Конвейер данных AWS: вывод данных на 3 узла s3
У меня есть сценарий использования, в котором я хочу взять данные из DynamoDB и выполнить некоторые преобразования данных. После этого я хочу создать 3 CSV-файла (будет 3 преобразования для одних и тех же данных) и выгрузить их в 3 разных местоположения s3. Моя архитектура будет выглядеть следующим образом: 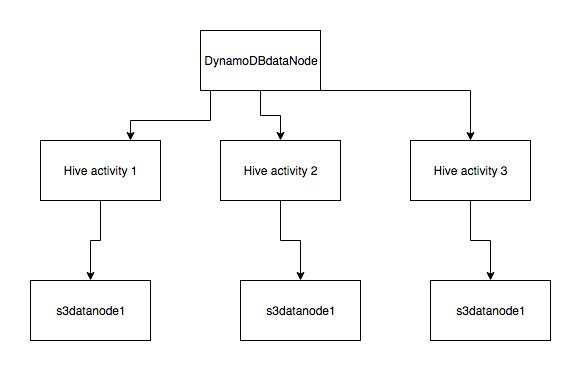
Возможно ли это сделать? Я не могу найти какую-либо документацию по этому поводу. Если это невозможно с помощью конвейера, есть ли другие сервисы, которые могут помочь мне в моем случае использования?
Эти свалки будут планироваться ежедневно. Мое другое соображение было использовать AWS Lamda. Но, насколько я понимаю, это основано на событиях, а не на графике, верно?
1 ответ
Спасибо Амит за ваш ответ. Я был занят уже довольно давно. Я немного покопался после того, как вы опубликовали свой ответ. Оказывается, мы можем записывать данные в разные места s3, используя активность Hive.
Вот как хотелось бы в этом случае конвейеру данных.
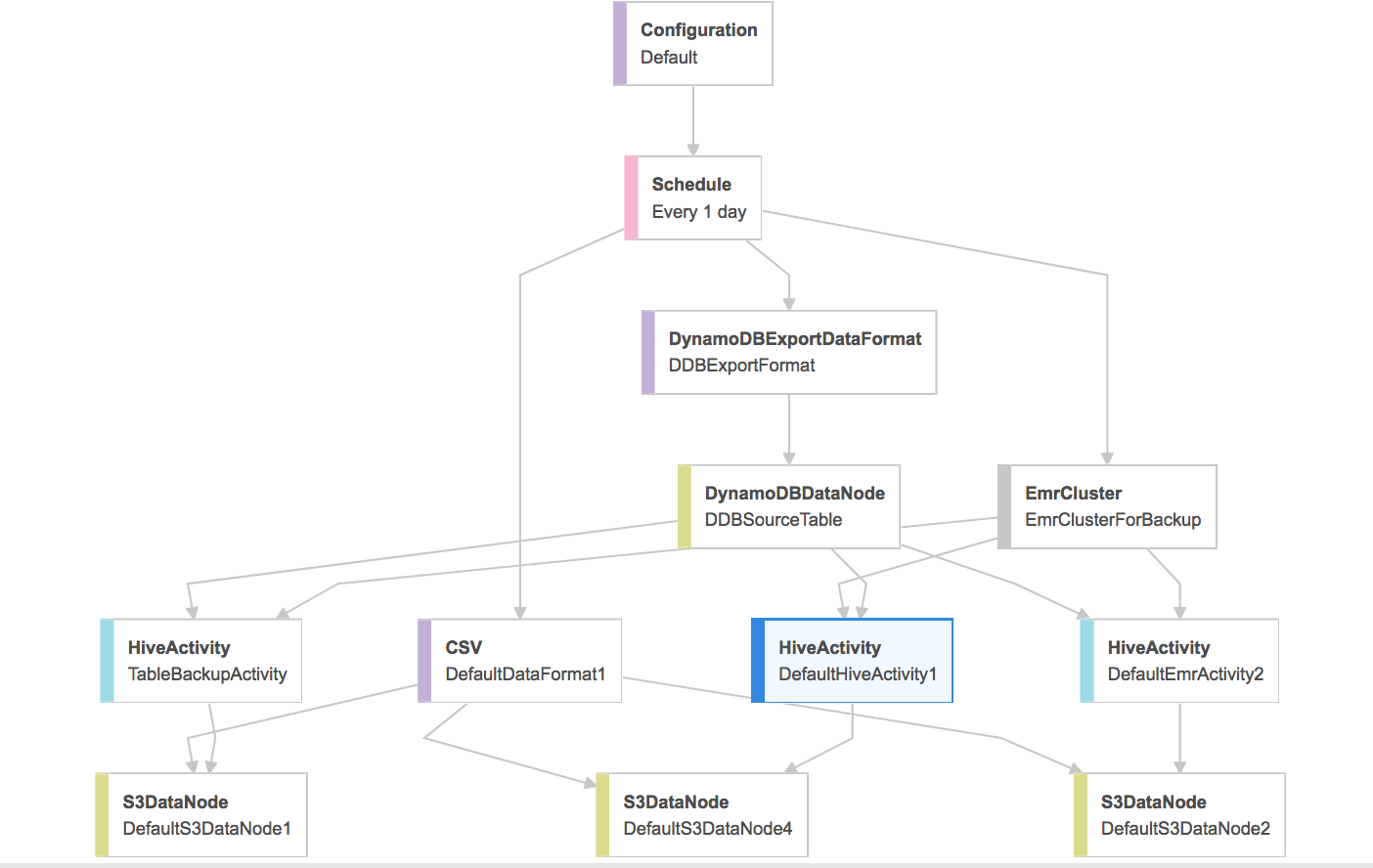
Но я считаю, что написание нескольких действий улья, когда вашим источником ввода является таблица DynamoDB, не является хорошей идеей, поскольку куст не загружает никаких данных в память. Он выполняет все вычисления на фактической таблице, что может ухудшить производительность таблицы. Даже документация предлагает экспортировать данные, если вам нужно сделать несколько запросов к одним и тем же данным. Ссылка
