Как очистить изображения из результатов поиска изображений DuckDuckGo в Python
Я создаю приложение с python, которое будет показывать изображения, вырезанные из результатов поиска изображений DuckDuckGo. Поэтому мне нужно получить список ссылок на изображения на основе поиска. Проблема заключается в том, что HTML, составляющий результаты поиска изображений DuckDuckGo, не содержит никаких тегов изображений, но вместо этого изображения, похоже, хранятся в тегах деления. Как я могу с помощью python очистить эти чертовы ссылки на изображения и сохранить их в переменной в моей программе?
Как я хочу, чтобы моя переменная выглядела так:
image_links = ["https://duckduckgo.com/?q=duckduckgo&atb=v166-4_p&iax=images&ia=images&iai=https%3A%2F%2Fupload.wikimedia.org%2Fwikipedia%2Fen%2Fthumb%2F8%2F88%2FDuckDuckGo_logo.svg%2F1200px-DuckDuckGo_logo.svg.png","https://duckduckgo.com/?q=duckduckgo&atb=v166-4_p&iax=images&ia=images&iai=https%3A%2F%2Fupload.wikimedia.org%2Fwikipedia%2Fen%2Fthumb%2F8%2F88%2FDuckDuckGo_logo.svg%2F1200px-DuckDuckGo_logo.svg.png"]
Визуализация структуры HTML DuckDuckGo в результатах поиска изображений
Редактировать:
Когда я очищаю HTML от URL, сделав это:
source = urllib.request.urlopen("https://duckduckgo.com/?q=duckduckgo&atb=v166-4_p&iax=images&ia=images").read()
он не возвращает никаких тегов изображений вообще.
Я проверяю это, делая это:
source_tree = BeautifulSoup(source, 'html.parser')
links = [img.get('src') for img in source_tree.find_all('img', _class='tile--img__img')]
print(f"links: {links}")
print(f"img in source_tree: {'img' in str(source_tree)}")
print(f"source_tree: {source_tree}")
Выход:
links: []
img in source_tree: False
source_tree: <!DOCTYPE html>
<html class="no-js has-zcm" lang="en_US"><head><meta content="text/html; charset=utf-8" http-equiv="content-type"/><title>duckduckgo at DuckDuckGo</title><link href="/s1775.css" rel="stylesheet" type="text/css"/><link href="/r1775.css" rel="stylesheet" type="text/css"/><meta content="noindex,nofollow" name="robots"/><meta content="origin" name="referrer"/><meta content="duckduckgo" name="apple-mobile-web-app-title"/><link href="/favicon.ico" rel="shortcut icon" sizes="16x16 24x24 32x32 64x64" type="image/x-icon"><link href="/assets/icons/meta/DDG-iOS-icon_60x60.png?v=2" id="icon60" rel="apple-touch-icon"><link href="/assets/icons/meta/DDG-iOS-icon_76x76.png?v=2" id="icon76" rel="apple-touch-icon" sizes="76x76"/><link href="/assets/icons/meta/DDG-iOS-icon_120x120.png?v=2" id="icon120" rel="apple-touch-icon" sizes="120x120"/><link href="/assets/icons/meta/DDG-iOS-icon_152x152.png?v=2" id="icon152" rel="apple-touch-icon" sizes="152x152"/><link href="/assets/icons/meta/DDG-icon_256x256.png" rel="image_src"/><script type="text/javascript">var ct,fd,fq,it,iqa,iqm,iqs,iqp,iqq,qw,dl,ra,rv,rad,r1hc,r1c,r2c,r3c,rfq,rq,rds,rs,rt,rl,y,y1,ti,tig,iqd,locale,settings_js_version='s2472.js',is_twitter='',rpl=0;fq=0;fd=1;it=0;iqa=0;iqbi=0;iqm=0;iqs=0;iqp=0;iqq=0;qw=1;dl='';ct='DK';iqd=0;r1hc=0;r1c=0;r3c=0;rq='duckduckgo';rqd="duckduckgo";rfq=0;rt='A';ra='';rv='';rad='';rds=30;rs=0;spice_version='1396';spice_paths='{}';locale='en_US';settings_url_params={};rl='wt-wt';rlo=0;df='';ds='';sfq='';iar='';vqd='3-146459744347044482638673072010848595657-89706121844226791728716680155105882500';safe_ddg=0;;</script><meta content="width=device-width, initial-scale=1" name="viewport"><meta content="true" name="HandheldFriendly"><meta content="no" name="apple-mobile-web-app-capable"/></meta></meta></link></link></head><body class="body--serp"><input id="state_hidden" name="state_hidden" size="1" type="text"/><span class="hide">Ignore this box please.