Tabula-py не может извлечь некоторое содержимое таблицы
Я пытаюсь извлечь таблицы из PDF-файла для академических исследований по tabula-py. Я частично могу это сделать.
Проблема в том, что информационный фрейм pandas не содержит информацию в pdf-файле для определенного типа ячеек. Оригинальный файл PDF составляет почти 2000 страниц, но я включаю только первую страницу здесь.
Мой PDF-файл выглядит так: 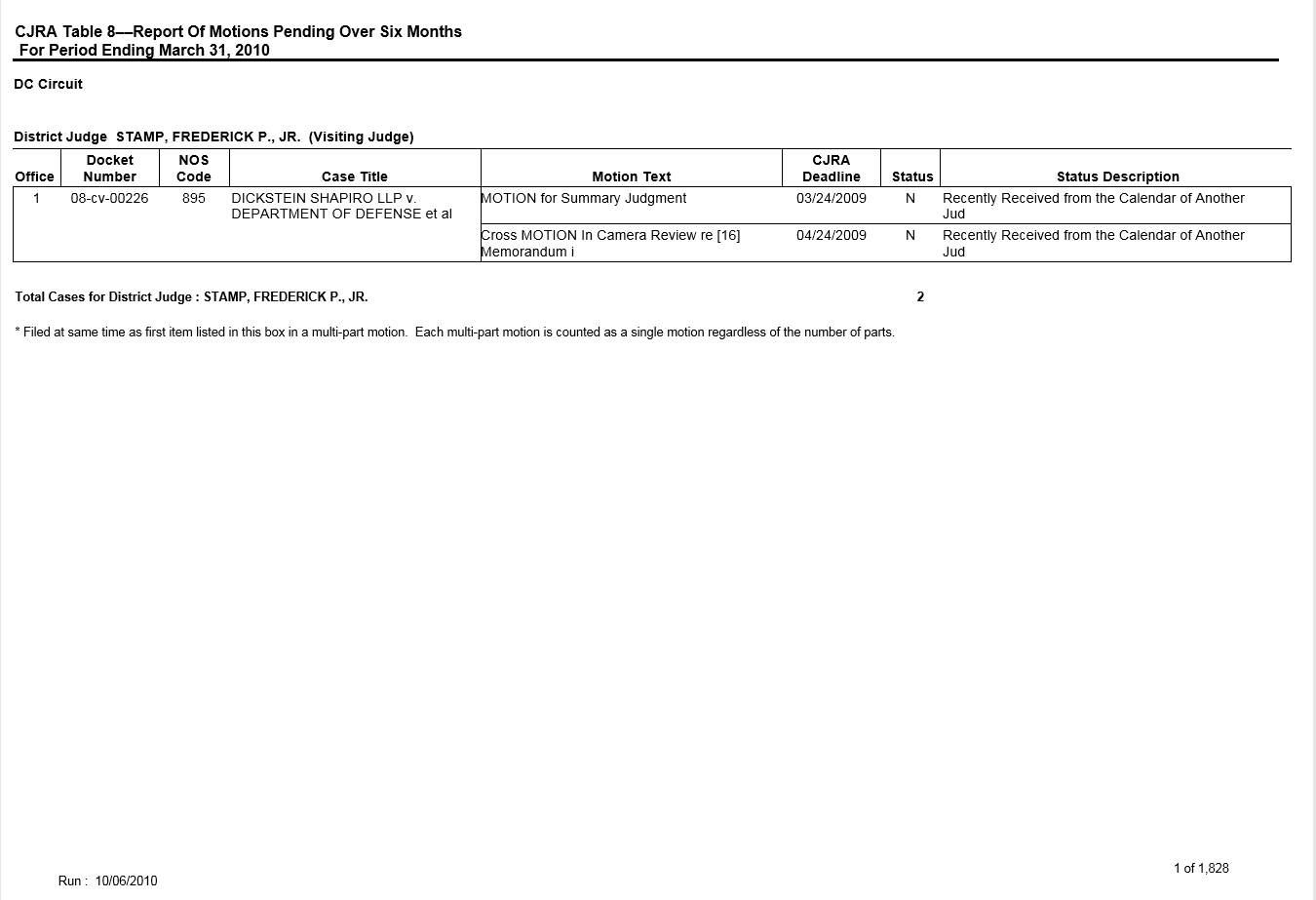
Это мой код
df = tabula.read_pdf(path, lattice = True, stream = False, pages = '1-10', pandas_options={'names':varlist}, encoding = "utf-8")
df = df.replace('\r',' ', regex=True)
df = df.replace('\xad', '')
Кроме того, это фрейм данных, который я получаю из кода выше. Извините, я не могу правильно вставить данные, хотя я пробовал разные способы. Я показываю только первые 3 столбца.
0 CJRA Таблица 8–– Отчет о движениях, ожидающих решения над... NaN NaN
1 Окружной суд США по округу Колумбия NaN NaN
2 Офисный Номер Кода NOS Код
3 1 08cv00226 895
4 NaN NaN NaN
5 NaN NaN NaN
6 Всего дел для окружного судьи: STAMP, FREDER... NaN 2
7 * Подано одновременно с первым пунктом, перечисленным в... NaN NaN
8 NaN NaN NaN
9 1 из 1 828 Прогон: 10/06/2010 NaN NaN
Как видите, первая ячейка в строке с индексом 1 не имеет той же информации, что и вторая строка в таблице PDF. В файле PDF я вижу название округа и имя судьи, на кадре данных я вижу название суда. Все остальные записи верны.
В чем может быть проблема? Спасибо заранее.