В чем разница между очередями таблиц, использующих формат Delta с Pyspark-SQL, и Pyspark?
Я запрашиваю таблицы, но у меня разные результаты, используя два способа, я хотел бы понять причину.
Я создал таблицу, используя местоположение Delta. Я хочу запросить данные, которые я сохранил в этом месте. Я использую Amazon S3.
Я создал таблицу следующим образом:
spark.sql("CREATE TABLE bronze_client_trackingcampaigns.TRACKING_BOUNCES (ClientID INT, SendID INT, SubscriberKey STRING) USING DELTA LOCATION 's3://example/bronze/client/trackingcampaigns/TRACKING_BOUNCES/delta'")
Я хочу запросить данные, используя следующую строку:
spark.sql("SELECT count(*) FROM bronze_client_trackingcampaigns.TRACKING_BOUNCES")
Но результаты не в порядке, это должно быть 41832, но он возвращает 1.
Когда я сделал тот же запрос другим способом:
spark.read.option("header", True).option("inferSchema", True).format("delta").table("bronze_client_trackingcampaigns.TRACKING_BOUNCES").count()
Я получил результат 41832.
Мои текущие результаты:
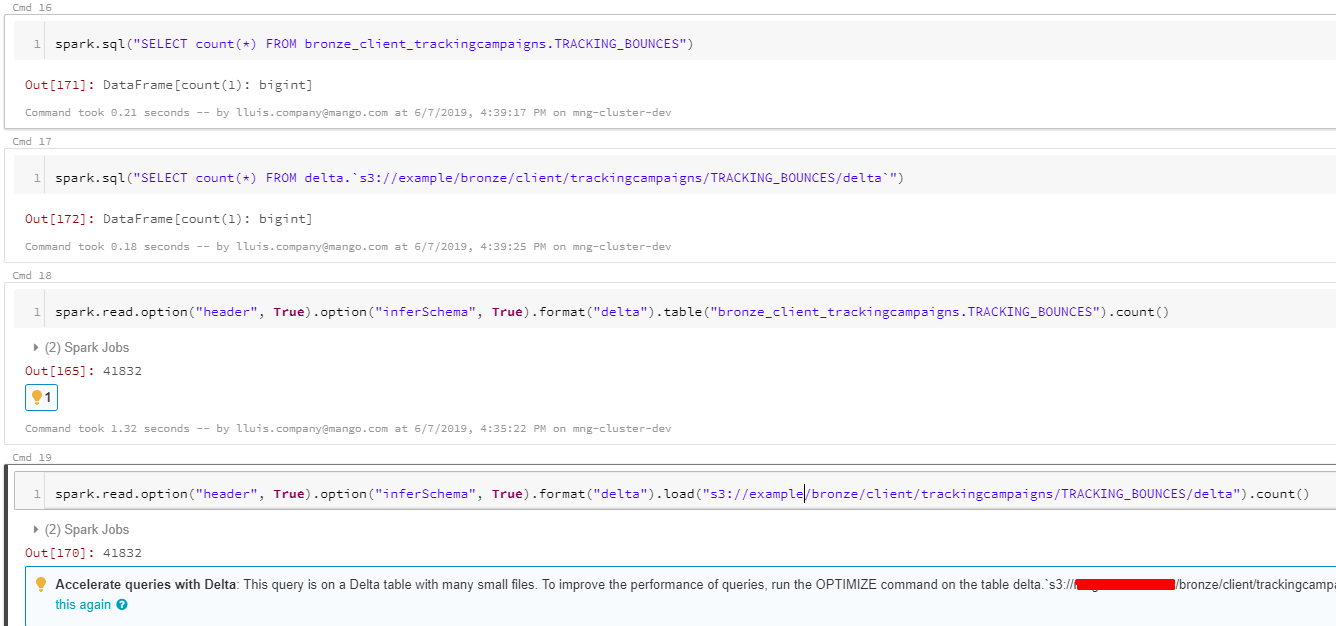
Я хочу получить одинаковые результаты в обоих направлениях.
1 ответ
Решение
Возвращаемое вами 1 - это количество строк, а не фактический результат. Измените оператор SQL на:
df = spark.sql("SELECT COUNT(*) FROM bronze_client_trackingcampaigns.TRACKING_BOUNCES")
df.show()
Теперь вы должны получить тот же результат.