Обойти теги em при извлечении содержимого имени класса с помощью селектора Parsel
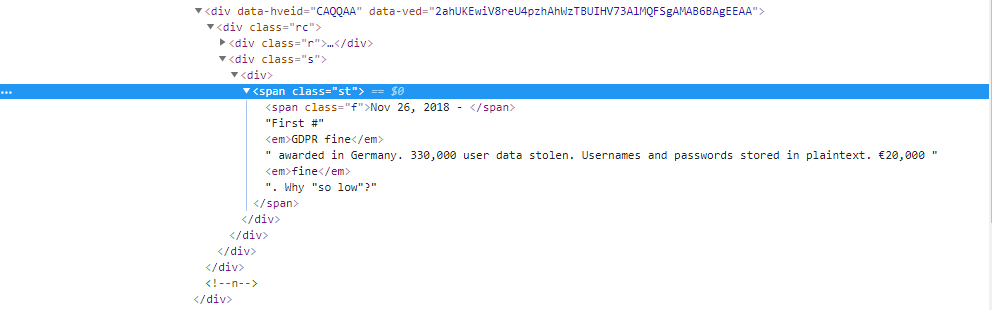
Я пытаюсь извлечь содержимое имени класса. Как извлечь все содержимое, включая содержимое тегов "em" и после тегов "em"? Смотрите картинку ниже:
 Я попробовал следующее, и это были результаты:
Я попробовал следующее, и это были результаты:
Испытание 1:
driver = webdriver.Chrome(options=options)
sel = Selector(text = driver.page_source)
sel.xpath("//*[@class ='st']").extract()
Выход 1:
>> <span class="st"><span class="f">Nov 26, 2018 - </span>First #<em>GDPR fine</em> awarded in Germany. 330,000 user data stolen. Usernames and passwords stored in plaintext. €20,000 <em>fine</em>. Why "so low"?</span>
Испытание 2:
driver = webdriver.Chrome(options=options)
sel = Selector(text = driver.page_source)
sel.xpath("//*[@class ='st']/text()").extract()
Выход 2:
>> First #
В идеале вывод, который я хочу получить:
>> Nov 26, 2018 - First #GDPR fine awarded in Germany. 330,000 user data stolen. Usernames and passwords stored in plaintext. €20,000 fine. Why "so low"?
1 ответ
Решение
В конце концов я нашел способ решить проблему, хотя и не изящный, но все равно приветствовал бы более элегантное решение.
Я вытащил содержимое имени класса, используя:
driver = webdriver.Chrome(options=options)
sel = Selector(text = driver.page_source)
content = sel.xpath("//*[@class ='st']").extract()
Затем я определил функцию, которая удалила html из текста:
import html.parser
class HTMLTextExtractor(html.parser.HTMLParser):
def __init__(self):
super(HTMLTextExtractor, self).__init__()
self.result = [ ]
def handle_data(self, d):
self.result.append(d)
def get_text(self):
return ''.join(self.result)
def html_to_text(html):
s = HTMLTextExtractor()
s.feed(html)
return s.get_text()
Перебирая содержимое списка и удаляя по одному html, я получил желаемый результат:
m = []
for w in content:
z = html_to_text(w)
m.append(z)