Отбросить все строки группы при выполнении условия?
У меня есть панды данных фрейм имеют двухуровневую группу на основе col10 ' а также ' col1 '. Все, что я хочу сделать, это удалить все строки группы, если указанное значение в другом столбце повторялось или это значение не существовало в группе (оставьте группу, в которой указанное значение существовало только один раз), например:
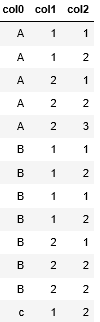
Исходный фрейм данных:
df = pd.DataFrame( {'col0':['A','A','A','A','A','B','B','B','B','B','B','B','c'],'col1':[1,1,2,2,2,1,1,1,1,2,2,2,1], 'col2':[1,2,1,2,3,1,2,1,2,2,2,2,1]})
Мне нужно сохранить строки для группы, например (['A',1],['A',2],['B',2]) в этом оригинальном DF
- Желаемый фрейм данных:
Я попробовал этот шаг:
df.groupby(['col0','col1']).apply(lambda x: (x['col2']==1).sum()==1)
где результат
col0 col1
A 1 True
2 True
B 1 False
2 True
c 1 False
dtype: bool
Как создать нужный Df на основе этого bool?
1 ответ
Вы можете сделать это, как показано ниже:
m=(df.groupby(['col0','col1'])['col2'].
transform(lambda x: np.where((x.eq(1)).sum()==1,x,np.nan)).dropna().index)
df.loc[m]
Или же:
df[df.groupby(['col0','col1'])['col2'].transform(lambda x: x.eq(1).sum()==1)]
col0 col1 col2
0 A 1 1
1 A 1 2
2 A 2 1
3 A 2 2
4 A 2 3
12 c 1 1