Введите команду Hive, которая сопоставляет таблицу в приложении Hive с данными в DynamoDB. Эта таблица служит ссылкой на данные, хранящиеся в Amazon DynamoDB; данные не хранятся локально в Hive, и любые запросы, использующие эту таблицу, выполняются для текущих данных в DynamoDB, потребляя емкость таблицы для чтения или записи при каждом запуске команды. Если вы ожидаете выполнить несколько команд Hive для одного и того же набора данных, сначала рассмотрите возможность его экспорта.
В моем случае мне нужно было выполнять разные типы агрегаций для одних и тех же данных один раз в день. Поскольку DynamoDB не поддерживает агрегации, я обратился к конвейеру данных с помощью Hive. В итоге мы использовали AWS Aurora на основе My-SQL.
Да, это возможно, но не используйте HiveActivity вместо EMRActivity. Если вы посмотрите документацию конвейера данных для HiveActivity, в ней четко указано ее назначение, а не ваш вариант использования:
Запускает запрос Hive в кластере EMR. HiveActivity упрощает настройку активности Amazon EMR и автоматически создает таблицы Hive на основе входных данных, поступающих из Amazon S3 или Amazon RDS. Все, что вам нужно указать, это HiveQL для запуска на исходных данных. AWS Data Pipeline автоматически создает таблицы Hive с ${input1}, ${input2} и т. Д. На основе полей ввода в объекте HiveActivity.
Ниже показано, как должен выглядеть ваш конвейер данных. Также есть встроенный шаблон Export DynamoDB table to S3 в пользовательском интерфейсе для AWS Data Pipeline, который создает базовую структуру для вас, а затем вы можете расширить / настроить в соответствии с вашими требованиями.