</span><div id="spacing_hidden_wrapper"><div id="spacing_hidden"></div></div><script src="/lib/l113.js" type="text/javascript"></script><script src="/locale/en_US/duckduckgo10.js" type="text/javascript"></script><script src="/util/u345.js" type="text/javascript"></script><script src="/d2615.js" type="text/javascript"></script><div class="site-wrapper js-site-wrapper"><div class="header-wrap js-header-wrap" id="header_wrapper"><div class="welcome-wrap js-welcome-wrap"></div><div class="header cw" id="header"><div class="header__search-wrap"><a class="header__logo-wrap js-header-logo" href="/" tabindex="-1"><span class="header__logo js-logo-ddg">DuckDuckGo</span></a><div class="header__content header__search"><form action="/" class="search--adv search--header js-search-form" id="search_form" name="x"><input autocomplete="off" class="search__input search__input--adv js-search-input" id="search_form_input" name="q" tabindex="1" type="text" value="duckduckgo"/><input class="search__clear js-search-clear" id="search_form_input_clear" tabindex="3" type="button" value="X"><input class="search__button js-search-button" id="search_button" tabindex="2" type="submit" value="S"><a class="search__dropdown" href="javascript:;" id="search_dropdown" tabindex="4"></a><div class="search__hidden js-search-hidden" id="search_elements_hidden"></div></input></input></form></div></div><div class="zcm-wrap zcm-wrap--header is-noscript-hidden" id="duckbar"></div></div><div class="header--aside js-header-aside"></div></div><div class="zci-wrap" id="zero_click_wrapper"></div><div class="verticals" id="vertical_wrapper"></div><div class="content-wrap" id="web_content_wrapper"><div class="serp__top-right js-serp-top-right"></div><div class="serp__bottom-right js-serp-bottom-right"><div class="js-feedback-btn-wrap"></div></div><div class="cw"><div class="serp__results js-serp-results" id="links_wrapper"><div class="results--main"><div class="search-filters-wrap"><div class="js-search-filters search-filters"></div></div><noscript><meta content="0;URL=/html?q=duckduckgo" http-equiv="refresh"/><link href="/css/noscript.css" rel="stylesheet" type="text/css"/><div class="msg msg--noscript"><p class="msg-title--noscript">You are being redirected to the non-JavaScript site.</p>Click <a href="/html/?q=duckduckgo">here</a> if it doesn't happen automatically.</div></noscript><div class="results--message" id="message"></div><div class="ia-modules js-ia-modules"></div><div class="results--ads results--ads--main is-hidden js-results-ads" id="ads"></div><div class="results is-hidden js-results" id="links"></div></div><div class="results--sidebar js-results-sidebar"><div class="sidebar-modules js-sidebar-modules"></div><div class="is-hidden js-sidebar-ads"></div></div></div></div></div><div id="bottom_spacing2"> </div></div><script type="text/javascript"></script><script type="text/JavaScript">function nrji() {nrj('/t.js?q=duckduckgo&t=A&l=wt-wt&s=0&ct=DK&ss_mkt=us&p_ent=website&ex=-1');nrj('/d.js?q=duckduckgo&t=A&l=wt-wt&s=0&ct=DK&ss_mkt=us&vqd=3-146459744347044482638673072010848595657-89706121844226791728716680155105882500&atb=v166-4_p&p_ent=website&ex=-1&sp=0');DDH.wikipedia_fathead=DDH.wikipedia_fathead||{};DDH.wikipedia_fathead.meta={"name":"Wikipedia","src_name":"Wikipedia","is_stackexchange":null,"perl_module":"DDG::Fathead::Wikipedia","unsafe":0,"live_date":null,"src_options":{"language":"en","min_abstract_length":"20","source_skip":"","skip_image_name":0,"is_wikipedia":1,"skip_abstract_paren":0,"skip_abstract":0,"skip_qr":"","is_mediawiki":1,"skip_icon":0,"is_fanon":0,"skip_end":"0","directory":"","src_info":""},"blockgroup":null,"description":"Wikipedia","signal_from":"wikipedia_fathead","tab":"About","producer":null,"production_state":"online","maintainer":{"github":"duckduckgo"},"src_id":1,"dev_milestone":"live","src_url":null,"attribution":null,"dev_date":null,"topic":["productivity"],"status":"live","id":"wikipedia_fathead","example_query":"nikola tesla","created_date":null,"src_domain":"en.wikipedia.org","repo":"fathead","js_callback_name":"wikipedia","designer":null,"developer":[{"name":"DDG Team","url":"http://www.duckduckhack.com","type":"ddg"}]};;};DDG.ready(nrji, 1);</script><script src="/g2124.js"></script><script type="text/javascript">DDG.ready(function () {DDG.duckbar.add({"meta":{"name":"Wikipedia","src_name":"Wikipedia","is_stackexchange":null,"perl_module":"DDG::Fathead::Wikipedia","unsafe":0,"live_date":null,"src_options":{"language":"en","min_abstract_length":"20","source_skip":"","skip_image_name":0,"is_wikipedia":1,"skip_abstract_paren":0,"skip_abstract":0,"skip_qr":"","is_mediawiki":1,"skip_icon":0,"is_fanon":0,"skip_end":"0","directory":"","src_info":""},"blockgroup":null,"description":"Wikipedia","signal_from":"wikipedia_fathead","tab":"About","producer":null,"production_state":"online","maintainer":{"github":"duckduckgo"},"src_id":1,"dev_milestone":"live","src_url":null,"attribution":null,"dev_date":null,"topic":["productivity"],"status":"live","id":"wikipedia_fathead","example_query":"nikola tesla","created_date":null,"src_domain":"en.wikipedia.org","repo":"fathead","js_callback_name":"wikipedia","designer":null,"developer":[{"name":"DDG Team","url":"http://www.duckduckhack.com","type":"ddg"}]},"signal":"medium","data":{"Results":[{"FirstURL":"https://duckduckgo.com","Text":"Official site - DuckDuckGo","Result":"<a href=\"https://duckduckgo.com\"><b>Official site</b></a><a href=\"https://duckduckgo.com\"> - DuckDuckGo</a>","Icon":{"URL":"https://duckduckgo.com/i/duckduckgo.com.ico","Width":16,"Height":16}}],"AbstractSource":"Wikipedia","Abstract":"DuckDuckGo is an Internet search engine that emphasizes protecting searchers' privacy and avoiding the filter bubble of personalized search results. DuckDuckGo distinguishes itself from other search engines by not profiling its users and by deliberately showing all users the same search results for a given search term, and emphasizes returning the best results, rather than the most results, generating those results from over 400 individual sources, including crowdsourced sites such as Wikipedia, and other search engines like Bing, Yahoo!, and Yandex.","Answer":"","Redirect":"","Heading":"DuckDuckGo","ImageWidth":340,"Definition":"","Entity":"website","meta":{"name":"Wikipedia","src_name":"Wikipedia","is_stackexchange":null,"perl_module":"DDG::Fathead::Wikipedia","unsafe":0,"live_date":null,"src_options":{"language":"en","min_abstract_length":"20","source_skip":"","skip_image_name":0,"is_wikipedia":1,"skip_abstract_paren":0,"skip_abstract":0,"skip_qr":"","is_mediawiki":1,"skip_icon":0,"is_fanon":0,"skip_end":"0","directory":"","src_info":""},"blockgroup":null,"description":"Wikipedia","signal_from":"wikipedia_fathead","tab":"About","producer":null,"production_state":"online","maintainer":{"github":"duckduckgo"},"src_id":1,"dev_milestone":"live","src_url":null,"attribution":null,"dev_date":null,"topic":["productivity"],"status":"live","id":"wikipedia_fathead","example_query":"nikola tesla","created_date":null,"src_domain":"en.wikipedia.org","repo":"fathead","js_callback_name":"wikipedia","designer":null,"developer":[{"name":"DDG Team","url":"http://www.duckduckhack.com","type":"ddg"}]},"AnswerType":"","Image":"https://duckduckgo.com/i/adad4e5c.png","RelatedTopics":[{"Result":"<a href=\"/Names_Database\">Names Database</a> - The Names Database is a defunct social network, owned and operated by Classmates.com, a wholly owned subsidiary of United Online. The site does not appear to be significantly updated since 2008, and has many broken links and display issues.","Text":"Names Database - The Names Database is a defunct social network, owned and operated by Classmates.com, a wholly owned subsidiary of United Online. The site does not appear to be significantly updated since 2008, and has many broken links and display issues.","FirstURL":"/Names_Database","Icon":{"URL":"","Height":"","Width":""}},{"Text":"Companies based in Chester County, Pennsylvania","FirstURL":"/c/Companies_based_in_Chester_County%2C_Pennsylvania","Result":"<a href=\"/c/Companies_based_in_Chester_County%2C_Pennsylvania\">Companies based in Chester County, Pennsylvania</a>","Icon":{"URL":"","Width":"","Height":""}},{"Text":"Tor hidden services","FirstURL":"/c/Tor_hidden_services","Result":"<a