Spark Python Pyspark Как сгладить столбец с помощью массива словарей и встроенных словарей (вывод аннотатора sparknlp)
Я пытаюсь извлечь вывод из sparknlp (используя Pretrained Pipeline 'объяснение_document_dl'). Я потратил много времени в поисках путей (UDF, взрыва и т. Д.), Но не могу приблизиться к работоспособному решению. Скажем, я хочу получить значения экстракта под result а также metadata из колонны entities, В этом столбце есть массив, содержащий несколько словарей
Когда я использую df.withColumn("entity_name", explode("entities.result")), извлекается только значение из первого словаря.
Содержимое столбца "сущности" представляет собой список словарей.
Попытка предоставить воспроизводимый пример / заново создать фрейм данных (благодаря предложению, предоставленному @jonathan ниже):
# content of one cell as an example:
d = [{"annotatorType":"chunk","begin":2740,"end":2747,"result":"•Ability","metadata":{"entity":"ORG","sentence":"8","chunk":"22"},"embeddings":[],"sentence_embeddings":[]}, {"annotatorType":"chunk","begin":2740,"end":2747,"result":"Fedex","metadata":{"entity":"ORG","sentence":"8","chunk":"22"},"embeddings":[],"sentence_embeddings":[]}]
from pyspark.sql.types import StructType, StructField, StringType
from array import array
schema = StructType([StructField('annotatorType', StringType(), True),
StructField('begin', IntegerType(), True),
StructField('end', IntegerType(), True),
StructField('result', StringType(), True),
StructField('sentence', StringType(), True),
StructField('chunk', StringType(), True),
StructField('metadata', StructType((StructField('entity', StringType(), True),
StructField('sentence', StringType(), True),
StructField('chunk', StringType(), True)
)), True),
StructField('embeddings', StringType(), True),
StructField('sentence_embeddings', StringType(), True)
]
)
df = spark.createDataFrame(d, schema=schema)
df.show()
В этом случае единый список словаря, это работает:
+-------------+-----+----+--------+--------+-----+------------+----------+-------------------+
|annotatorType|begin| end| result|sentence|chunk| metadata|embeddings|sentence_embeddings|
+-------------+-----+----+--------+--------+-----+------------+----------+-------------------+
| chunk| 2740|2747|•Ability| null| null|[ORG, 8, 22]| []| []|
| chunk| 2740|2747| Fedex| null| null|[ORG, 8, 22]| []| []|
+-------------+-----+----+--------+--------+-----+------------+----------+-------------------+
Но я застрял на том, как применить это к столбцу, который содержит несколько ячеек с массивом из нескольких словарей (таким образом, несколько строк в исходной ячейке).
Я пытался применить ту же схему к entities столбец, и мне пришлось сначала преобразовать столбец в json.
ent1 = ent1.withColumn("entities2", to_json("entities"))
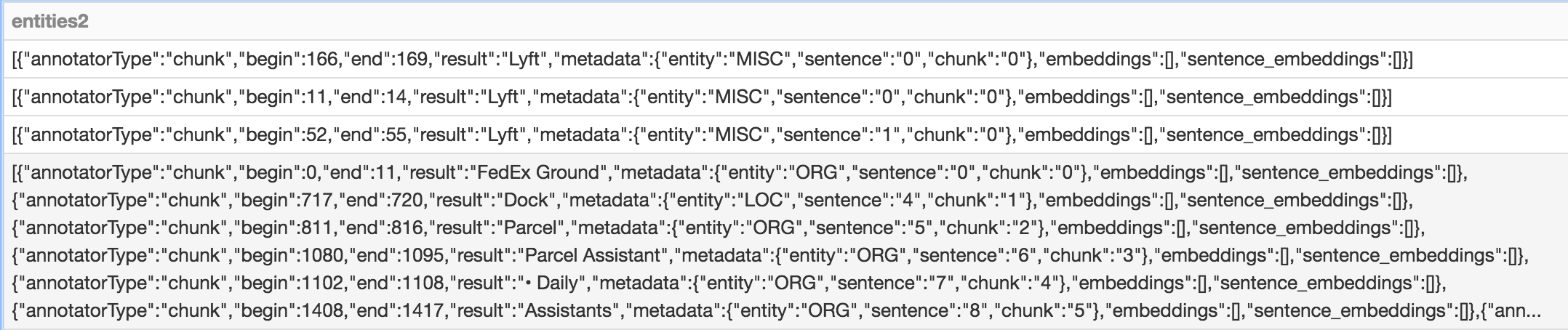
Работает для ячеек с массивом из 1 словаря, но дает null к ячейкам, имеющим массив из нескольких словарей (4-я строка):
