Заказ участка R geom_bar
У меня есть набор данных (1000 идентификаторов, 9 классов), подобный этому:
ID Class Value
1 A 0.014
1 B 0.665
1 C 0.321
2 A 0.234
2 B 0.424
2 C 0.342
... ... ...
Value столбец (относительные) численности, то есть сумма всех классов для одного человека равна 1.
Я хотел бы создать ggplot geom_bar график в R, где ось x упорядочена не по идентификаторам, а по уменьшению численности классов, аналогично этому:
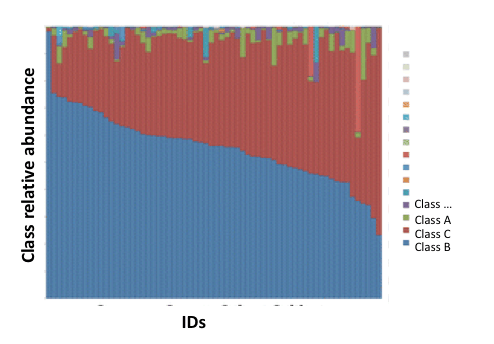
В нашем примере, скажем, что Class B самый распространенный класс среди всех людей, за которым следует Class C и наконец Class Aпервый столбец оси х будет для человека с самым высоким Class BВторым баром будет индивид со вторым по величине Class B, так далее.
Вот что я попробовал:
ggplot(df, aes(x=ID, y=Value, fill=Class)) +
geom_bar(stat="identity") +
xlab("") +
ylab("Relative Abundance\n")
1 ответ
Решение
Вы можете изменить порядок, прежде чем передать результат ggplot():
library(dplyr)
library(ggplot2)
# sum the abundance for each class, across all IDs, & sort the result
sort.class <- df %>%
count(Class, wt = Value) %>%
arrange(desc(n)) %>%
pull(Class)
# get ID order, sorted by each ID's abundance in the most abundant class
ID.order <- df %>%
filter(Class == sort.class[1]) %>%
arrange(desc(Value)) %>%
pull(ID)
# factor ID / Class in the desired order
df %>%
mutate(ID = factor(ID, levels = ID.order)) %>%
mutate(Class = factor(Class, levels = rev(sort.class))) %>%
ggplot(aes(x = ID, y = Value, fill = Class)) +
geom_col(width = 1) #geom_col is equivalent to geom_bar(stat = "identity")

Пример данных:
library(tidyr)
set.seed(1234)
df <- data.frame(
ID = seq(1, 100),
A = sample(seq(2, 3), 100, replace = TRUE),
B = sample(seq(5, 9), 100, replace = TRUE),
C = sample(seq(3, 7), 100, replace = TRUE),
D = sample(seq(1, 2), 100, replace = TRUE)
) %>%
gather(Class, Value, -ID) %>%
group_by(ID) %>%
mutate(Value = Value / sum(Value)) %>%
ungroup() %>%
arrange(ID, Class)
> df
# A tibble: 400 x 3
ID Class Value
<int> <chr> <dbl>
1 1 A 0.143
2 1 B 0.357
3 1 C 0.429
4 1 D 0.0714
5 2 A 0.176
6 2 B 0.412
7 2 C 0.294
8 2 D 0.118
9 3 A 0.2
10 3 B 0.4
# ... with 390 more rows