Ошибка AWS ECS: задача не прошла проверку работоспособности ELB в целевой группе
Я использую шаблон формирования облаков для построения инфраструктуры (кластер ECS fargate). шаблон успешно выполнен и стек успешно создан. однако задача не выполнена со следующей ошибкой:
Task failed ELB health checks in (target-group arn:aws:elasticloadbalancing:eu-central-1:890543041640:targetgroup/prc-service-devTargetGroup/97e3566c8b307abf)
Я не понимаю, что и где искать, чтобы устранить проблему. поскольку это кластер fargate, я не понимаю, как войти в контейнер и выполнить некоторые запросы проверки работоспособности для дальнейшей отладки.
Может кто-нибудь, пожалуйста, помогите мне вести дальше и помочь мне? из-за этой ошибки я даже не могу получить доступ к своему веб-приложению. как ALB не будет направлять трафик, если он вреден для здоровья
что я сделал
после некоторого поиска в Google я нашел этот пост: https://aws.amazon.com/premiumsupport/knowledge-center/troubleshoot-unhealthy-checks-ecs/
однако, я думаю, это связано с совместимостью с EC2 в fargate. но в моем случае EC2 там нет.
если вы чувствуете, я могу также вставить весь шаблон.
пожалуйста помоги
17 ответов
Это решено. Это была проблема со следующими пунктами:
- Отображение порта контейнера Docker с портом хоста было неверным
- Время интервала проверки работоспособности ALB было очень коротким. Из-за этого ALB немедленно сдался, не дожидаясь, пока контейнер докера начнет работать правильно.
после внесения этих изменений все заработало
У этой проблемы может быть несколько различных причин, не только из-за открытых портов:
- Неправильные разрешения IAM для роли IAM ecsServiceRole
- Группа безопасности экземпляра контейнера Нагрузка эластичной балансировки нагрузки
- балансировщик не настроен для всех зон доступности. Эластичная нагрузка.
- Неправильно настроена проверка работоспособности балансировщика нагрузки
- Невозможно обновить service servicename: имя или порт контейнера балансировщика нагрузки изменены в определении задачи
Поэтому AWS создал собственный веб-сайт, чтобы устранить возможности этой ошибки:
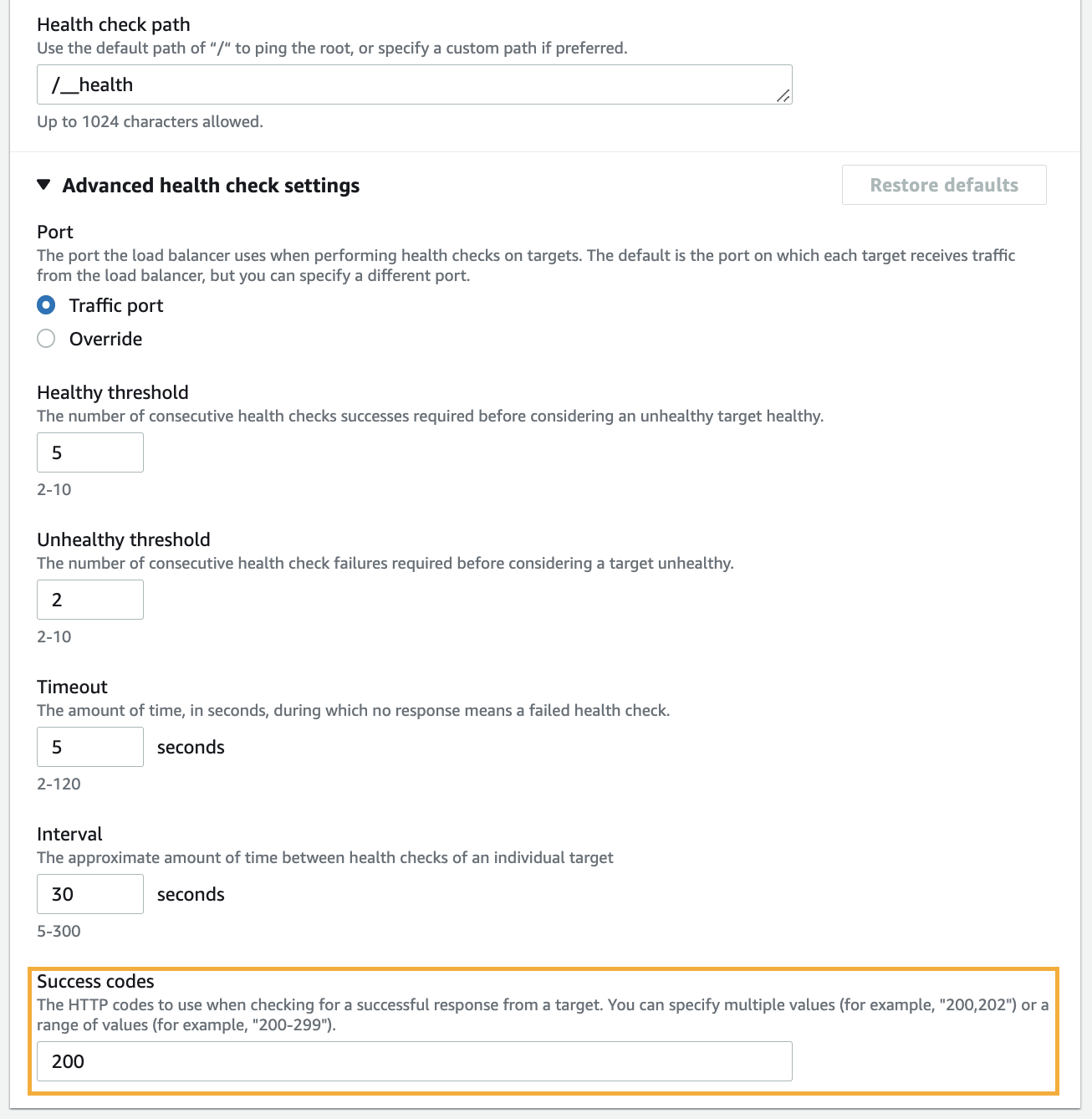
Изменить: в моем случае код проверки работоспособности моего приложения был другим. По умолчанию - 200, но вы также можете добавить диапазон, например 200–499.
Разрешите поделиться своим опытом.
В моем случае все было правильно, кроме хоста, на котором сервер слушает, это было
Я получил это сообщение об ошибке, потому что группа безопасности между службой ECS и целевой группой балансировщика нагрузки разрешала только трафик HTTP и HTTPS.
По-видимому, проверка работоспособности происходит через какой-то другой порт и / или протокол как обновление группы безопасности, чтобы разрешить весь трафик на всех портах (как предлагается на https://docs.aws.amazon.com/AmazonECS/latest/userguide/create-application-load-balancer.html) заставил проверку работоспособности работать.
