Что мешает этому использованию map.pool в python?
У меня есть программа командной строки, которую я запускаю, и я передаю текст в качестве аргументов:
somecommand.exe Он работает некоторое время (обычно от хорошей доли часа до нескольких часов), а затем записывает результаты в несколько текстовых файлов. Я пытаюсь написать скрипт для запуска нескольких из них одновременно, используя все ядра на многоядерной машине. На других ОС я бы разветвлялся, но это не реализовано во многих языках сценариев для Windows. Многопроцессорная обработка Python выглядит так, как будто она может сработать, поэтому я решил попробовать, хотя я вообще не знаю Python. Я надеюсь, что кто-то может сказать мне, что я делаю неправильно. Я написал скрипт (ниже), который указывает на каталог, если находит исполняемые и входные файлы и запускает их, используя pool.map и пул n, и функцию, используя вызов. Что я вижу, так это то, что изначально (с первым набором из n запущенных процессов) все выглядит нормально, используя n ядер на 100%. Но затем я вижу, что процессы бездействуют, используя только несколько процентов своих процессоров. Там всегда n процессов, но они мало что делают. Похоже, что это происходит, когда они начинают записывать файлы выходных данных, и как только он запускается, все затихает, и общее использование ядра колеблется от нескольких процентов до случайных пиков 50-60%, но никогда не достигает 100%. Если я могу прикрепить его (редактировать: я не могу, по крайней мере сейчас), вот график времени выполнения процессов. Нижняя кривая была, когда я открывал n командных строк и вручную поддерживал n процессов одновременно, легко поддерживая компьютер на уровне 100%. (Строка регулярная, медленно увеличивается от 0 до 0,7 часа в 32 различных процессах, меняющих параметр.) Верхняя строка является результатом некоторой версии этого скрипта - время выполнения увеличивается в среднем примерно на 0,2 часа и составляет гораздо менее предсказуемый, как если бы я взял нижнюю строчку и добавил 0,2 + случайное число. Вот ссылка на сюжет: Время выполнения сюжета Изменить: и теперь я думаю, что я могу добавить сюжет. Что я делаю неправильно?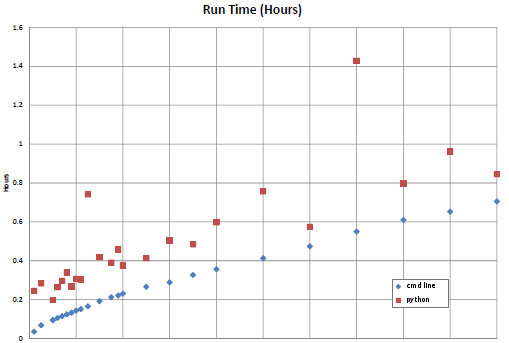
from multiprocessing import Pool, cpu_count, Lock
from subprocess import call
import glob, time, os, shlex, sys
import random
def launchCmd(s):
mypid = os.getpid()
try:
retcode = call(s, shell=True)
if retcode < 0:
print >>sys.stderr, "Child was terminated by signal", -retcode
else:
print >>sys.stderr, "Child returned", retcode
except OSError, e:
print >>sys.stderr, "Execution failed:", e
if __name__ == '__main__':
# ******************************************************************
# change this to the path you have the executable and input files in
mypath = 'E:\\foo\\test\\'
# ******************************************************************
startpath = os.getcwd()
os.chdir(mypath)
# find list of input files
flist = glob.glob('*_tin.txt')
elist = glob.glob('*.exe')
# this will not act as expected if there's more than one .exe file in that directory!
ex = elist[0] + ' < '
print
print 'START'
print 'Path: ', mypath
print 'Using the executable: ', ex
nin = len(flist)
print 'Found ',nin,' input files.'
print '-----'
clist = [ex + s for s in flist]
cores = cpu_count()
print 'CPU count ', cores
print '-----'
# ******************************************************
# change this to the number of processes you want to run
nproc = cores -1
# ******************************************************
pool = Pool(processes=nproc, maxtasksperchild=1) # start nproc worker processes
# mychunk = int(nin/nproc) # this didn't help
# list.reverse(clist) # neither did this, or randomizing the list
pool.map(launchCmd, clist) # launch processes
os.chdir(startpath) # return to original working directory
print 'Done'
2 ответа
Есть ли вероятность того, что процессы пытаются записать в общий файл? Под Linux это, вероятно, будет просто работать, забивая данные, но не замедляя их; но в Windows один процесс может получить файл, а все остальные процессы могут зависнуть, ожидая, пока файл станет доступным.
Если вы замените свой фактический список задач на некоторые глупые задачи, которые используют ЦП, но не записывают на диск, воспроизводится ли проблема? Например, у вас могут быть задачи, которые вычисляют сумму md5 некоторого большого файла; после того, как файл был кэширован, другие задачи будут состоять из чистого процессора, а затем выводиться на stdout в одну строку. Или вычислить какую-нибудь дорогую функцию или что-то.
Я думаю, что знаю это. Когда вы звоните map, он разбивает список задач на "чанки" для каждого процесса. По умолчанию он использует куски, достаточно большие, чтобы отправлять их каждому процессу. Это работает при условии, что все задачи занимают примерно одинаковое время.
В вашей ситуации, по-видимому, выполнение задач может занять очень разное время. Таким образом, некоторые рабочие заканчивают работу раньше других, и эти процессоры бездействуют. Если это так, то это должно работать как ожидалось:
pool.map(launchCmd, clist, chunksize=1)
Менее эффективно, но это должно означать, что каждый работник получает больше заданий по мере его завершения, пока они все не будут выполнены.