Разделение словаря / списка внутри столбца панд на отдельные столбцы
У меня есть данные, сохраненные в базе данных postgreSQL. Я запрашиваю эти данные с помощью Python2.7 и превращаю их в Pandas DataFrame. Однако последний столбец этого информационного кадра содержит словарь (или список?) Значений внутри него. DataFrame выглядит так:
[1] df
Station ID Pollutants
8809 {"a": "46", "b": "3", "c": "12"}
8810 {"a": "36", "b": "5", "c": "8"}
8811 {"b": "2", "c": "7"}
8812 {"c": "11"}
8813 {"a": "82", "c": "15"}
Мне нужно разделить этот столбец на отдельные столбцы, чтобы DataFrame выглядел следующим образом:
[2] df2
Station ID a b c
8809 46 3 12
8810 36 5 8
8811 NaN 2 7
8812 NaN NaN 11
8813 82 NaN 15
Основная проблема у меня заключается в том, что списки не имеют одинаковую длину. Но все списки содержат только до 3 одинаковых значений: a, b и c. И они всегда появляются в одном и том же порядке (первое, второе, третье).
Следующий код используется для работы и вернуть именно то, что я хотел (df2).
[3] df
[4] objs = [df, pandas.DataFrame(df['Pollutant Levels'].tolist()).iloc[:, :3]]
[5] df2 = pandas.concat(objs, axis=1).drop('Pollutant Levels', axis=1)
[6] print(df2)
Я запускал этот код только на прошлой неделе, и он работал нормально. Но теперь мой код не работает, и я получаю эту ошибку из строки [4]:
IndexError: out-of-bounds on slice (end)
Я не сделал никаких изменений в коде, но теперь получаю ошибку. Я чувствую, что это из-за того, что мой метод не является надежным или правильным.
Любые предложения или рекомендации о том, как разбить этот столбец списков на отдельные столбцы, будут очень признательны!
РЕДАКТИРОВАТЬ: Я думаю, что методы.tolist() и.apply не работают на моем коде, потому что это одна строка Unicode, то есть:
#My data format
u{'a': '1', 'b': '2', 'c': '3'}
#and not
{u'a': '1', u'b': '2', u'c': '3'}
Данные импортируются из базы данных postgreSQL в этом формате. Любая помощь или идеи по этому вопросу? Есть ли способ конвертировать Unicode?
14 ответов
Чтобы преобразовать строку в фактический DICT, вы можете сделать df['Pollutant Levels'].map(eval), После этого решение, приведенное ниже, можно использовать для преобразования dict в разные столбцы.
Используя небольшой пример, вы можете использовать .apply(pd.Series):
In [2]: df = pd.DataFrame({'a':[1,2,3], 'b':[{'c':1}, {'d':3}, {'c':5, 'd':6}]})
In [3]: df
Out[3]:
a b
0 1 {u'c': 1}
1 2 {u'd': 3}
2 3 {u'c': 5, u'd': 6}
In [4]: df['b'].apply(pd.Series)
Out[4]:
c d
0 1.0 NaN
1 NaN 3.0
2 5.0 6.0
Чтобы объединить его с остальными данными, вы можете concat другие столбцы с приведенным выше результатом:
In [7]: pd.concat([df.drop(['b'], axis=1), df['b'].apply(pd.Series)], axis=1)
Out[7]:
a c d
0 1 1.0 NaN
1 2 NaN 3.0
2 3 5.0 6.0
Используя ваш код, это также работает, если я опущу iloc часть:
In [15]: pd.concat([df.drop('b', axis=1), pd.DataFrame(df['b'].tolist())], axis=1)
Out[15]:
a c d
0 1 1.0 NaN
1 2 NaN 3.0
2 3 5.0 6.0
Я знаю, что вопрос довольно старый, но я попал сюда в поисках ответов. На самом деле есть лучший (и более быстрый) способ сделать это, используя json_normalize:
import pandas as pd
from pandas.io.json import json_normalize
df2 = json_normalize(df['Pollutant Levels'])
Это позволяет избежать дорогостоящих применений функций...
pd.json_normalize(df.Pollutants)значительно быстрее, чемdf.Pollutants.apply(pd.Series)- Увидеть
%%timeitниже. Для 1 млн строк.json_normalizeв 47 раз быстрее, чем.apply.
