Почему Prettify использует стандартное регулярное выражение, даже когда я добавляю пользовательское регулярное выражение для PR_TYPE в отдельный обработчик языка?
Я пытаюсь написать надстройку языкового обработчика Google Prettify для Qiskit для реализации на бирже стека Quantum Computing. Я разветвил репозиторий кода-prettify и добавил lang-qiskit.js:
PR['registerLangHandler'](
PR['createSimpleLexer'](
[
// plain text
[PR['PR_PLAIN'], /^\s+/, null, ' \r\n\t\xA0'],
// string literals
[PR['PR_STRING'], /^(?:\'\'\'(?:[^\'\\]|\\[\s\S]|\'{1,2}(?=[^\']))*(?:\'\'\'|$)|\"\"\"(?:[^\"\\]|\\[\s\S]|\"{1,2}(?=[^\"]))*(?:\"\"\"|$)|\'(?:[^\\\']|\\[\s\S])*(?:\'|$)|\"(?:[^\\\"]|\\[\s\S])*(?:\"|$))/, null],
],
[ // hash comments
[PR['PR_COMMENT'], /^#(?:##(?:[^#]|#(?!##))*(?:###|$)|.*)/, null, '#'],
// Python v3.7.3 keywords
[PR['PR_KEYWORD'], /\b(?:False|None|True|and|as|assert|async|await|break|class|continue|def|del|elif|else|except|finally|for|from|global|if|import|in|is|lambda|nonlocal|not|or|pass|raise|return|try|while|with|yield)\b/],
// valid class names
[PR['PR_TYPE'], /^(?:[@_]?[a-zA-Z]+[a-zA-Z0-9][A-Za-z_$@0-9]*|\w+_t\b)/, null],
// valid literals
[PR['PR_LITERAL'], /^(?:0x[a-f0-9]+|(?:\d(?:_\d+)*\d*(?:\.\d*)?|\.\d\+)(?:e[+\-]?\d+)?)[a-z]*/],
// valid variable names
[PR['PR_PLAIN'], /^[a-zA-Z_$][a-zA-Z_$0-9]*/],
]),
['qiskit']);
Я верю PR_TYPE regex - это то, что обрабатывает имена классов (например, в Python). Поскольку переполнение стека также использует Google Prettify, я приведу пример:
from qiskit import QuantumRegister, ClassicalRegister, U3Gate
from qiskit.extensions.simulator import wait
Вы заметите, что в то время как QuantumRegister, ClassicalRegister быть выделенным, U3Gate а также wait не делайте. Это потому, что регулярное выражение PR_TYPE ^(?:[@_]?[A-Z]+[a-z][A-Za-z_$@0-9]*|\w+_t\b) ( ссылка regex101), которая не допускает слова, начинающиеся с нижнего регистра, или слова, содержащие цифру в середине. Я изменил это регулярное выражение ^(?:[@_]?[a-zA-Z]+[a-zA-Z0-9][A-Za-z_$@0-9]*|\w+_t\b) ( ссылка на regex101), как вы можете заметить в моем первом фрагменте выше.
Теперь, когда я запускаю следующий файл Javascript в соответствии с инструкциями на странице Prettify Getting Started (то есть с <script src="https://cdn.jsdelivr.net/gh/BlueStackExchange/code-prettify@master/loader/run_prettify.js?lang=qiskit&skin=sunburst"></script> в шапке) до сих пор вижу что U3Gate а также wait не выделяются
<script src="https://cdn.jsdelivr.net/gh/BlueStackExchange/code-prettify@master/loader/run_prettify.js?lang=qiskit&skin=sunburst"></script>
<?prettify lang=qiskit?>
<pre class="prettyprint qiskit">
from qiskit import QuantumCircuit, QuantumRegister, ClassicalRegister, U3Gate, wait
def build_bell_circuit():
"""Returns a circuit putting 2 qubits in the Bell state."""
q = QuantumRegister(2)
c = ClassicalRegister(2)
qc = QuantumCircuit(q, c)
qc.h(q[0])
qc.cx(q[0], q[1])
qc.measure(q, c)
x = 3 + 4j
return qc
await async
# Create the circuit
bell_circuit = build_bell_circuit()
# Use the internal .draw() to print the circuit
print(bell_circuit)
</pre>
Вот соответствующий выделенный код:
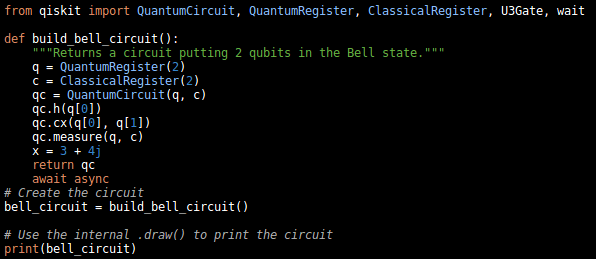
Вы можете запустить это и проверить это здесь.
В общем, мой вопрос: почему Prettify все еще использует регулярное выражение для PR_TYP, хотя я включил модифицированное регулярное выражение в дополнение? Как это исправить?