ent1.withColumn("entities2", from_json("entities2", schema)).select("entities2.*").show()
+-------------+-----+----+------+--------+-----+------------+----------+-------------------+
|annotatorType|begin| end|result|sentence|chunk| metadata|embeddings|sentence_embeddings|
+-------------+-----+----+------+--------+-----+------------+----------+-------------------+
| chunk| 166| 169| Lyft| null| null|[MISC, 0, 0]| []| []|
| chunk| 11| 14| Lyft| null| null|[MISC, 0, 0]| []| []|
| chunk| 52| 55| Lyft| null| null|[MISC, 1, 0]| []| []|
| null| null|null| null| null| null| null| null| null|
+-------------+-----+----+------+--------+-----+------------+----------+-------------------+
Желаемый результат
+-------------+-----+----+----------------+------------------------+----------+-------------------+
|annotatorType|begin| end| result | metadata |embeddings|sentence_embeddings|
+-------------+-----+----+----------------+------------------------+----------+-------------------+
| chunk| 166| 169|Lyft |[MISC] | []| []|
| chunk| 11| 14|Lyft |[MISC] | []| []|
| chunk| 52| 55|Lyft. |[MISC] | []| []|
| chunk| [..]|[..]|[Lyft,Lyft, |[MISC,MISC,MISC, | []| []|
| | | |FedEx Ground..] |ORG,LOC,ORG,ORG,ORG,ORG]| | |
+-------------+-----+----+----------------+------------------------+----------+-------------------+
Я также попытался преобразовать в json для каждой строки, но я потерял след оригинальной строки, и мне дали льстивого сына:
new_df = sqlContext.read.json(ent2.rdd.map(lambda r: r.entities2))
new_df.show()
+-------------+-----+----------+----+------------+----------------+-------------------+
|annotatorType|begin|embeddings| end| metadata| result|sentence_embeddings|
+-------------+-----+----------+----+------------+----------------+-------------------+
| chunk| 166| []| 169|[0, MISC, 0]| Lyft| []|
| chunk| 11| []| 14|[0, MISC, 0]| Lyft| []|
| chunk| 52| []| 55|[0, MISC, 1]| Lyft| []|
| chunk| 0| []| 11| [0, ORG, 0]| FedEx Ground| []|
| chunk| 717| []| 720| [1, LOC, 4]| Dock| []|
| chunk| 811| []| 816| [2, ORG, 5]| Parcel| []|
| chunk| 1080| []|1095| [3, ORG, 6]|Parcel Assistant| []|
| chunk| 1102| []|1108| [4, ORG, 7]| • Daily| []|
| chunk| 1408| []|1417| [5, ORG, 8]| Assistants| []|
+-------------+-----+----------+----+------------+----------------+-------------------+
Я попытался применить UDF, чтобы просмотреть список массивов внутри "сущностей":
def flatten(my_dict):
d_result = defaultdict(list)
for sub in my_dict:
val = sub['result']
d_result["result"].append(val)
return d_result["result"]
ent = ent.withColumn('result', flatten(df.entities))
TypeError: Column is not iterable
Я нашел этот пост Apache Spark Read JSON с дополнительными столбцами, очень похожими на мою проблему, но после преобразования столбца entities Я все еще не могу решить это с помощью решений, представленных в этом посте.
Любая помощь приветствуется! Идеально решения в Python, но примеры в Scala тоже полезны!