- Увидеть
- При чтении данных из файла, из объекта, возвращаемого базой данных или API, может быть неясно,
dictстолбец имеетdictилиstrтип.- Если словари в столбце являются строками, их необходимо преобразовать обратно в
dictтип, используяast.literal_eval.
- Если словари в столбце являются строками, их необходимо преобразовать обратно в
- Использовать
pd.json_normalizeпреобразоватьdicts, с участиемkeysкак заголовки иvaluesдля рядов.- Имеет дополнительные параметры (например,
record_path&meta) для работы с вложеннымиdicts.
- Имеет дополнительные параметры (например,
- Использовать
pandas.DataFrame.joinчтобы объединить исходный DataFrame,df, со столбцами, созданными с помощьюpd.json_normalize- Если индекс не является целым числом (как в примере), сначала используйте
df.reset_index()чтобы получить индекс целых чисел, прежде чем выполнять нормализацию и соединение.
- Если индекс не является целым числом (как в примере), сначала используйте
- Наконец, используйте
pandas.DataFrame.drop, чтобы удалить ненужный столбецdicts
import pandas as pd
from ast import literal_eval
data = {'Station ID': [8809, 8810, 8811, 8812, 8813],
'Pollutants': ['{"a": "46", "b": "3", "c": "12"}', '{"a": "36", "b": "5", "c": "8"}', '{"b": "2", "c": "7"}', '{"c": "11"}', '{"a": "82", "c": "15"}']}
df = pd.DataFrame(data)
# display(df)
Station ID Pollutants
0 8809 {"a": "46", "b": "3", "c": "12"}
1 8810 {"a": "36", "b": "5", "c": "8"}
2 8811 {"b": "2", "c": "7"}
3 8812 {"c": "11"}
4 8813 {"a": "82", "c": "15"}
# Convert the column of stringified dicts to dicts
# skip this line, if the column contains dicts
df.Pollutants = df.Pollutants.apply(literal_eval)
# reset the index if the index is not unique integers from 0 to n-1
# df.reset_index(inplace=True) # uncomment if needed
# normalize the column of dictionaries and join it to df
df = df.join(pd.json_normalize(df.Pollutants))
# drop Pollutants
df.drop(columns=['Pollutants'], inplace=True)
# display(df)
Station ID a b c
0 8809 46 3 12
1 8810 36 5 8
2 8811 NaN 2 7
3 8812 NaN NaN 11
4 8813 82 NaN 15
%%timeit
# dataframe with 1M rows
dfb = pd.concat([df]*200000).reset_index(drop=True)
%%timeit
dfb.join(pd.json_normalize(dfb.Pollutants))
[out]:
5.44 s ± 32.3 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%%timeit
pd.concat([dfb.drop(columns=['Pollutants']), dfb.Pollutants.apply(pd.Series)], axis=1)
[out]:
4min 17s ± 2.44 s per loop (mean ± std. dev. of 7 runs, 1 loop each)
Попробуйте это: данные, возвращаемые из SQL, должны быть преобразованы в Dict. или это может быть "Pollutant Levels" сейчас Pollutants'
StationID Pollutants
0 8809 {"a":"46","b":"3","c":"12"}
1 8810 {"a":"36","b":"5","c":"8"}
2 8811 {"b":"2","c":"7"}
3 8812 {"c":"11"}
4 8813 {"a":"82","c":"15"}
df2["Pollutants"] = df2["Pollutants"].apply(lambda x : dict(eval(x)) )
df3 = df2["Pollutants"].apply(pd.Series )
a b c
0 46 3 12
1 36 5 8
2 NaN 2 7
3 NaN NaN 11
4 82 NaN 15
result = pd.concat([df, df3], axis=1).drop('Pollutants', axis=1)
result
StationID a b c
0 8809 46 3 12
1 8810 36 5 8
2 8811 NaN 2 7
3 8812 NaN NaN 11
4 8813 82 NaN 15
Как разделить столбец словарей на отдельные столбцы с пандами?
pd.DataFrame(df['val'].tolist()) канонический метод расчленения столбца словарей
Вот ваше доказательство с использованием красочного графика.