href=\"/c/Tor_hidden_services\">Tor hidden services</a>","Icon":{"Width":"","Height":"","URL":""}},{"Result":"<a href=\"/c/Perl_software\">Perl software</a>","FirstURL":"/c/Perl_software","Text":"Perl software","Icon":{"Height":"","Width":"","URL":""}},{"Result":"<a href=\"/c/Internet_privacy_software\">Internet privacy software</a>","FirstURL":"/c/Internet_privacy_software","Text":"Internet privacy software","Icon":{"Height":"","Width":"","URL":""}},{"Icon":{"URL":"","Width":"","Height":""},"FirstURL":"/c/Proprietary_cross-platform_software","Text":"Proprietary cross-platform software","Result":"<a href=\"/c/Proprietary_cross-platform_software\">Proprietary cross-platform software</a>"},{"Icon":{"Height":"","Width":"","URL":""},"Text":"Internet search engines","FirstURL":"/c/Internet_search_engines","Result":"<a href=\"/c/Internet_search_engines\">Internet search engines</a>"},{"Text":"Android (operating system) software","FirstURL":"/c/Android_(operating_system)_software","Result":"<a href=\"/c/Android_(operating_system)_software\">Android (operating system) software</a>","Icon":{"Height":"","Width":"","URL":""}}],"AbstractURL":"https://en.wikipedia.org/wiki/DuckDuckGo","AbstractText":"DuckDuckGo is an Internet search engine that emphasizes protecting searchers' privacy and avoiding the filter bubble of personalized search results. DuckDuckGo distinguishes itself from other search engines by not profiling its users and by deliberately showing all users the same search results for a given search term, and emphasizes returning the best results, rather than the most results, generating those results from over 400 individual sources, including crowdsourced sites such as Wikipedia, and other search engines like Bing, Yahoo!, and Yandex.","ImageIsLogo":1,"DefinitionSource":"","DefinitionURL":"","Type":"A","Infobox":{"meta":[{"value":"DuckDuckGo","label":"article_title","data_type":"string"},{"label":"template_name","data_type":"string","value":"infobox website"},{"label":"formatting_rules","data_type":"string","value":"website"}],"content":[{"data_type":"string","wiki_order":0,"label":"Type of site","sort_order":"1","value":"Web search engine"},{"sort_order":"1000","value":"Multilingual","wiki_order":1,"data_type":"string","label":"Available in"},{"sort_order":"1001","value":"Worldwide","wiki_order":2,"data_type":"string","label":"Area served"},{"sort_order":"2","value":"Duck Duck Go, Inc.","wiki_order":3,"data_type":"string","label":"Owner"},{"sort_order":"3","value":"Gabriel Weinberg","data_type":"string","wiki_order":4,"label":"Created by"},{"value":"284 (30, 2018)","sort_order":"4","label":"Alexa rank","wiki_order":5,"data_type":"string"},{"label":"Commercial","wiki_order":6,"data_type":"string","value":"Yes","sort_order":"1002"},{"sort_order":"1003","value":"None","wiki_order":7,"data_type":"string","label":"Registration"},{"value":"Sept 25, 2008","sort_order":"3","label":"Launched","data_type":"string","wiki_order":8},{"value":"Active","sort_order":"1004","label":"Current status","data_type":"string","wiki_order":9},{"wiki_order":10,"data_type":"string","label":"Written in","sort_order":"1005","value":"Perl, JavaScript, Python"},{"data_type":"github_profile","wiki_order":"101","label":"GitHub profile","value":"duckduckgo"},{"value":"duckduckgo","label":"Twitter profile","wiki_order":"102","data_type":"twitter_profile"},{"value":"duckduckgo","data_type":"facebook_profile","wiki_order":"104","label":"Facebook profile"},{"value":{"id":"Q114106","entity-type":"item","numeric-id":114106},"data_type":"instance","wiki_order":"207","label":"Instance of"}]},"ImageHeight":270},"model":"FatheadArticle","duckbar_topic":"About","templates":{"detail":"info_detail"}});});</script><script type="text/javascript">DDG.page = new DDG.Pages.SERP({ showSafeSearch: 0, instantAnswerAds: false });</script><div id="z2"> </div><div id="z"></div></body></html>
[Finished in 0.6s]
В чем причина этого и как я могу это исправить?
