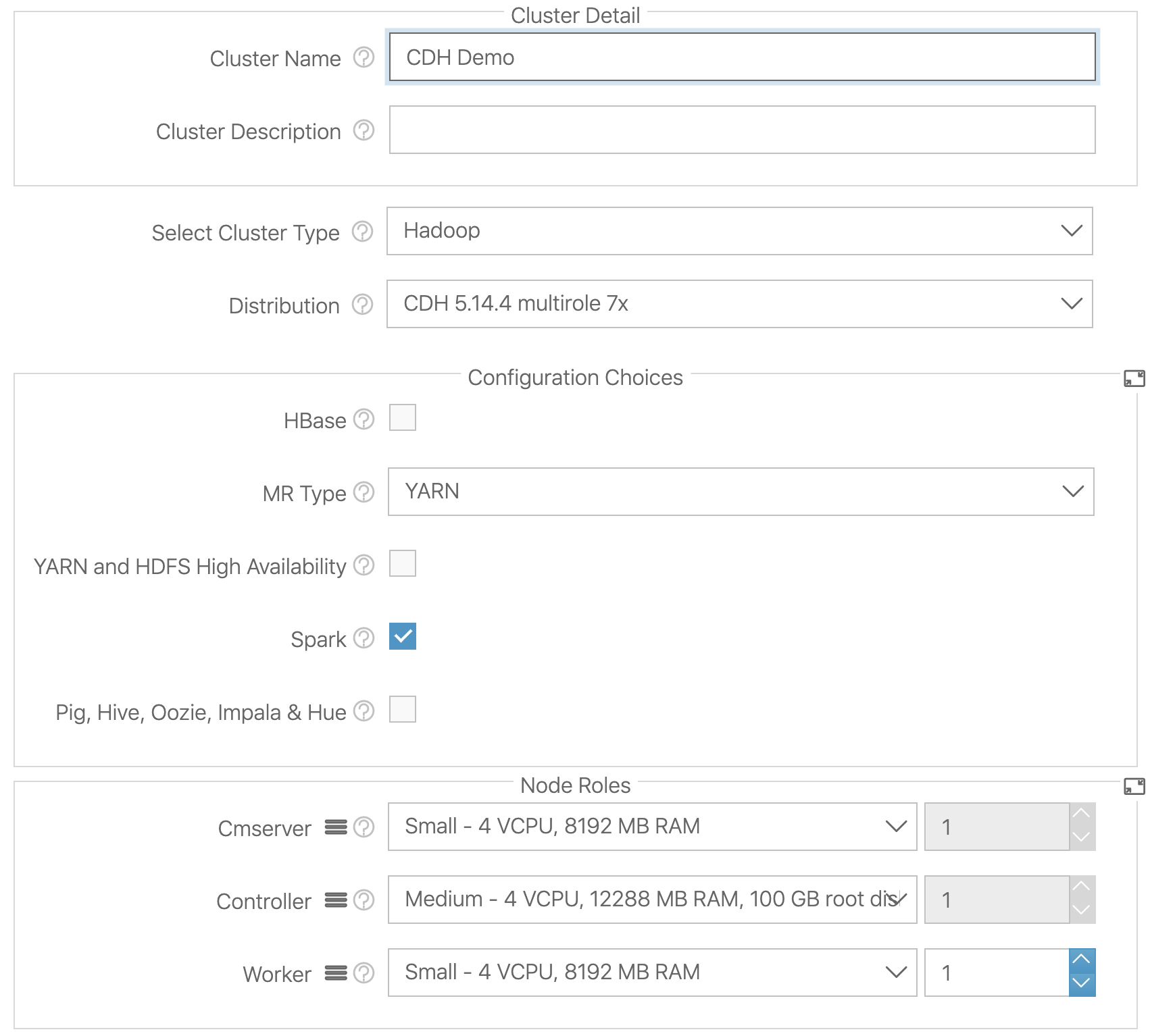
Я хотел бы запустить простой тест с использованием PySpark для чтения данных из одного Datatap и записи его в другой Datatap.