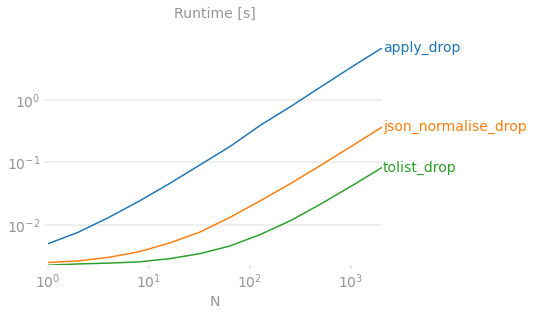
Код эталонного тестирования для справки.
Обратите внимание, что я всего лишь рассчитываю время взрыва, поскольку это самая интересная часть ответа на этот вопрос - другие аспекты построения результата (например, использовать ли или) не имеют отношения к обсуждению и могут быть проигнорированы (однако следует отметить, что использование позволяет избежать следовать до
drop call, поэтому окончательное решение будет немного более производительным, но мы по-прежнему прослушиваем столбец и передаем его в любую сторону).
Кроме того,
pop деструктивно изменяет входной DataFrame, что затрудняет выполнение кода тестирования, который предполагает, что входные данные не меняются при выполнении тестов.
Критика других решений
df['val'].apply(pd.Series)является чрезвычайно медленным для больших N, поскольку pandas создает объекты Series для каждой строки, а затем переходит к построению DataFrame из них. Для больших N производительность падает до минут или часов.pd.json_normalize(df['val']))медленнее просто потому, чтоjson_normalizeпредназначен для работы с гораздо более сложными входными данными, особенно с глубоко вложенным JSON с несколькими путями записи и метаданными. У нас есть простой плоский диктант, для которогоpd.DataFrameдостаточно, поэтому используйте это, если у вас плоские dicts.Некоторые ответы предполагают
df.pop('val').values.tolist()или жеdf.pop('val').to_numpy().tolist(). Я не думаю, что это имеет большое значение, просматриваете ли вы серию или массив numpy. Это на одну операцию меньше, чтобы просмотреть серию напрямую, и действительно не медленнее, поэтому я бы рекомендовал избегать создания массива numpy на промежуточном этапе.
>>> df
Station ID Pollutants
0 8809 {"a": "46", "b": "3", "c": "12"}
1 8810 {"a": "36", "b": "5", "c": "8"}
2 8811 {"b": "2", "c": "7"}
3 8812 {"c": "11"}
4 8813 {"a": "82", "c": "15"}
сравнение скорости для большого набора данных из 10 миллионов строк
>>> df = pd.concat([df]*100000).reset_index(drop=True)
>>> df = pd.concat([df]*20).reset_index(drop=True)
>>> print(df.shape)
(10000000, 2)
def apply_drop(df):
return df.join(df['Pollutants'].apply(pd.Series)).drop('Pollutants', axis=1)
def json_normalise_drop(df):
return df.join(pd.json_normalize(df.Pollutants)).drop('Pollutants', axis=1)
def tolist_drop(df):
return df.join(pd.DataFrame(df['Pollutants'].tolist())).drop('Pollutants', axis=1)
def vlues_tolist_drop(df):
return df.join(pd.DataFrame(df['Pollutants'].values.tolist())).drop('Pollutants', axis=1)
def pop_tolist(df):
return df.join(pd.DataFrame(df.pop('Pollutants').tolist()))
def pop_values_tolist(df):
return df.join(pd.DataFrame(df.pop('Pollutants').values.tolist()))
>>> %timeit apply_drop(df.copy())
1 loop, best of 3: 53min 20s per loop
>>> %timeit json_normalise_drop(df.copy())
1 loop, best of 3: 54.9 s per loop
>>> %timeit tolist_drop(df.copy())
1 loop, best of 3: 6.62 s per loop
>>> %timeit vlues_tolist_drop(df.copy())
1 loop, best of 3: 6.63 s per loop
>>> %timeit pop_tolist(df.copy())
1 loop, best of 3: 5.99 s per loop
>>> %timeit pop_values_tolist(df.copy())
1 loop, best of 3: 5.94 s per loop
+---------------------+-----------+
| apply_drop | 53min 20s |
| json_normalise_drop | 54.9 s |
| tolist_drop | 6.62 s |
| vlues_tolist_drop | 6.63 s |
| pop_tolist | 5.99 s |
| pop_values_tolist | 5.94 s |
+---------------------+-----------+
df.join(pd.DataFrame(df.pop('Pollutants').values.tolist()))самый быстрый
Я настоятельно рекомендую метод извлечения столбца "Загрязнители":
df_pollutants = pd.DataFrame(df['Pollutants'].values.tolist(), index=df.index)
это намного быстрее чем
df_pollutants = df['Pollutants'].apply(pd.Series)
когда размер df гигантский.
