Концепции Apache Spark + Delta Lake
У меня много сомнений по поводу Spark + Delta. 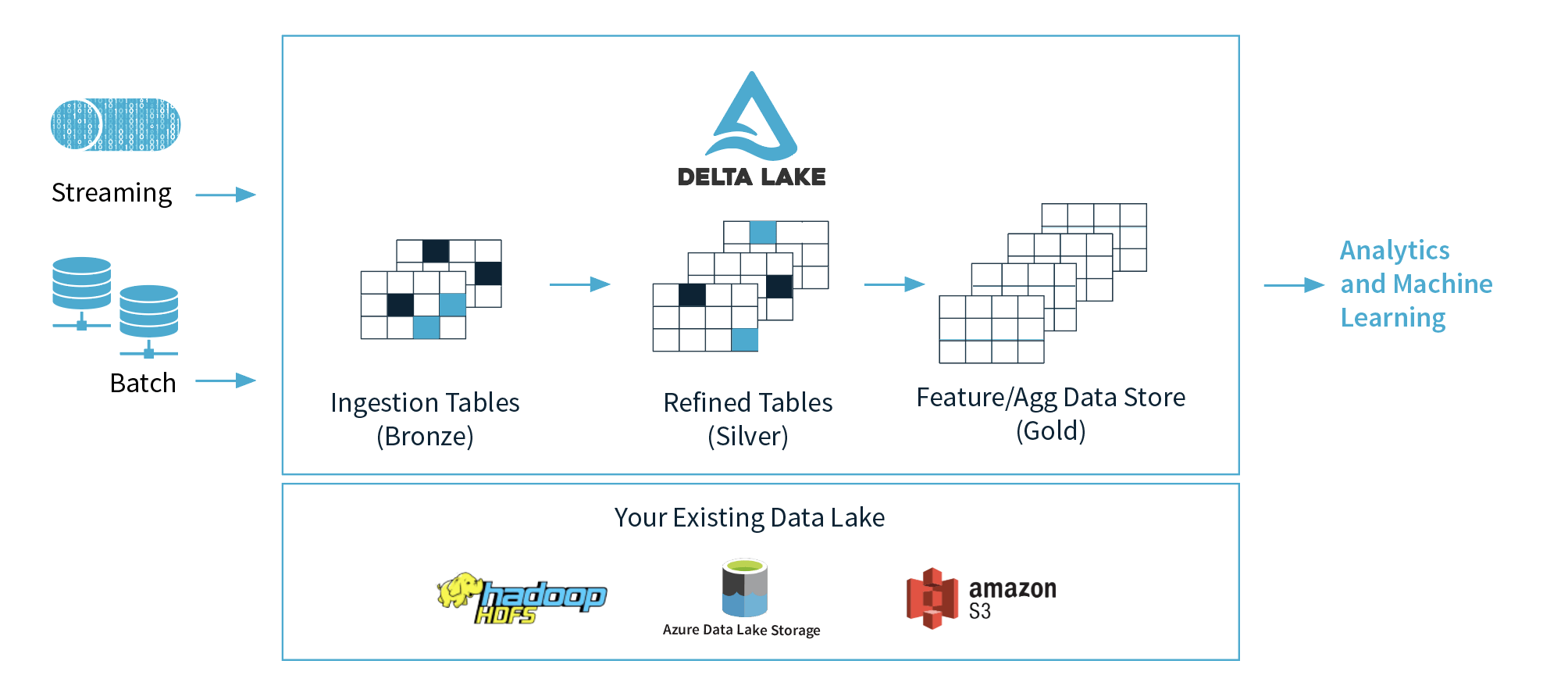
1) Блок данных предлагает 3 слоя (бронза, серебро, золото), но какой слой рекомендуется использовать для машинного обучения и почему? Я предполагаю, что они предлагают, чтобы данные были чистыми и готовыми в золотом слое.
2) Если мы абстрагируем понятия этих трех уровней, можем ли мы рассматривать бронзовый слой как озеро данных, серебряный слой как базы данных и золотой слой как хранилище данных? Я имею в виду с точки зрения функциональности.
3) Дельта-архитектура - это коммерческий термин, или это эволюция архитектуры Kappa, или это новая трендовая архитектура, такая как архитектура Lambda и Kappa? Чем отличается архитектура Delta + Lambda от архитектуры Kappa?