1 ответ
Причина получения null потому что schema переменная не точно представляет список словарей, которые вы передаете в качестве данных
from pyspark.shell import *
from pyspark.sql.types import *
schema = StructType([StructField('result', StringType(), True),
StructField('metadata', StructType((StructField('entity', StringType(), True),
StructField('sentence', StringType(), True),
StructField('chunk', StringType(), True))), True)])
df = spark.createDataFrame(d1, schema=schema)
df.show()
Если вы предпочитаете индивидуальное решение, вы можете попробовать чистый подход Python / Pandas
import pandas as pd
from pyspark.shell import *
result = []
metadata_entity = []
for row in d1:
result.append(row.get('result'))
metadata_entity.append(row.get('metadata').get('entity'))
schema = {'result': [result], 'metadata.entity': [metadata_entity]}
pandas_df = pd.DataFrame(schema)
df = spark.createDataFrame(pandas_df)
df.show()
# specific columns
df.select('result','metadata.entity').show()
РЕДАКТИРОВАТЬ
ИМХО после прочтения всех подходов, которые вы пытались, я думаю, sc.parallelize все еще делает трюк для довольно сложных случаев. У меня нет вашей исходной переменной, но я могу распознать ваше изображение и взять его оттуда - хотя уже нет классных учителей или учебных указаний. Надеюсь, что для всего этого будет полезно.
Вы всегда можете создать фиктивный фрейм данных с нужной вам структурой и получить ее схему
Для сложных случаев с вложенными типами данных вы можете использовать SparkContext и прочитать полученный формат JSON
import itertools
from pyspark.shell import *
from pyspark.sql.functions import *
from pyspark.sql.types import *
# assume two lists in two dictionary keys to make four cells
# since I don't have but entities2, I can just replicate it
sample = {
'single_list': [{'annotatorType': 'chunk', 'begin': '166', 'end': '169', 'result': 'Lyft',
'metadata': {'entity': 'MISC', 'sentence': '0', 'chunk': '0'}, 'embeddings': [],
'sentence_embeddings': []},
{'annotatorType': 'chunk', 'begin': '11', 'end': '14', 'result': 'Lyft',
'metadata': {'entity': 'MISC', 'sentence': '0', 'chunk': '0'}, 'embeddings': [],
'sentence_embeddings': []},
{'annotatorType': 'chunk', 'begin': '52', 'end': '55', 'result': 'Lyft',
'metadata': {'entity': 'MISC', 'sentence': '1', 'chunk': '0'}, 'embeddings': [],
'sentence_embeddings': []}],
'frankenstein': [
{'annotatorType': 'chunk', 'begin': '0', 'end': '11', 'result': 'FedEx Ground',
'metadata': {'entity': 'ORG', 'sentence': '0', 'chunk': '0'}, 'embeddings': [],
'sentence_embeddings': []},
{'annotatorType': 'chunk', 'begin': '717', 'end': '720', 'result': 'Dock',
'metadata': {'entity': 'LOC', 'sentence': '4', 'chunk': '1'}, 'embeddings': [],
'sentence_embeddings': []},
{'annotatorType': 'chunk', 'begin': '811', 'end': '816', 'result': 'Parcel',
'metadata': {'entity': 'ORG', 'sentence': '5', 'chunk': '2'}, 'embeddings': [],
'sentence_embeddings': []},
{'annotatorType': 'chunk', 'begin': '1080', 'end': '1095', 'result': 'Parcel Assistant',
'metadata': {'entity': 'ORG', 'sentence': '6', 'chunk': '3'}, 'embeddings': [],
'sentence_embeddings': []},
{'annotatorType': 'chunk', 'begin': '1102', 'end': '1108', 'result': '* Daily',
'metadata': {'entity': 'ORG', 'sentence': '7', 'chunk': '4'}, 'embeddings': [],
'sentence_embeddings': []},
{'annotatorType': 'chunk', 'begin': '1408', 'end': '1417', 'result': 'Assistants',
'metadata': {'entity': 'ORG', 'sentence': '8', 'chunk': '5'}, 'embeddings': [],
'sentence_embeddings': []}]
}
# since they are structurally different, get two dataframes
df_single_list = spark.read.json(sc.parallelize(sample.get('single_list')))
df_frankenstein = spark.read.json(sc.parallelize(sample.get('frankenstein')))
# print better the table first border
print('\n')
# list to create a dataframe schema
annotatorType = []
begin = []
embeddings = []
end = []
metadata = []
result = []
sentence_embeddings = []
# PEP8 here to have an UDF instead of lambdas
# probably a dictionary with actions to avoid IF statements
function_metadata = lambda x: [x.entity]
