Прочитать конкретное значение на основе имени метки из PDF в C#
У меня есть asp.net Core 2.0 C# приложение, которое читает / анализирует файл PDF и получает текст. В этом я хочу прочитать конкретные значения, которые имеют конкретное имя метки. Вы можете увидеть изображение ниже, я хочу получить значение 171857 который Invoice номер и сохранить его в базе данных. 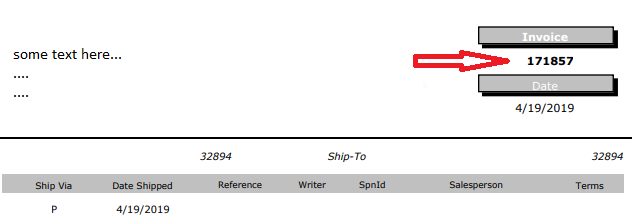
Я попробовал ниже код, чтобы прочитать PDF с помощью iTextSharp,
using (PdfReader reader = new PdfReader(fileName))
{
StringBuilder sb = new StringBuilder();
ITextExtractionStrategy strategy = new SimpleTextExtractionStrategy();
for (int page = 0; page < reader.NumberOfPages; page++)
{
string text = PdfTextExtractor.GetTextFromPage(reader, page + 1, strategy);
if (!string.IsNullOrWhiteSpace(text))
{
sb.Append(Encoding.UTF8.GetString(ASCIIEncoding.Convert(Encoding.Default, Encoding.UTF8, Encoding.Default.GetBytes(text))));
}
}
var pdfText = sb.ToString();
}
В pdfText Переменная Я получу весь текстовый контент из PDF, но кажется, что это не правильный способ получить номер счета. Есть ли другой способ прочитать конкретный контент из pdf по имени ярлыка, как мы предоставим название ярлыка Invoice и он вернет значение 171857 как пример с другими сторонними библиотеками для чтения PDF?
Любая помощь или предложения будут высоко оценены.
Спасибо
0 ответов
Я помог другу извлечь аналогичное значение из счета в формате PDF, созданного дугой Excel. Для этого ответа я создал счет в Excel и распечатал его в виде файла PDF и заархивировал его для загрузки в целях тестирования.
Следующее, что я делаю, я использую бесплатную библиотеку с открытым исходным кодом под названием PDFClown. Вот пакет nuget для этого.
Пока все хорошо, я сканировал весь PDF-документ (например, счет-фактура может быть одной страницей или несколькими страницами), добавляя каждое содержимое в список строк.
На следующем шаге я нахожу индекс (индекс номера счета-фактуры может быть в 10-м элементе в списке, в нашем случае это индекс 1), который относится к стоимости счета-фактуры, которую я назову Tag или Label.
Следовательно, у меня нет вашего файла pdf, я импровизировал и добавил уникальный тег под названием (или любым другим именем) "СЧЕТ-ФАКТУРА". Номер счета в этом случае идет после тега счета-фактуры. Итак, я нахожу индекс тега "INVOICE" и добавляю 1 для индексации, потому что номер счета-фактуры следует за тегом invoice. Таким образом, в данном случае я выберу текст счета-фактуры 0005 и верну его как значение 5. Таким образом, вы можете получить каждый текст / значение, за которым следует любой тег, отсканированный в нашем списке, и вернуть его нужным вам способом.
Поэтому вам нужно немного поиграть с ним, чтобы он на 100% соответствовал вашему PDF-файлу.
Итак, вот мои тестовые файлы Excel и Pdf в архиве. Загрузите его для теста.
Вот код:
public class InvoiceTextExtraction
{
private List<string> _contentList;
public void GetValueFromPdf()
{
_contentList = new List<string>();
CreatePdfContent(@"C:\temp\Invoice1.pdf");
var index = _contentList.FindIndex(e => e == "INVOICE") + 1;
int.TryParse(_contentList[index], out var value);
Console.WriteLine(value);
}
public void CreatePdfContent(string filePath)
{
using (var file = new File(filePath))
{
var document = file.Document;
foreach (var page in document.Pages)
{
Extract(new ContentScanner(page));
}
}
}
private void Extract(ContentScanner level)
{
if (level == null)
return;
while (level.MoveNext())
{
var content = level.Current;
switch (content)
{
case ShowText text:
{
var font = level.State.Font;
_contentList.Add(font.Decode(text.Text));
break;
}
case Text _:
case ContainerObject _:
Extract(level.ChildLevel);
break;
}
}
}
}
Ввод извлечен из файла pdf. Сканирование кода возвращает следующие элементы:
INVOICE
0005
PAYMENT DUE BY:
4/19/2019
.etc
.
.
.
Tax
USD TOTAL
171857
18 september 2019
и вот результат
5
Код основан на этой ссылке.
Предполагается, что метка накладной и номер накладной встроены как текст в PDF, а не как растровое изображение.
Один из способов сделать это - использовать Spire.PDF и извлечь местоположение метки, а затем найти число, написанное прямо под этим местоположением. Это будет относительно просто, если у вас есть одинаковый шаблон для всех PDF-файлов, которые вы хотите обработать.
Из ответа не сразу понятно, pdfTextбудет содержать номер счета-фактуры вместе с остальным текстом, но я предполагаю, что это так. Если этого не произойдет, тогда вам понадобится OCR, что совсем другое дело.
Моим первым побуждением было создать регулярное выражение (^\d{6}$) в этом случае и попробуйте применить его ко всему тексту на странице. Если совпадение только одно (номер счета), тогда отлично! В противном случае, если он соответствует большему количеству вещей, вы можете найти все вхождения и искать шаблон. Например, если у клиентов есть идентификатор, который также соответствует этому регулярному выражению, вы можете извлечь все строки, содержащие совпадающий номер, и отбросить все строки, содержащие некоторую другую информацию (возможно, все строки с номером клиента также будут иметь дату в определенном формат, например). В основном найдите все вхождения, в которых может совпадать регулярное выражение, и попытайтесь найти правила, чтобы исключить все вхождения, которые вам не нужны.