Как разобрать текст, извлеченный из файла PDF с разделителем, используя Python?
Я попытался PyPDF2 для извлечения и анализа текста из PDF, используя следующий фрагмент кода;
import PyPDF2
import re
pdfFileObj = open('test.pdf', 'rb')
pdfReader = PyPDF2.PdfFileReader(pdfFileObj)
rawText = pdfReader.getPage().extractText()
extractedText = re.split('\n|\t', rawText)
print("Extracted Text: " + str(extractedText) + "\n")
Случай 1: Когда я пытаюсь разобрать текст в формате pdf, мне не удалось разобрать их так же точно, как они отображаются в формате pdf. Например,

В этом случае разрыв строки или новая строка не могут быть найдены в обоих rawText или же extractedText и результаты как ниже
input field, your old automation script will try to submit a form with missing data unless you update it.Another common case is asserting that a specific error message appeared and then updating the error message, which will also break the script.
Случай 2: И для следующего случая,
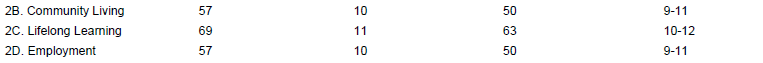
Это дает результат как
2B. Community Living5710509-112C. Lifelong Learning69116310-122D. Employment5710509-11
который сложнее анализировать и различать эти индивидуальные оценки. Можно ли идеально проанализировать этот сценарий с PyPDF2 или любой другой библиотекой Python?