Почему нет пробного графика для этой модели двоичного классификатора DNN tf.estimator в тензорной доске?
Я использую tf.estimator API с TensorFlow 1.13 на платформе Google AI для создания двоичного классификатора DNN. По какой-то причине я не получаю eval график, но я получаю training граф.
Вот два разных метода выполнения тренировок. Первый - это обычный метод python, а второй - использование GCP AI Platform в локальном режиме.
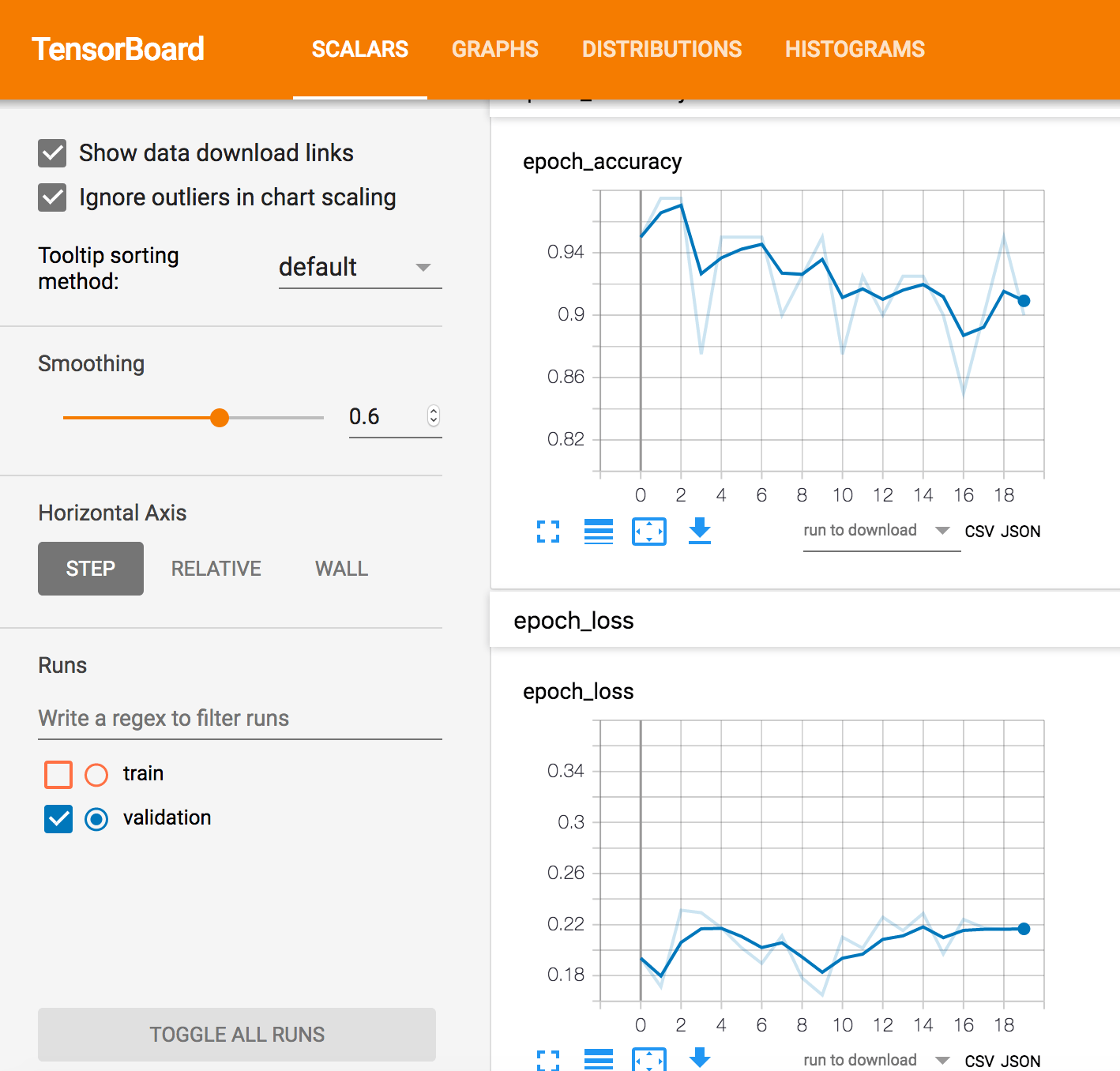
Обратите внимание, что в любом из методов оценка является просто точкой для того, что кажется конечным результатом. Я ожидал сюжет, похожий на тренировку, где это будет кривая.