У меня была такая же проблема. Мне удалось обойти проблему следующим образом:
- перейти к сервису EC2
- затем выберите Target Group на боковой панели
- выберите целевую группу для балансировщика нагрузки
- выберите вкладку проверки работоспособности
- убедитесь, что проверка работоспособности вашего инстанса EC2 такая же, как и проверка работоспособности в целевой группе. Это укажет вашему ELB направить свой трафик на эту конечную точку при проведении проверки работоспособности. В моем случае мой путь проверки работоспособности был /health.
В моем случае ECS Fargate организовал функциональность док-контейнера как сервис, а не как веб-приложение или API. Служба заключается в том, что она не прослушивает какой-либо порт (например: Расписание потребления сообщений кукурузы/ActiveMQ и т. д.).
Другими словами, это клиентский, а не серверный узел. Поэтому я заставил слушать локальный хост только для проверки работоспособности...
Все, что я добавил в целевую группу для проверки работоспособности —
И ниже код в index.ts -
import express from 'express';
const app = express();
const port = process.env.PORT || 8080;
//Health Check
app.get('/__health', (_, res) => res.send({ ok: 'yes' }));
app.listen(port, () => {
logger.info(`Health Check: Listening at http://localhost:${port}`);
});
В моем случае было приложение React, работающее в режиме FARGATE.
Первая проблема заключалась в том, что образ Docker был создан на основе NodeJS, «обслуживающего» его с помощью:
CMD npm run start # react-scripts start
Кроме того, это вообще не очень хорошая практика, она требует много ресурсов (4GB и 2vCPU было недостаточно), и из-за этого проверки не удавались. (в этой статье это упоминается как вероятная причина)
Чтобы решить предыдущую проблему, мы модифицируем образ как многоэтапную сборку с NodeJS для этапа сборки + NGINX для обслуживания контента. Локально это работало отлично, но мы не поняли, что порт по умолчанию для NGINX — 80, и вы не можете использовать другой порт хоста и контейнера на FARGATE с сетевым режимом awsvpc.
Чтобы устранить эту проблему, я запустил экземпляр EC2 с правильными группами безопасности для подключения к целям FARGATE на том же порту, на котором балансировщик нагрузки не смог выполнить проверку работоспособности. Я смог выполнить команды curl против других целей, но с этой неработоспособной целью (постоянно перерабатываемой) я получил мгновенный ответ об отказе в соединении . Это не был тайм-аут, который сказал мне, что цель не может обработать этот запрос, потому что она не слушает этот порт. Затем я понял, что мой контейнер ожидает трафика на порту 80, а мое приложение настроено для работы на порту 3xxx.
