Swscale - преобразование цвета изображения (NV12) - недопустимая граница
Цель состоит в том, чтобы преобразовать NV12 в изображение BGR24, точнее в патч изображения (x:0, y:0, w:220, h:220).
Проблема заключается в столбце неопределенных пикселей справа от преобразованного патча, как показано ниже: 
Вопрос в том, почему это происходит (хотя координаты и размеры патча имеют четные значения)? (Интересно, что для нечетного значения ширины эта проблема отсутствует)
Патч имеет следующую ограничивающую рамку: (x:0, y:0, w:220, h:220).
Поведение должно быть воспроизводимо с любым изображением. Преобразование может быть сделано, используя страницу преобразования ppm.
Следующий код создает изображение nv12 из изображения bgr24, а затем преобразует патч nv12 обратно в патч bgr24. Если все работает правильно, вывод должен быть идентичен исходному изображению.
#include <libswscale/swscale.h>
#include <libavutil/imgutils.h>
void readPPM(const char* filename, uint8_t** bgrData, int* stride, int* w, int* h)
{
FILE* fp = fopen(filename, "rb");
fscanf(fp, "%*s\n"); //skip format check
fscanf(fp, "%d %d\n", w, h);
fscanf(fp, "%*d\n"); //skip max value check
*stride = *w * 3;
*bgrData = av_malloc(*h * *stride);
for (int r = 0; r < *h; r++)
{
uint8_t* rowData = *bgrData + r * *stride;
for (int c = 0; c < *w; c++)
{
//rgb -> bgr
fread(&rowData[2], 1, 1, fp);
fread(&rowData[1], 1, 1, fp);
fread(&rowData[0], 1, 1, fp);
rowData += 3;
}
}
fclose(fp);
}
void writePPM(const char* filename, uint8_t* bgrData, int stride, int w, int h)
{
FILE* fp = fopen(filename, "wb");
fprintf(fp, "P6\n");
fprintf(fp, "%d %d\n", w, h);
fprintf(fp, "%d\n", 255);
for (int r = 0; r < h; r++)
{
uint8_t* rowData = bgrData + r * stride;
for (int c = 0; c < w; c++)
{
//bgr -> rgb
fwrite(&rowData[2], 1, 1, fp);
fwrite(&rowData[1], 1, 1, fp);
fwrite(&rowData[0], 1, 1, fp);
rowData += 3;
}
}
fclose(fp);
}
void bgrToNV12(uint8_t* srcData[4], int srcStride[4],
uint8_t* tgtData[4], int tgtStride[4],
int w, int h)
{
struct SwsContext* context = sws_getContext(w, h, AV_PIX_FMT_BGR24,
w, h, AV_PIX_FMT_NV12, SWS_POINT, NULL, NULL, NULL);
{
sws_scale(context,
srcData, srcStride, 0, h,
tgtData, tgtStride);
}
sws_freeContext(context);
}
void nv12ToBgr(uint8_t* srcData[4], int srcStride[4],
uint8_t* tgtData[4], int tgtStride[4],
int w, int h)
{
struct SwsContext* context = sws_getContext(w, h, AV_PIX_FMT_NV12,
w, h, AV_PIX_FMT_BGR24, SWS_POINT, NULL, NULL, NULL);
{
sws_scale(context,
srcData, srcStride, 0, h,
tgtData, tgtStride);
}
sws_freeContext(context);
}
int main()
{
//load BGR image
uint8_t* bgrData[4]; int bgrStride[4]; int bgrW, bgrH;
readPPM("sample.ppm", &bgrData[0], &bgrStride[0], &bgrW, &bgrH);
//create NV12 image from the BGR image
uint8_t* nv12Data[4]; int nv12Stride[4];
av_image_alloc(nv12Data, nv12Stride, bgrW, bgrH, AV_PIX_FMT_NV12, 16);
bgrToNV12(bgrData, bgrStride, nv12Data, nv12Stride, bgrW, bgrH);
//convert nv12 patch to bgr patch
nv12ToBgr(nv12Data, nv12Stride, bgrData, bgrStride, 220, 220); //invalid result (random column stripe)
//nv12ToBgr(nv12Data, nv12Stride, bgrData, bgrStride, 221, 220); //valid result
//save bgr image (should be exactly as original BGR image)
writePPM("sample-out.ppm", bgrData[0], bgrStride[0], bgrW, bgrH);
//cleanup
av_freep(bgrData);
av_freep(nv12Data);
return 0;
}
0 ответов
Sws _scale выполняет преобразование цвета и масштабирование одновременно.