1 ответ
Изображения на самом деле хранятся в img теги, они просто вложены в некоторые div элементы.
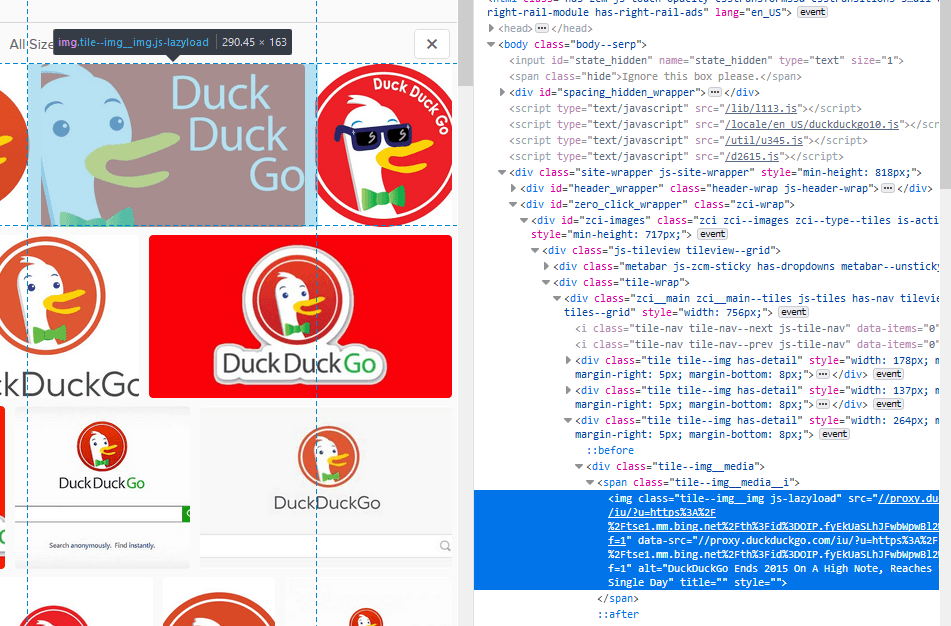
Вы должны быть в состоянии найти все изображения на странице с помощью селектора CSS img.tile--img__img,
Вы можете использовать библиотеку, такую как Beautiful Soup, для запроса всех этих ссылок, например так:
from bs4 import BeautifulSoup
# Considering your HTML is in the variable `source`
source_tree = BeautifulSoup(source, 'html.parser')
links = [img.get('src') for img in source_tree.find_all('img', class_='tile--img__img')]
редактировать
Похоже, проблема здесь в том, что duckduckgo отображает страницу изображений с использованием некоторого JavaScript для отображения всех img плитка. Поскольку запрос Python может только извлекать ресурсы и не выполнять JavaScript, вам может потребоваться реализовать другое решение. Посмотрите этот другой SO ответ для некоторых вариантов.
Поскольку duckduckgo не предоставляет API для поиска изображений, но он получает изображение с помощью вызова запроса.