for k, i in enumerate(df_frankenstein.columns):
if i == 'annotatorType':
annotatorType.append(df_frankenstein.select(i).rdd.flatMap(lambda x: x).collect())
if i == 'begin':
begin.append(df_frankenstein.select(i).rdd.flatMap(lambda x: x).collect())
if i == 'embeddings':
embeddings.append(df_frankenstein.select(i).rdd.flatMap(lambda x: x).collect())
if i == 'end':
end.append(df_frankenstein.select(i).rdd.flatMap(lambda x: x).collect())
if i == 'metadata':
_temp = list(map(function_metadata, df_frankenstein.select(i).rdd.flatMap(lambda x: x).collect()))
metadata.append(list(itertools.chain.from_iterable(_temp)))
if i == 'result':
result.append(df_frankenstein.select(i).rdd.flatMap(lambda x: x).collect())
if i == 'sentence_embeddings':
sentence_embeddings.append(df_frankenstein.select(i).rdd.flatMap(lambda x: x).collect())
# headers
annotatorType_header = 'annotatorType'
begin_header = 'begin'
embeddings_header = 'embeddings'
end_header = 'end'
metadata_header = 'metadata'
result_header = 'result'
sentence_embeddings_header = 'sentence_embeddings'
metadata_entity_header = 'metadata.entity'
frankenstein_schema = StructType(
[StructField(annotatorType_header, ArrayType(StringType())),
StructField(begin_header, ArrayType(StringType())),
StructField(embeddings_header, ArrayType(StringType())),
StructField(end_header, ArrayType(StringType())),
StructField(metadata_header, ArrayType(StringType())),
StructField(result_header, ArrayType(StringType())),
StructField(sentence_embeddings_header, ArrayType(StringType()))
])
# list of lists of lists of lists of ... lists
frankenstein_list = [[annotatorType, begin, embeddings, end, metadata, result, sentence_embeddings]]
df_frankenstein = spark.createDataFrame(frankenstein_list, schema=frankenstein_schema)
print(df_single_list.schema)
print(df_frankenstein.schema)
# let's see how it is
df_single_list.select(
annotatorType_header,
begin_header,
end_header,
result_header,
array(metadata_entity_header),
embeddings_header,
sentence_embeddings_header).show()
# let's see again
df_frankenstein.select(
annotatorType_header,
begin_header,
end_header,
result_header,
metadata_header,
embeddings_header,
sentence_embeddings_header).show()
Выход:
StructType(List(StructField(annotatorType,StringType,true),StructField(begin,StringType,true),StructField(embeddings,ArrayType(StringType,true),true),StructField(end,StringType,true),StructField(metadata,StructType(List(StructField(chunk,StringType,true),StructField(entity,StringType,true),StructField(sentence,StringType,true))),true),StructField(result,StringType,true),StructField(sentence_embeddings,ArrayType(StringType,true),true)))
StructType(List(StructField(annotatorType,ArrayType(StringType,true),true),StructField(begin,ArrayType(StringType,true),true),StructField(embeddings,ArrayType(StringType,true),true),StructField(end,ArrayType(StringType,true),true),StructField(metadata,ArrayType(StringType,true),true),StructField(result,ArrayType(StringType,true),true),StructField(sentence_embeddings,ArrayType(StringType,true),true)))
+-------------+-----+---+------+----------------------+----------+-------------------+
|annotatorType|begin|end|result|array(metadata.entity)|embeddings|sentence_embeddings|
+-------------+-----+---+------+----------------------+----------+-------------------+
| chunk| 166|169| Lyft| [MISC]| []| []|
| chunk| 11| 14| Lyft| [MISC]| []| []|
| chunk| 52| 55| Lyft| [MISC]| []| []|
+-------------+-----+---+------+----------------------+----------+-------------------+
+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+
| annotatorType| begin| end| result| metadata| embeddings| sentence_embeddings|
+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+
|[[chunk, chunk, c...|[[0, 717, 811, 10...|[[11, 720, 816, 1...|[[FedEx Ground, D...|[[ORG, LOC, ORG, ...|[[[], [], [], [],...|[[[], [], [], [],...|
+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+
Вам придется выбирать из каждого фрейма данных отдельно, так как они различаются по типам данных, но контент готов (если я понял ваше требование по выводу) для использования
( ͡° ͜ʖ ͡°)