Большинство используемых алгоритмов должны включать соседние пиксели в расчет целевого пикселя. Конечно, это может привести к проблемам по краям, если размеры изображения не кратны x. Где x зависит от используемых алгоритмов.
Если вы установите здесь размеры изображения, кратные 8 (следующее кратное 8 = 224), то оно будет работать без артефактов.
nv12ToBgr(nv12Data, nv12Stride, bgrData, bgrStride, 224, 224);
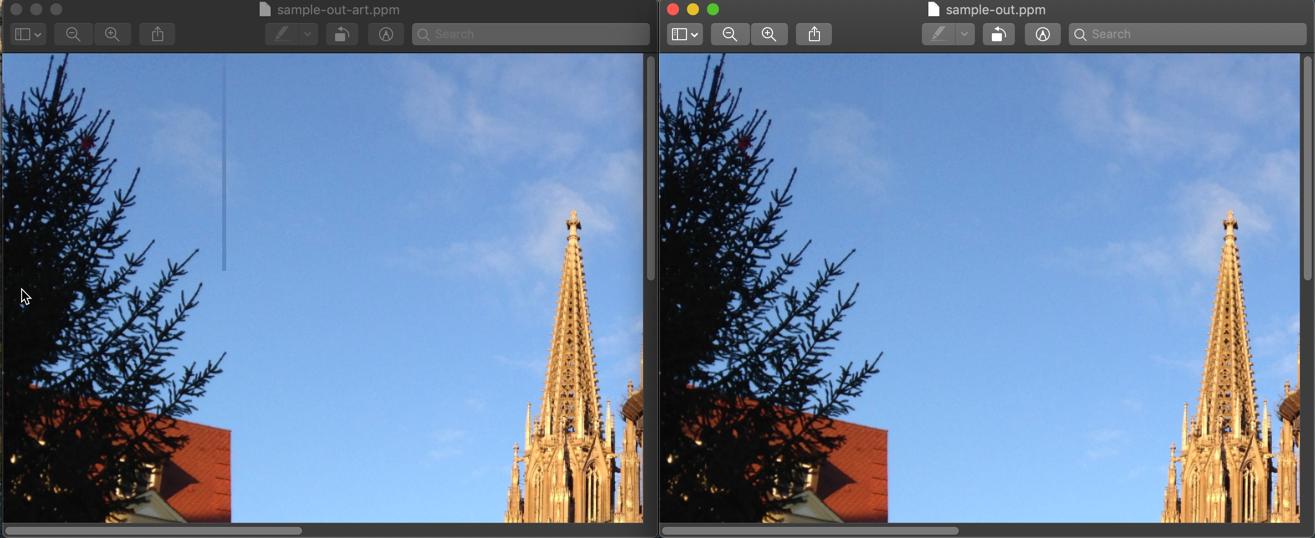
Демо
Использование размеров изображения 220 x 220 слева дает артефакт на правом краю преобразованного фрагмента.
Если выбрать 224 x 224, артефакт не будет, см. Правое изображение на снимке экрана, где сравниваются обе процедуры.
Теоретически необходимое минимальное выравнивание
Давайте посмотрим на формат YVU420:
Значения яркости определяются для каждого пикселя. Информация о цвете, которая разделена на Cb и Cr, вычисляется из блока пикселей 2x2. Таким образом, минимальным размером изображения будет блок изображения 2 x 2, в результате чего получается 6 байтов (т.е. 12 пикселей на байт = 12 * 4 = 48 бит = 6 байтов), см. Рисунок здесь:
Таким образом, минимальное техническое требование - это равномерная ширина и высота изображения.
Вы определили флаг SWS_POINT для масштабирования, т. Е. Используется метод ближайшего соседа. Таким образом, теоретически для каждого выходного пикселя определяется и используется ближайший входной пиксель, что не вызывает каких-либо ограничений выравнивания.
Спектакль
Однако важным аспектом реальной реализации алгоритмов зачастую является производительность. В этом случае, например, можно обрабатывать сразу несколько соседних пикселей. Также не забывайте о возможности аппаратного ускорения операций.
Альтернативное решение
Если по какой-то причине вам нужно придерживаться формата 220x220, вы также можете использовать флаг SWS_BITEXACT.
Оно делает:
Разрешить битовый вывод.
см. https://ffmpeg.org/ffmpeg-scaler.html
Итак, в nv12ToBgr вы должны использовать что-то вроде:
struct SwsContext* context = sws_getContext(w, h, AV_PIX_FMT_NV12,
w, h, AV_PIX_FMT_BGR24, SWS_POINT | SWS_BITEXACT, NULL, NULL, NULL);
Это тоже не дает никаких артефактов. Если вам нужно конвертировать много кадров, я бы посмотрел на производительность.