Итак, у меня есть другое решение, которое может сработать. Здесь это решение будет работать только для ключевого слова = книга. Поскольку запрос поиска изображений использует параметр vqd, который является динамическим эйтером на основе искомого ключевого слова или компьютера пользователя.
Если это можно решить, этот код будет работать для любого ключевого слова, чтобы загрузить любое изображение.
Если кто-то может расшифровать этот vqd, просто замените:
'q': 'book',
с участием
'q': keyword,
а в остальном все нормально.
from bs4 import *
import requests as rq
import os
# api-endpoint
URL = "https://duckduckgo.com/i.js"
keyword = input('Enter the search keyword : ')
# defining a params dict for the parameters to be sent to the API
PARAMS = {'l': 'us-en',
'o': 'json',
'q': 'book',
'vqd': '3-160127109499719016074744569811997028386-179481262599639828155814625357171050706&f=,,,',
}
# sending get request and saving the response as response object
r = rq.get(url=URL, params=PARAMS)
# extracting data in json format
data = r.json()
img_link = data["results"][0]['image']
img_data = rq.get(img_link).content
# os.mkdir('downloads')
filename = "downloads/" + keyword + ".png"
with open(filename, 'wb+') as f:
f.write(img_data)
print("File " + keyword + ".png successfully downloaded.")
Если это помогло, дайте мне знать, подняв палец вверх.
Если у кого-то есть какое-либо решение / обновление, дайте нам знать.
========================= Обновленный ответ ======================= ==
Для этого также доступен пакет github. Основная проблема с приведенным выше сценарием заключалась в значении этого параметра (vqd). С помощью этого пакета я создал следующий скрипт.
import requests
import re
import json
import os
def search(keywords, max_results=None):
url = 'https://duckduckgo.com/'
params = {
'q': keywords
}
print("Hitting DuckDuckGo for Token")
# First make a request to above URL, and parse out the 'vqd'
# This is a special token, which should be used in the subsequent request
res = requests.post(url, data=params)
searchObj = re.search(r'vqd=([\d-]+)\&', res.text, re.M | re.I)
if not searchObj:
print("Token Parsing Failed !")
return -1
print("Obtained Token")
headers = {
'dnt': '1',
'accept-encoding': 'gzip, deflate, sdch, br',
'x-requested-with': 'XMLHttpRequest',
'accept-language': 'en-GB,en-US;q=0.8,en;q=0.6,ms;q=0.4',
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
'accept': 'application/json, text/javascript, */*; q=0.01',
'referer': 'https://duckduckgo.com/',
'authority': 'duckduckgo.com',
}
params = (
('l', 'wt-wt'),
('o', 'json'),
('q', keywords),
('vqd', searchObj.group(1)),
('f', ',,,'),
('p', '2')
)
requestUrl = url + "i.js"
try:
res = requests.get(requestUrl, headers=headers, params=params)
data = json.loads(res.text)
saveImage(data["results"], keywords)
except ValueError as e:
print('Please try later.')
# logger.debug("Hitting Url Success : %s", requestUrl)
def saveImage(objs, keyword):
for obj in objs:
img_link = obj['image']
img_data = requests.get(img_link).content
# os.mkdir('downloads')
filename = "downloads/" + keyword + ".png"
with open(filename, 'wb+') as f:
f.write(img_data)
print("File " + keyword + ".png successfully downloaded.")
break
while True:
keyword = input('Enter the search keyword : ')
# print(keyword)
search(keyword)
В моем решении использовался селен, как предложено в ответе, отмеченном как правильный.
from urllib.parse import unquote
from selenium import webdriver
def search(query):
driver = webdriver.Firefox()
# For one word queries it will be ok, for complex ones should encode first
driver.get(f'https://duckduckgo.com/?q={query}&t=h_&iax=images&ia=images')
# For now it's working with this class, not sure if it will never change
img_tags = driver.find_elements_by_class_name('tile--img__img')
for tag in img_tags:
src = tag.get_attribute('data-src')
src = unquote(src)
src = src.split('=', maxsplit=1)
src = src[1]
yield src
driver.close()
if __name__ == '__main__':
from pprint import pprint
imgs_urls = list(search('sun'))
pprint(imgs_urls)
Вам понадобится библиотека selenium python, которую вы можете установить с помощью pip и geckodriver, которые можно найти в вашем диспетчере пакетов распространения.