Проблема обнаружения текста MSER
Я пытаюсь использовать алгоритм MSER для обнаружения текста. Я использую этот код:
import cv2
import numpy as np
#Create MSER object
mser = cv2.MSER_create()
#Your image path i-e receipt path
img = cv2.imread('test.jpg')
#Convert to gray scale
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
vis = img.copy()
#detect regions in gray scale image
regions, _ = mser.detectRegions(gray)
hulls = [cv2.convexHull(p.reshape(-1, 1, 2)) for p in regions]
cv2.polylines(vis, hulls, 1, (0, 255, 0))
cv2.imshow('img', vis)
cv2.waitKey(0)
mask = np.zeros((img.shape[0], img.shape[1], 1), dtype=np.uint8)
for contour in hulls:
cv2.drawContours(mask, [contour], -1, (255, 255, 255), -1)
#this is used to find only text regions, remaining are ignored
text_only = cv2.bitwise_and(img, img, mask=mask)
cv2.imshow("text only", text_only)
cv2.waitKey(0)
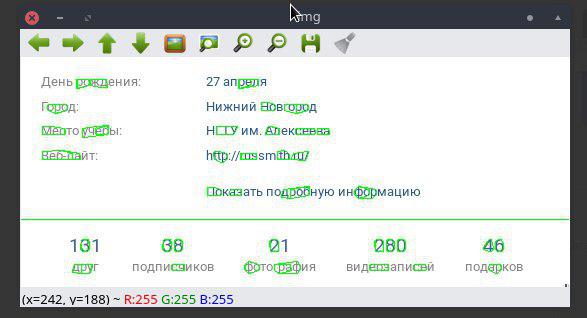
Но я получаю очень интересные результаты. MSER не может обнаружить весь текст на изображении.
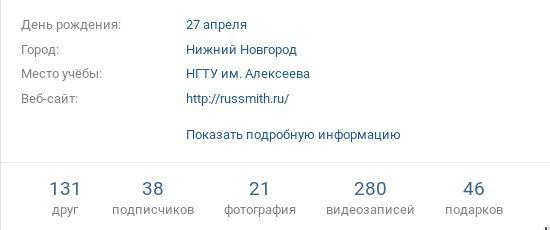
Тестовое изображение: https://st ackru.com/images/91feb167c454f07fb4750ad865715b9fbb0f8b38.jpg
{kind=link}
Результат изображения: https://st ackru.com/images/4b2fa9fc73608a480314c7d5cd1b221b9355dbc4.jpg
{kind=link}
Что я делаю неправильно?
1 ответ
Текстовый модуль OpenCV содержит несколько методов для обнаружения текста. Для вашего примера самый простой метод - это пример ERFilterNM - python. Увидимся на результат обнаружения для экрана PNG: https://stackru.com/image s/038db631a39f2b459001d43519d5fd205dc84ea4.png Параметры:
er1 = cv.text.createERFilterNM1(erc1,6,0.00005f,0.08f,0.2f,true,0.1f)
er2 = cv.text.createERFilterNM2(erc1,0.15)