Наконец, я показываю соответствующий код модели для метрики производительности.
Обычный метод записи на python:
%%bash
#echo ${PYTHONPATH}:${PWD}/${MODEL_NAME}
export PYTHONPATH=${PYTHONPATH}:${PWD}/${MODEL_NAME}
python -m trainer.task \
--train_data_paths="${PWD}/samples/train_sounds*" \
--eval_data_paths=${PWD}/samples/valid_sounds.csv \
--output_dir=${PWD}/${TRAINING_DIR} \
--hidden_units="175" \
--train_steps=5000 --job-dir=./tmp
Метод локальной платформы gcloud (GCP):
%%bash
OUTPUT_DIR=${PWD}/${TRAINING_DIR}
echo "OUTPUT_DIR=${OUTPUT_DIR}"
echo "train_data_paths=${PWD}/${TRAINING_DATA_DIR}/train_sounds*"
gcloud ai-platform local train \
--module-name=trainer.task \
--package-path=${PWD}/${MODEL_NAME}/trainer \
-- \
--train_data_paths="${PWD}/${TRAINING_DATA_DIR}/train_sounds*" \
--eval_data_paths=${PWD}/${TRAINING_DATA_DIR}/valid_sounds.csv \
--hidden_units="175" \
--train_steps=5000 \
--output_dir=${OUTPUT_DIR}
Код метрики производительности
estimator = tf.contrib.estimator.add_metrics(estimator, my_auc)
А также
# This is from the tensorflow website for adding metrics for a DNNClassifier
# https://www.tensorflow.org/api_docs/python/tf/metrics/auc
def my_auc(features, labels, predictions):
return {
#'auc': tf.metrics.auc( labels, predictions['logistic'], weights=features['weight'])
#'auc': tf.metrics.auc( labels, predictions['logistic'], weights=features[LABEL])
# 'auc': tf.metrics.auc( labels, predictions['logistic'])
'auc': tf.metrics.auc( labels, predictions['class_ids']),
'accuracy': tf.metrics.accuracy( labels, predictions['class_ids'])
}
Метод, используемый во время обучения и оценки
eval_spec = tf.estimator.EvalSpec(
input_fn = read_dataset(
filename = args['eval_data_paths'],
mode = tf.estimator.ModeKeys.EVAL,
batch_size = args['eval_batch_size']),
steps=100,
throttle_secs=10,
exporters = exporter)
# addition of throttle_secs=10 above and this
# below as a result of one of the suggested answers.
# The result is that these mods do no print the final
# evaluation graph much less the intermediate results
tf.estimator.RunConfig(save_checkpoints_steps=10)
tf.estimator.train_and_evaluate(estimator, train_spec, eval_spec)
Бинарный классификатор DNN, использующий tf.estimator
estimator = tf.estimator.DNNClassifier(
model_dir = model_dir,
feature_columns = final_columns,
hidden_units=hidden_units,
n_classes=2)
Скриншот файла в каталоге model_trained/eval.
Только этот один файл находится в этом каталоге. Он называется model_trained/eval/events.out.tfevents.1561296248.myhostname.local и выглядит как
2 ответа
С комментариями и предложениями, а также настройкой параметров, вот результат, который работает для меня.