Ответ Мерлина лучше и супер прост, но нам не нужна лямбда-функция. Оценка словаря может быть безопасно проигнорирована, как показано ниже:
df_pol_ps = data_df['Pollutants'].apply(pd.Series)
df_pol_ps:
a b c
0 46 3 12
1 36 5 8
2 NaN 2 7
3 NaN NaN 11
4 82 NaN 15
df_final = pd.concat([df, df_pol_ps], axis = 1).drop('Pollutants', axis = 1)
df_final:
StationID a b c
0 8809 46 3 12
1 8810 36 5 8
2 8811 NaN 2 7
3 8812 NaN NaN 11
4 8813 82 NaN 15
Вышеупомянутые два шага могут быть объединены за один раз:
df_final = pd.concat([df, df['Pollutants'].apply(pd.Series)], axis = 1).drop('Pollutants', axis = 1)
df_final:
StationID a b c
0 8809 46 3 12
1 8810 36 5 8
2 8811 NaN 2 7
3 8812 NaN NaN 11
4 8813 82 NaN 15
Ты можешь использовать join с pop + tolist, Производительность сопоставима с concat с drop + tolist, но некоторые могут найти этот очиститель синтаксиса:
res = df.join(pd.DataFrame(df.pop('b').tolist()))
Сравнительный анализ с другими методами:
df = pd.DataFrame({'a':[1,2,3], 'b':[{'c':1}, {'d':3}, {'c':5, 'd':6}]})
def joris1(df):
return pd.concat([df.drop('b', axis=1), df['b'].apply(pd.Series)], axis=1)
def joris2(df):
return pd.concat([df.drop('b', axis=1), pd.DataFrame(df['b'].tolist())], axis=1)
def jpp(df):
return df.join(pd.DataFrame(df.pop('b').tolist()))
df = pd.concat([df]*1000, ignore_index=True)
%timeit joris1(df.copy()) # 1.33 s per loop
%timeit joris2(df.copy()) # 7.42 ms per loop
%timeit jpp(df.copy()) # 7.68 ms per loop
Однострочное решение следующее:
>>> df = pd.concat([df['Station ID'], df['Pollutants'].apply(pd.Series)], axis=1)
>>> print(df)
Station ID a b c
0 8809 46 3 12
1 8810 36 5 8
2 8811 NaN 2 7
3 8812 NaN NaN 11
4 8813 82 NaN 15
В одну строку:
df = pd.concat([df['a'], df.b.apply(pd.Series)], axis=1)`
Я объединил эти шаги в методе, вам нужно передать только фрейм данных и столбец, который содержит dict для расширения:
def expand_dataframe(dw: pd.DataFrame, column_to_expand: str) -> pd.DataFrame:
"""
dw: DataFrame with some column which contain a dict to expand
in columns
column_to_expand: String with column name of dw
"""
import pandas as pd
def convert_to_dict(sequence: str) -> Dict:
import json
s = sequence
json_acceptable_string = s.replace("'", "\"")
d = json.loads(json_acceptable_string)
return d
expanded_dataframe = pd.concat([dw.drop([column_to_expand], axis=1),
dw[column_to_expand]
.apply(convert_to_dict)
.apply(pd.Series)],
axis=1)
return expanded_dataframe
my_df = pd.DataFrame.from_dict(my_dict, orient='index', columns=['my_col'])
.. правильно проанализировал бы dict (поместив каждый ключ dict в отдельный столбец df, а значения ключей - в строки df), так что dicts не были бы сжаты в один столбец в первую очередь.
ниже решение сработало для меня
pol_df = df['Pollutants'].to_frame()
final_df = pol_df.Pollutants.apply(pd.Series)