Панды, Excel-Import и MultiIndex
Я новичок в пандах и в настоящее время пытаюсь провести некоторый анализ Excel-данных в следующей схеме:
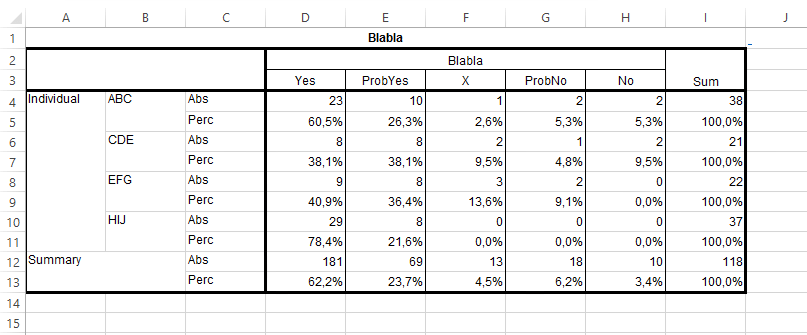
Моя цель - визуализация с помощью индексных меток. XYZ, CDE, EFG, HU на оси х и соответствующие Perc-значения Yes, ProbYes, X, ProbNo, No сложены по оси Y.
Сейчас я разбираю Excel-данные в панде DataFrame через код:
import pandas as pd
path = 'x1.xlsx'
x = pd.ExcelFile(path)
sheets = x.sheet_names
table = x.parse(sheets[0], header=2) # take line 2 as column-names
Сгенерированный MultiIndex из table вроде бы нормально
>>> table.index
MultiIndex(levels=[[u'Individual', u'Summary'], [u'ABC', u'CDE', u'EFG', u'HIJ'], [u'Abs', u'Perc']], labels=[[0, -1, -1, -1, -1, -1, -1, -1, 1, -1], [0, -1, 1, -1, 2, -1, 3, -1, -1, -1], [0, 1, 0, 1, 0, 1, 0, 1, 0, 1]])
Однако невозможно получить доступ к определенной строке:
>>> table.ix[('Individual', 'CDE')]
KeyError: 'Key length (2) was greater than MultiIndex lexsort depth (0)'
... также невозможно получить доступ или отфильтровать / удалить столбец, содержащий индексы строк
>>> table.index.names
FrozenList([None, None, None])
то есть индексы не имеют имен, и поэтому я не могу получить к ним доступ?
Я попытался упростить структуру данных с помощью альтернативного анализа:
>>> table2 = x.parse(sheets[0], header=2, skiprows=2, parse_cols='B,:I')
это, однако, не очень помогло.
Редактировать:
Это помогает sort:
>>> table.sort(inplace=True)
>>> table[:4]
выходы:

и с этой таблицей я не могу провести анализ...
1 ответ
Думаю после выполнения
table.sort(inplace=True)
вы можете получить доступ
table.ix[('Individual', 'CDE')]
РЕДАКТИРОВАТЬ:
Я знаю, почему - ваш файл Excel объединяет такие ячейки A4:A11, Когда вы загружаете его в панды DataFrame, индекс Individual только в A4 в то время как индексы в A5:A11 являются все nan
Одно из возможных решений:
table =table.reset_index().fillna(method='ffill').set_index(['level_0','level_1','level_2'])
#reset_index() automatically gives column names level_?
Тогда тебе пора
table.ix[('Individual','CDE')]