Код для запуска тензорной доски, тренировки модели и т. Д. Использование ------- для обозначения ячейки ноутбука
%%bash
# clean model output dirs
# This is so that the trained model is deleted
output_dir=${PWD}/${TRAINING_DIR}
echo ${output_dir}
rm -rf ${output_dir}
# start tensorboard
def tb(logdir="logs", port=6006, open_tab=True, sleep=2):
import subprocess
proc = subprocess.Popen(
"exec " + "tensorboard --logdir={0} --port={1}".format(logdir, port), shell=True)
if open_tab:
import time
time.sleep(sleep)
import webbrowser
webbrowser.open("http://127.0.0.1:{}/".format(port))
return proc
cwd = os.getcwd()
output_dir=cwd + '/' + TRAINING_DIR
print(output_dir)
server1 = tb(logdir=output_dir)
%%bash
# The model run config is hard coded to checkpoint every 500 steps
#
#echo ${PYTHONPATH}:${PWD}/${MODEL_NAME}
export PYTHONPATH=${PYTHONPATH}:${PWD}/${MODEL_NAME}
python -m trainer.task \
--train_data_paths="${PWD}/samples/train_sounds*" \
--eval_data_paths=${PWD}/samples/valid_sounds.csv \
--output_dir=${PWD}/${TRAINING_DIR} \
--hidden_units="175" \
--train_batch_size=10 \
--eval_batch_size=100 \
--eval_steps=1000 \
--min_eval_frequency=15 \
--train_steps=20000 --job-dir=./tmp
Соответствующий код модели
# This hard codes the checkpoints to be
# every 500 training steps?
estimator = tf.estimator.DNNClassifier(
model_dir = model_dir,
feature_columns = final_columns,
hidden_units=hidden_units,
config=tf.estimator.RunConfig(save_checkpoints_steps=500),
n_classes=2)
# trainspec to tell the estimator how to get training data
train_spec = tf.estimator.TrainSpec(
input_fn = read_dataset(
filename = args['train_data_paths'],
mode = tf.estimator.ModeKeys.TRAIN, # make sure you use the dataset api
batch_size = args['train_batch_size']),
max_steps = args['train_steps']) # max_steps allows a resume
exporter = tf.estimator.LatestExporter(name = 'exporter',
serving_input_receiver_fn = serving_input_fn)
eval_spec = tf.estimator.EvalSpec(
input_fn = read_dataset(
filename = args['eval_data_paths'],
mode = tf.estimator.ModeKeys.EVAL,
batch_size = args['eval_batch_size']),
steps=args['eval_steps'],
throttle_secs = args['min_eval_frequency'],
exporters = exporter)
tf.estimator.train_and_evaluate(estimator, train_spec, eval_spec)
Результирующие графики
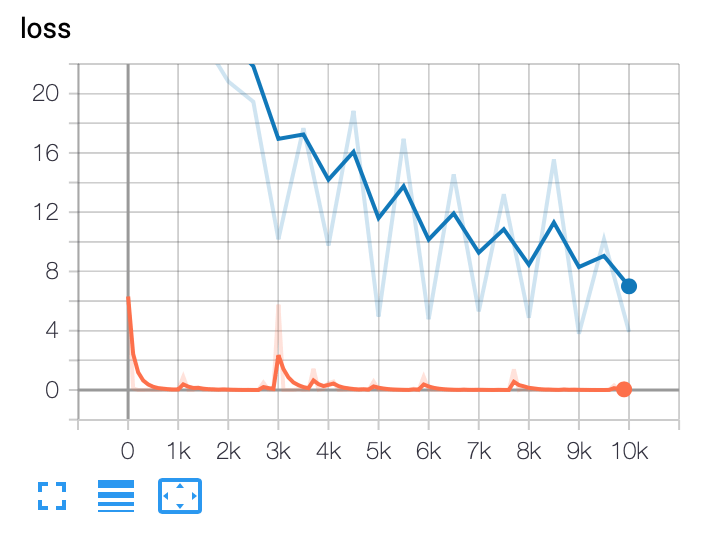
В estimator.train_and_evaluate() вы указываете train_spec и eval_spec, eval_spec часто имеет другую функцию ввода (например, набор данных оценки развития, без перемешивания)
Каждые N шагов, контрольная точка из процесса поезда сохраняется, и процесс eval загружает те же веса и работает в соответствии с eval_spec, Эти итоговые итоги заносятся в журнал под номером шага контрольной точки, поэтому вы можете сравнивать результаты теста с тестом.
В вашем случае оценка выдает только одну точку на графике для каждого вызова для оценки. Эта точка содержит среднее значение за весь оценочный вызов. Взгляните на эту похожую проблему:
Я бы изменил tf.estimator.EvalSpec с участием throttle_secs небольшое значение (по умолчанию 600) и save_checkpoints_steps в tf.estimator.RunConfig к небольшому значению:
tf.estimator.RunConfig(save_checkpoints_steps=SOME_SMALL_VALUE_TO_VERIFY)