Добавочная загрузка AzureDataFactory с использованием Python
Как мне создать Azure Datafactory для инкрементальной загрузки с использованием Python? где я должен упомянуть параметр загрузки файла (Incremental Load:LastModifiedOn) при создании операции или конвейера??
мы можем сделать это с помощью пользовательского интерфейса, выбрав File Load Option. но как сделать то же самое прагматично, используя python?
Python api для datafactory поддерживает это или нет?
2 ответа
Мои исследования показывают, что в Python SDK эта функция еще не реализована. Я использовал SDK для подключения к существующему экземпляру и получил два примера наборов данных. Я не нашел ничего похожего на "дату последнего изменения". Я старался dataset.serialize(), dataset.__dict__, dataset.properties.__dict__, Я тоже пробовал .__slots__,
Попытка serialize() важно, потому что должен быть паритет между JSON, сгенерированным в GUI, и JSON, сгенерированным Python. Отсутствие четности предполагает, что версия SDK отстает от версии с графическим интерфейсом.
ОБНОВЛЕНИЕ: группа продуктов работает над проблемой. Будет редактировать здесь с дополнительной информацией.
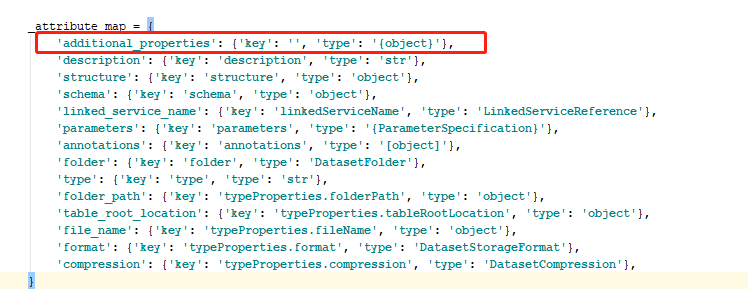
Согласно этому блогу, вы можете получить функцию инкрементальной загрузки только из ADF SDK, установив modifiedDatetimeStart а также modifiedDatetimeEnd свойства.
Вы можете установить вышеуказанные свойства в additional_properties класса azure_blob_dataset.