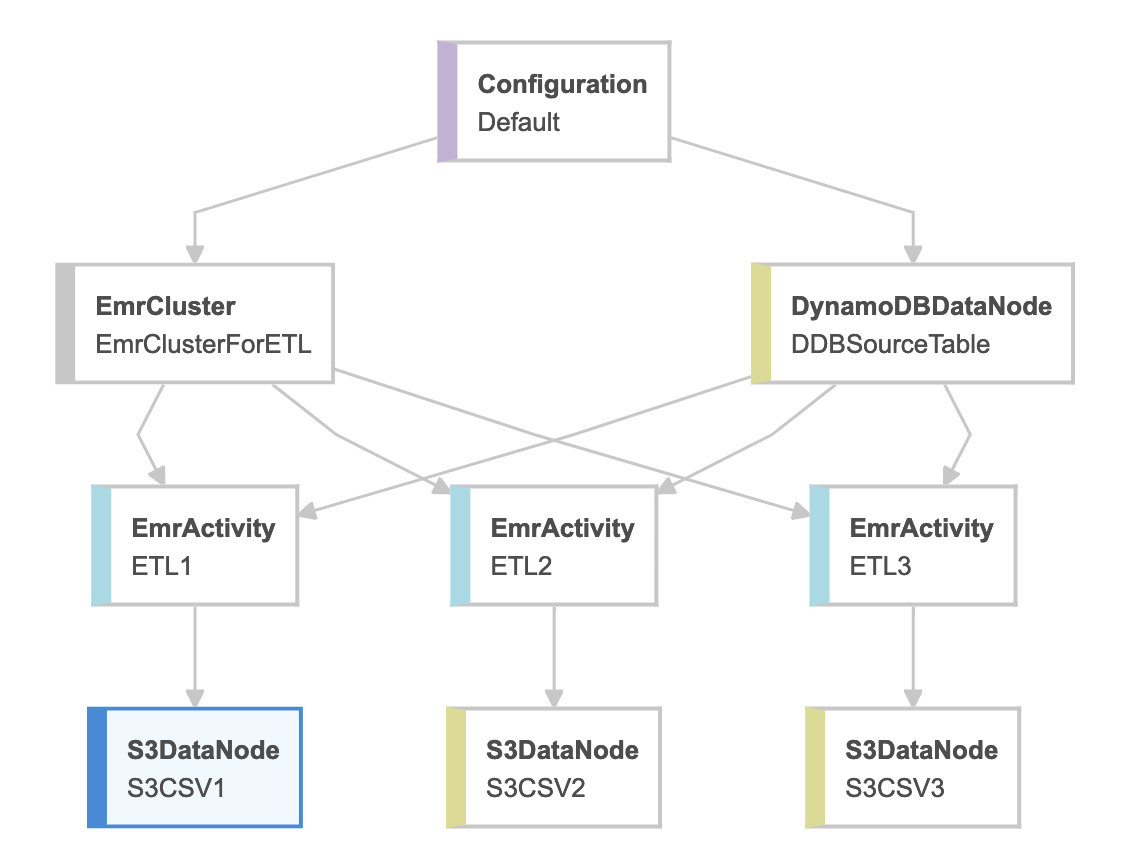
К вашему следующему вопросу, использующему Lambda, конечно, лямбда может быть настроена на запуск по событиям или по расписанию, но я бы не рекомендовал использовать AWS Lambda для любых операций ETL, поскольку они привязаны ко времени, а обычные ETL длиннее лямбда-времени.
AWS предлагает специальные оптимизированные функции для ETL, AWS Data Pipeline & AWS Glue Я всегда рекомендовал бы выбирать между одним из двух. Если в вашем ETL используются источники данных, не управляемые в сервисах вычислений и хранения AWS, ИЛИ какой-либо специальный вариант использования, который не может быть удовлетворен указанными выше двумя вариантами, то AWS Batch будет моим следующим соображением.