Когда использовать Spark DataFrame/Dataset API, а когда использовать простой RDD?
Механизм исполнения Spark SQL DataFrame/Dataset имеет несколько чрезвычайно эффективных способов оптимизации времени и пространства (например, InternalRow и выражение codeGen). Согласно многим документациям, для большинства распределенных алгоритмов этот вариант лучше, чем RDD.
Тем не менее, я провел некоторые исследования исходного кода и до сих пор не убежден. Я не сомневаюсь, что InternalRow намного компактнее и может сэкономить большой объем памяти. Но выполнение алгоритмов не может быть быстрее при сохранении предопределенных выражений. А именно это указано в исходном коде org.apache.spark.sql.catalyst.expressions.ScalaUDF, что каждая пользовательская функция делает 3 вещи:
- преобразовать тип катализатора (используется в InternalRow) в тип scala (используется в GenericRow).
- применить функцию
- преобразовать результат обратно из типа Scala в тип катализатора
По-видимому, это даже медленнее, чем просто применять функцию непосредственно к СДР без какого-либо преобразования. Может ли кто-нибудь подтвердить или опровергнуть мои предположения с помощью профилирования и анализа кода?
Большое спасибо за любое предложение или понимание.
1 ответ
Из этой статьи в блоге Databricks " Рассказ о трех API-интерфейсах Apache Spark: RDD, DataFrames и Datasets"
Когда использовать СДР?
Рассмотрите эти сценарии или общие случаи использования RDD, когда:
- вы хотите низкоуровневое преобразование и действия и контроль над вашим набором данных;
- ваши данные неструктурированы, такие как медиа потоки или потоки текста;
- вы хотите манипулировать вашими данными с помощью функциональных конструкций программирования, а не выражений, специфичных для предметной области;
- вам не нужно навязывать схему, такую как столбчатый формат, при обработке или обращении к атрибутам данных по имени или столбцу;
- и вы можете отказаться от некоторых преимуществ оптимизации и производительности, доступных с DataFrames и Datasets для структурированных и полуструктурированных данных.
В главе 3, посвященной высокопроизводительным Spark, DataFrames, Datasets и Spark SQL, вы можете увидеть некоторую производительность, которую вы можете получить с помощью Dataframe/Dataset API по сравнению с RDD.
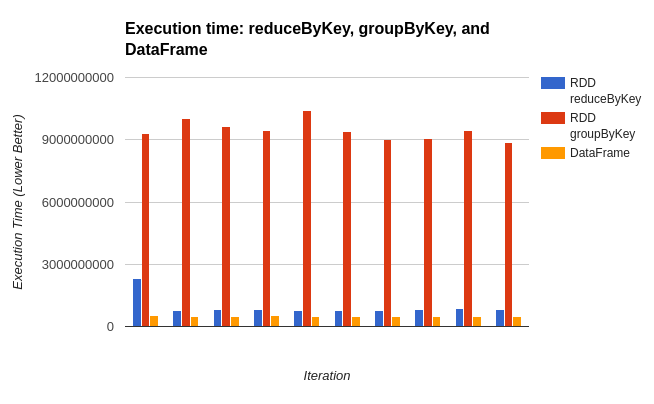
И в упомянутой статье Databricks вы также можете найти, что Dataframe оптимизирует использование пространства по сравнению с RDD

Я думаю, что набор данных - это схема RDD. когда вы создаете набор данных, вы должны указать ему StructType.
Фактически, набор данных после логического плана и физического плана будет генерировать оператор RDD. Возможно, это больше производительность RDD, чем набор данных.