Решение здесь состояло в том, чтобы изменить конфигурацию NGINX по умолчанию для прослушивания нужного нам порта, перестроить образ и перезапустить службу.
Некоторые возможные решения для ECS
- Убедитесь, что входящий порт группы безопасности разрешен для трафика экземпляра ECS.
- Проверьте сеть контейнеров и сопоставление портов.
- Проверьте конечную точку проверки работоспособности целевой группы. это должно быть правильно и давать статус 200.
Как упомянул tschumann выше, проверьте группу безопасности вокруг кластера ECS. Если вы используете Terraform, разрешите доступ ко всем эфемерным портам докеров, как показано ниже:
resource "aws_security_group" "ecs_sg" {
name = "ecs_security_group"
vpc_id = "${data.aws_vpc.vpc.id}"
}
resource "aws_security_group_rule" "ingress_docker_ports" {
type = "ingress"
from_port = 32768
to_port = 61000
protocol = "-1"
cidr_blocks = ["${data.aws_vpc.vpc.cidr_block}"]
security_group_id = "${aws_security_group.ecs_sg.id}"
}
Я следил за предоставленными блогами aws, и мое исправление заключалось в том, что путь ping был неправильно настроен в LB относительно приложения.
https://docs.aws.amazon.com/AmazonECS/latest/userguide/troubleshoot-service-load-balancers.html
https://aws.amazon.com/premiumsupport/knowledge-center/ecs-fargate-health-check-failures/
В моем случае это было правило группы безопасности, которое разрешало подключения только с определенного IP-адреса, и это блокировало проверку работоспособности с LB. Я добавил cidr VPC в качестве еще одного правила в группу безопасности, и тогда это сработало.
У меня была такая же проблема с развертыванием приложения java springboot на ACS, работающем как фаргейт. Было 3 проблемы, которые мне пришлось решить, чтобы решить проблему, если это может помочь другим в будущем.
Контейнер работал на порту 8080 (из-за tomcat), поэтому ELB, целевая группа и две группы безопасности (одна с ELB и одна с ECS) должны разрешать 8080 в своих правилах входящего трафика. Также пришлось пересмотреть настройку задачи, чтобы изменить контейнер на карту на 8080.
Порт в разделе проверки работоспособности целевой группы (дополнительные настройки) должен был быть явно изменен на 8080 вместо 80 по умолчанию.
Мне пришлось создать фиктивный путь проверки работоспособности в приложении, потому что проверка связи с корнем приложения в «/» приводила к коду ошибки 302.
Надеюсь это поможет.
Если вы создаете конвейер с использованием Cloudformation, я рекомендую изменить 2 параметра в вашем шаблоне. Пример :
[Первый шаг] Тип: AWS::ECS::Service Свойства: HealthCheckGracePeriodSeconds: 60
[Второй шаг] TargetGroup: Тип: AWS::ElasticLoadBalancing::TargetGroup Свойства: Порт: !Ref ListenerContainerPort Протокол: TCP VpcId: !Ref VPCID TargetType: ip HealthCheckTimeoutSeconds: 40HealthCheckIntervalSeconds: 100
Когда ваше развертывание завершится успешно и задача остановит ошибку.
Решение частично верно в ответе « iravinandan », но в последней части вашего маршрутизатора nodejs просто добавьтеstatus(200)вот и все. Или вы можете установить свой личный статус, нажав на вкладку «Дополнительно» в конце страницы.
app.get('/__health', (request, response) => response.status(200).end(""));
Подробнее здесь: введите описание ссылки здесь
С уважением
Возможно, полезно для кого-то ... наш путь проверки работоспособности целевой группы был установлен, что для наших услуг указывало на Swagger и работало хорошо. После обновления для использования Springfox вместо ручного создания swagger.json,
/ теперь выполняет 302 редирект на
/swagger-ui.html, что привело к сбою проверки работоспособности. Поскольку это было для службы Spring Boot, мы просто указали путь проверки работоспособности в целевой группе на
/health вместо этого (страница состояния OOTB Spring).
Я также столкнулся с той же проблемой при использовании AWS Fargate.
Вот несколько возможных решений, которые можно попробовать:
- Сначала проверьте группу безопасности службы, к которой прикреплены правила исходящего и входящего трафика.
- Если вы используете Loadbalancer и указываете на целевую группу, вы должны включить порт контейнера Docker в группе безопасности и подключить входящий трафик только из группы безопасности ALB. 3) Также проверьте конечную точку проверки работоспособности, которую мы назначаем целевой группе. есть ли какие-либо зависимости, он должен возвращать только 200 статусных ответов / то, что мы указали в целевой группе
В моем случае моему сервису ECS Fargate не нужен балансировщик нагрузки, поэтому я удалил «Балансировщик нагрузки» и «Группу безопасности», после чего он заработал.