При извлечении данных из этого PDF с помощью Camelot не найдено таблиц и объединен текст столбца.
Я получаю UserWarning: No tables found on page-1 когда я пытаюсь извлечь таблицы из прилагаемого PDF . Однако когда я посмотрел на извлеченные данные, часть текста столбца была объединена в один столбец ".
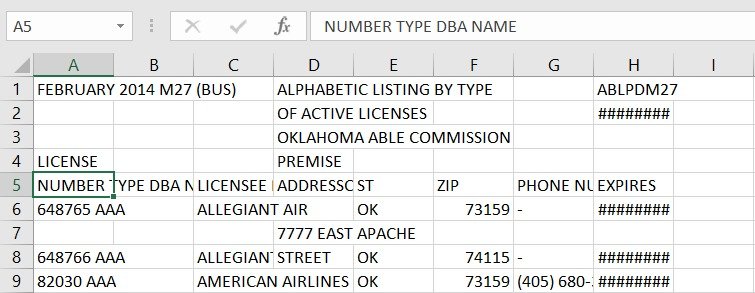
Я использую Камелот для разбора этих PDF-файлов
Действия по воспроизведению: camelot --output m27.csv --format csv stream m27.pdf
Вот ссылка на PDF, которую я пытаюсь проанализировать: https://github.com/tabulapdf/tabula-java/blob/master/src/test/resources/technology/tabula/m27.pdf
1 ответ
PDF-файл просто содержит инструкции по размещению символа в координатах x,y на двухмерной плоскости, не сохраняя знания слов, предложений или таблиц.
Camelot использует PDFMiner для группирования символов в слова и слов в предложения. Иногда, когда символы расположены слишком близко, PDFMiner может группировать символы, принадлежащие разным словам, в один.
Поскольку символы в вашей таблице PDF располагаются очень близко, они объединяются в одно слово, и, следовательно, Камелот не может правильно определять столбцы. Вы можете указать разделители столбцов, чтобы получить таблицу в этом случае. Чтобы получить x-координаты разделителей столбцов, вы можете обратиться к визуальному руководству по отладке. Кроме того, вы можете указать split_text=True вырезать слово по указанным разделителям столбцов. Вот код (я получил x-координаты, создав Matplotlib сюжет текста в PDF, используя $ camelot stream -plot text m27.pdf):
Используя CLI:
$ camelot --output m27.csv --format csv -split stream -C 72,95,209,327,442,529,566,606,683 m27.pdf
Используя API:
>>> import camelot
>>> tables = camelot.read_pdf('m27.pdf', flavor='stream', columns=['72,95,209,327,442,529,566,606,683'], split_text=True)