Суммирование данных в кросс-таблице с переменной grouped_by в столбцах
Я пытаюсь суммировать данные по двум переменным, и вывод с суммированием является очень коротким (по крайней мере, в выводе r блокнота, где таблица разбита на несколько страниц). Я хотел бы иметь одну переменную в качестве строк итогового вывода, а другую - в качестве столбцов, а затем в фактической таблице средние значения для каждой комбинации данных строк и столбцов. Некоторые примеры данных:
dat1 <- data.frame(
category = rep(c("catA", "catB", "catC"), each=4),
age = sample(1:2,size=4,replace=T),
value = rnorm(12)
)
и тогда я обычно получаю мой итоговый фрейм данных так:
dat1 %>% group_by(category,age)%>% summarize(mean(value))
который выглядит так: 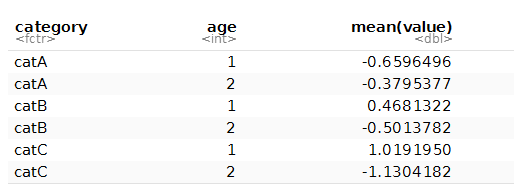
но в моих реальных данных каждая из переменных имеет более 10 уровней, поэтому таблица очень длинная и трудная для чтения. Я бы предпочел что-то вроде этого, которое я создал с помощью:
dat1 %>% group_by(category)
%>% summarize(mean.age1 =mean(value[age==1]),
mean.age2 =mean(value[age==2]))
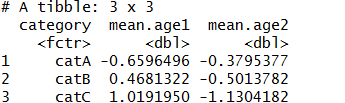
Должен быть лучший способ, чем ручное кодирование означает столбец?
1 ответ
Вам просто нужно использовать tidyr кроме того, чтобы сделать что-то вроде этого:
library(dplyr)
library(tidyr)
dat1 %>%
group_by(category, age) %>%
summarise(mean = mean(value)) %>%
spread(age, mean, sep = '')
Вывод следующий:
Source: local data frame [3 x 3]
Groups: category [3]
category age1 age2
* <fctr> <dbl> <dbl>
1 catA 0.2930104 0.3861381
2 catB 0.5752186 0.1454201
3 catC 1.0845645 0.3117227