Как получить последнее значение с помощью dropDuplicates()?
Допустим, у меня есть следующий искровой фрейм данных (df):
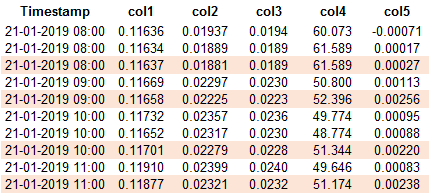
Как видно, в столбце "Timestamp" есть повторяющиеся значения, и я хочу избавиться от них, оставив строки, в которых "Timestamp" имеет уникальные значения.
Я попытался удалить дубликаты с помощью этой строки кода:
df.dropDuplicates(['Timestamp'])
Похоже на то dropDuplicates() сохраняет первую строку в дублированных строках, но мне нужно иметь последнюю строку в дубликате (те, которые выделены в таблице). Как это может быть сделано?
2 ответа
Существует обходной путь, использующий groupBy а также last, Мы можем сделать его общим, определив last агрегатор в каждом столбце, но Timestamp,
// let's define the aggregators
val aggs = df.columns
.filter(_ != "Timestamp")
.map(c => last(col(c)) as c)
// And use them:
val result = df
.groupBy("Timestamp")
.agg(aggs.head, aggs.tail :_*)
@Oli предложил хорошее решение, которое я использовал следующим образом (используя python):
exprs = [last(x).alias(x) for x in df.columns if x != 'Timestamp']
df0 = df.groupBy("Timestamp").agg(*exprs)
Надеюсь, что это поможет людям, которые могут получить подобную проблему