Какие шаги сделать это с PySpark?
1 ответ
В этом примере я собираюсь использовать TenantStorage DTAP, созданный по умолчанию для моего Арендатора.
Я загрузил набор данных с https://raw.githubusercontent.com/fivethirtyeight/data/master/airline-safety/airline-safety.csv
Затем найдите узел контроллера и вставьте в него ssh:
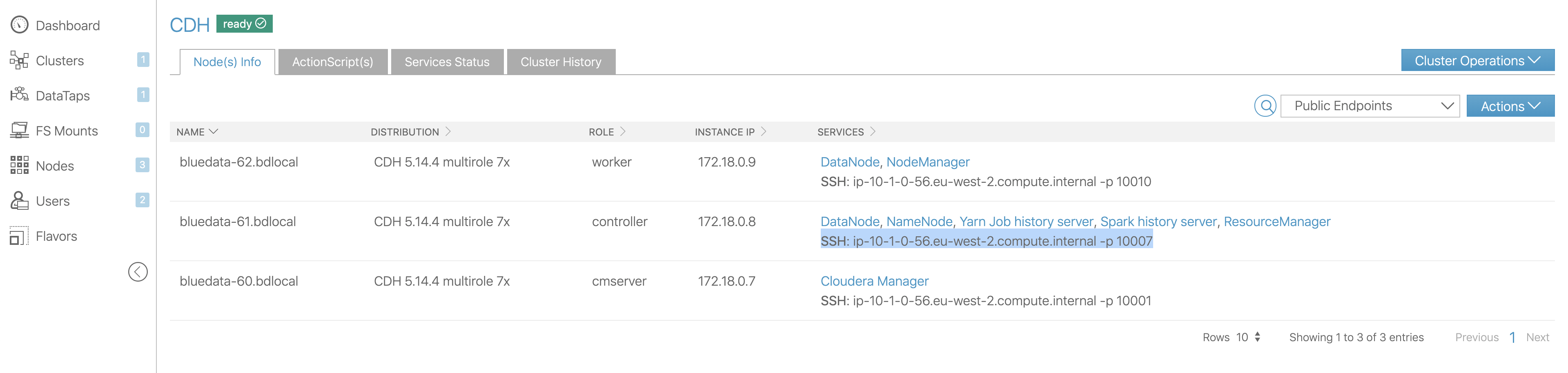
Поскольку клиент настроен с привилегиями суперпользователя кластера по умолчанию (администратор сайта и администратор клиента), я могу загрузить ключ ssh клиента со страницы кластера и использовать его для ssh на узле контроллера:
ssh bluedata@x.x.x.x -p 10007 -i ~/Downloads/BD_Demo\ Tenant.pem
x.x.x.x для меня это публичный IP-адрес моего шлюза BlueData.
Обратите внимание, что мы подключаемся к порту 10007, который является портом контроллера.
Запустите pyspark:
$ pyspark --master yarn --deploy-mode client --packages com.databricks:spark-csv_2.10:1.4.0
Получите доступ к файлу данных и получите первую запись:
>>> from pyspark.sql import SQLContext
>>> sqlContext = SQLContext(sc)
>>> df = sqlContext.read.format('com.databricks.spark.csv').options(header='true', inferschema='true').load('dtap://TenantStorage/airline-safety.csv')
>>> df.take(1)
Результаты:
[Строка (авиакомпания =u'Aer Lingus', util_seat_km_per_week=320906734, инциденты_85_99=2, fatal_accidents_85_99=0, fatalities_85_99=0, инциденты_00_14=0, fatal_accidents_00_14=0, fatalities_00_14=0)
Если вы хотите прочитать данные из одного Datatap, обработайте их и сохраните в другом Datatap, это будет выглядеть примерно так:
>>> df_filtered = df.filter(df.incidents_85_99 == 0)
>>> df_filtered.write.parquet('dtap://OtherDataTap/airline-safety_zero_incidents.parquet')