4) Во многих случаях Delta + Spark масштабируется намного больше, чем большинство баз данных, как правило, гораздо дешевле, и если мы настроим все правильно, мы сможем получить почти в 2 раза более быстрые результаты запросов. Я знаю, что довольно сложно сравнить фактические хранилища данных с хранилищем Feature/Agg Data Store, но я хотел бы знать, как я могу сделать это сравнение?
5) Раньше я использовал Kafka, Kinesis или Event Hub для потокового процесса, и мой вопрос в том, какие проблемы могут возникнуть, если мы заменим эти инструменты таблицей Delta Lake (я уже знаю, что все зависит от многих вещей, но я хотел бы иметь общее видение этого).
1 ответ
1) Оставьте это на усмотрение ваших ученых. Им должно быть удобно работать в серебряном и золотом регионах, некоторые более продвинутые ученые по изучению данных захотят вернуться к необработанным данным и проанализировать дополнительную информацию, которая, возможно, не была включена в серебряные / золотые таблицы.
2) Бронза = необработанные данные в собственном формате / в формате дельты озера. Серебро = очищенные и очищенные данные в дельте озера. Золото = данные, к которым осуществляется доступ через озеро дельты или отправляются в хранилище данных, в зависимости от требований бизнеса.
3) Дельта-архитектура - это простая версия лямбда-архитектуры. На данном этапе архитектура Delta - это коммерческий термин, и мы увидим, изменится ли он в будущем.
4) Delta Lake + Spark - самый масштабируемый механизм хранения данных с разумной ценой. Вы можете протестировать производительность в соответствии с требованиями вашего бизнеса. Озеро Дельта будет намного дешевле, чем любое хранилище данных для хранения. Ваши требования относительно доступа к данным и задержек будут более важным вопросом.
5) Kafka, Kinesis или Eventhub являются источниками для получения данных от края до озера данных. Озеро Дельта может выступать в качестве источника и впадать в потоковое приложение. На самом деле проблем с использованием дельты в качестве источника очень мало. Источник Delta Lake живет в хранилище больших двоичных объектов, поэтому мы фактически обходим многие проблемы инфраструктуры, но добавим проблемы согласованности хранилища больших двоичных объектов. Озеро Delta как источник потоковых заданий гораздо более масштабируемо, чем концентратор событий kafka / kinesis /, но вам все еще нужны эти инструменты для передачи данных с края в озеро дельты.
Таблицы с медальонами - это рекомендации, основанные на том, как наши клиенты используют озеро Дельта. Вам не обязательно точно следовать ему; тем не менее, это хорошо согласуется с тем, как люди проектируют EDW. Что касается машинного обучения и какую таблицу использовать. Это будет выбор тех, кто занимается машинным обучением. Некоторые могут захотеть получить доступ к таблицам Bronze, потому что это необработанные данные, с ними ничего не было сделано. Другим может понадобиться Серебряный стол, потому что он считается чистым, хотя и дополненным. Обычно таблицы Gold содержат подробные ответы на четко определенные бизнес-вопросы.
Не совсем. Таблицы Bronze - это необработанные данные о событиях, например, одна строка для каждого события или измерения и т. Д. Таблицы Silver также находятся на уровне событий / измерений, но они очень усовершенствованы и готовы к запросам, отчетам, информационным панелям и т. Д. Таблица может быть таблицами фактов и измерений, сводными таблицами или тщательно подобранными наборами данных. Важно помнить, что Delta не предназначена для использования в качестве транснациональной OLTP-системы. Он действительно предназначен для рабочих нагрузок OLAP.
Архитектура Delta - это название, которое мы дали конкретной реализации Delta Lake. Это не коммерческий термин как таковой, но, надеюсь, он им станет. Существует достаточно информации, чтобы сравнить и сопоставить архитектуры Kappa и Lambda. Архитектура Delta четко описана в документации Delta и блогах Databricks, технических обсуждениях, видео на YouTube и т. Д.
Я бы спросил, что именно вы хотите сравнить? Скорость, особенности, продукты,...?
Delta Lake не пытается заменить какие-либо системы обмена сообщениями, у них разные варианты использования. Delta Lake может подключаться к каждому из продуктов, упомянутых вами как подписчик и издатель. Не забывайте, что Delta Lake - это открытый уровень хранения, который обеспечивает ACID-совместимые транзакции, высокую производительность и высокую надежность для озер данных.
Луи.