Кластеризация 500000 геопространственных точек в питоне
В настоящее время я сталкиваюсь с проблемой поиска способа объединения около 500000 пар широта / долгота в python. До сих пор я пытался вычислить матрицу расстояний с помощью numpy (чтобы перейти к DBSCAN для обучения по науке), но при таком большом входе он быстро выдает ошибку памяти.
Точки хранятся в кортежах, содержащих широту, долготу и значение данных в этой точке.
Короче говоря, каков наиболее эффективный способ пространственной кластеризации большого количества пар широта / долгота в python? Для этого приложения я готов пожертвовать некоторой точностью во имя скорости.
Изменить: Количество кластеров для алгоритма, чтобы найти неизвестно заранее.
2 ответа
У меня нет ваших данных, поэтому я просто сгенерировал 500 тысяч случайных чисел в три столбца.
import numpy as np
import matplotlib.pyplot as plt
from scipy.cluster.vq import kmeans2, whiten
arr = np.random.randn(500000*3).reshape((500000, 3))
x, y = kmeans2(whiten(arr), 7, iter = 20) #<--- I randomly picked 7 clusters
plt.scatter(arr[:,0], arr[:,1], c=y, alpha=0.33333);
out[1]:
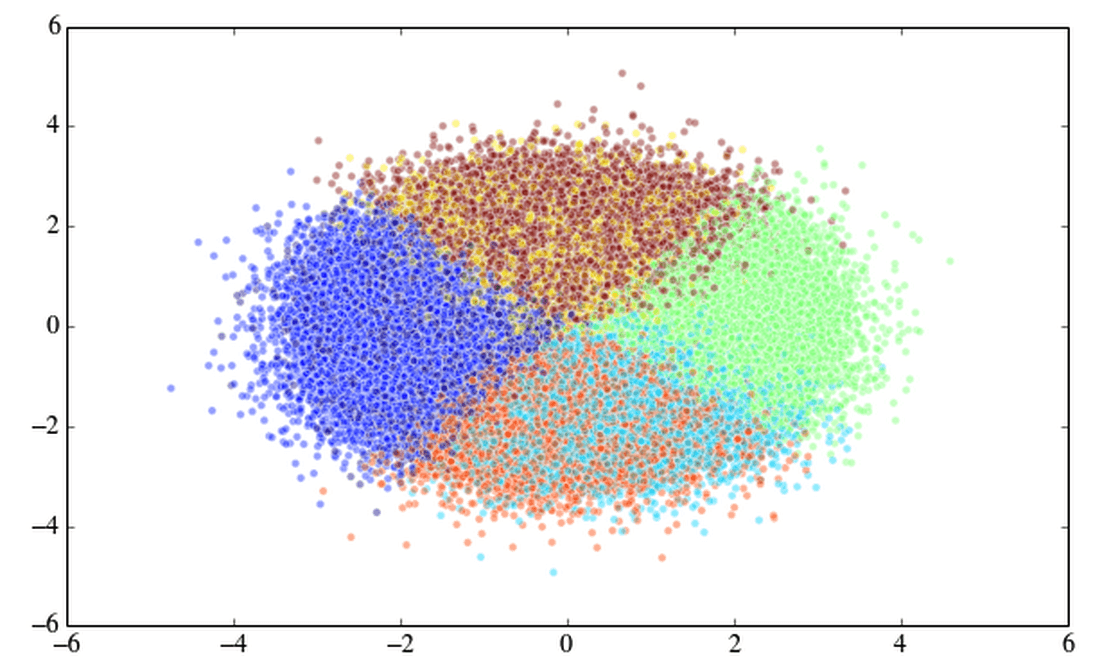
Я рассчитал это, и потребовалось 1,96 секунды для запуска этого Kmeans2, поэтому я не думаю, что это связано с размером ваших данных. Поместите ваши данные в массив 500000 x 3 и попробуйте kmeans2.
Более старые версии DBSCAN в scikit learn рассчитывают полную матрицу расстояний.
К сожалению, для вычисления матрицы расстояний O(n^2) памяти, и это, вероятно, где у вас заканчивается память.
Более новые версии (какую версию вы используете?) Scikit Learn должны работать без матрицы расстояний; по крайней мере, при использовании индекса. На 500.000 объектов вы хотите использовать ускорение индекса, так как это сокращает время выполнения с O(n^2) в O(n log n),
Я не знаю, насколько хорошо Scikit Learn поддерживает геодезическое расстояние в своих индексах. ELKI - единственный известный мне инструмент, который может использовать индексы R*-дерева для ускорения геодезического расстояния; сделать это очень быстро для этой задачи (в частности, при массовой загрузке индекса). Вы должны попробовать.
Взгляните на документацию по индексированию Scikit Learn и попробуйте установить algorithm='ball_tree',