Добавление уравнения регрессии и R2 на графике
Интересно, как добавить уравнение линии регрессии и R^2 на ggplot, Мой код
library(ggplot2)
df <- data.frame(x = c(1:100))
df$y <- 2 + 3 * df$x + rnorm(100, sd = 40)
p <- ggplot(data = df, aes(x = x, y = y)) +
geom_smooth(method = "lm", se=FALSE, color="black", formula = y ~ x) +
geom_point()
p
Любая помощь будет высоко оценена.
11 ответов
Вот одно решение
# GET EQUATION AND R-SQUARED AS STRING
# SOURCE: http://goo.gl/K4yh
lm_eqn <- function(df){
m <- lm(y ~ x, df);
eq <- substitute(italic(y) == a + b %.% italic(x)*","~~italic(r)^2~"="~r2,
list(a = format(coef(m)[1], digits = 2),
b = format(coef(m)[2], digits = 2),
r2 = format(summary(m)$r.squared, digits = 3)))
as.character(as.expression(eq));
}
p1 <- p + geom_text(x = 25, y = 300, label = lm_eqn(df), parse = TRUE)
РЕДАКТИРОВАТЬ. Я выяснил источник, откуда я выбрал этот код. Вот ссылка на оригинальный пост в ggplot2 гугл группах

Я включил статистику stat_poly_eq() в моей упаковке ggpmisc что позволяет этот ответ:
library(ggplot2)
library(ggpmisc)
df <- data.frame(x = c(1:100))
df$y <- 2 + 3 * df$x + rnorm(100, sd = 40)
my.formula <- y ~ x
p <- ggplot(data = df, aes(x = x, y = y)) +
geom_smooth(method = "lm", se=FALSE, color="black", formula = my.formula) +
stat_poly_eq(formula = my.formula,
aes(label = paste(..eq.label.., ..rr.label.., sep = "~~~")),
parse = TRUE) +
geom_point()
p

Эта статистика работает с любым полиномом без пропущенных терминов и, надеюсь, обладает достаточной гибкостью, чтобы быть в целом полезной. Метки R^2 или скорректированные метки R^2 можно использовать с любой формулой модели, снабженной функцией lm(). Будучи статистикой ggplot, она ведет себя ожидаемым образом как с группами, так и с аспектами.
Пакет "ggpmisc" доступен через CRAN.
Версия 0.2.6 была только что принята в CRAN.
В нем рассматриваются комментарии @shabbychef и @ MYaseen208.
@ MYaseen208 это показывает, как добавить шляпу.
library(ggplot2)
library(ggpmisc)
df <- data.frame(x = c(1:100))
df$y <- 2 + 3 * df$x + rnorm(100, sd = 40)
my.formula <- y ~ x
p <- ggplot(data = df, aes(x = x, y = y)) +
geom_smooth(method = "lm", se=FALSE, color="black", formula = my.formula) +
stat_poly_eq(formula = my.formula,
eq.with.lhs = "italic(hat(y))~`=`~",
aes(label = paste(..eq.label.., ..rr.label.., sep = "~~~")),
parse = TRUE) +
geom_point()
p

@shabbychef Теперь можно сопоставить переменные в уравнении с теми, которые используются для меток оси. Чтобы заменить x, скажем, z, а y на h, можно использовать:
p <- ggplot(data = df, aes(x = x, y = y)) +
geom_smooth(method = "lm", se=FALSE, color="black", formula = my.formula) +
stat_poly_eq(formula = my.formula,
eq.with.lhs = "italic(h)~`=`~",
eq.x.rhs = "~italic(z)",
aes(label = ..eq.label..),
parse = TRUE) +
labs(x = expression(italic(z)), y = expression(italic(h))) +
geom_point()
p

Будучи этими нормальными R разобранными выражениями, греческие буквы теперь могут также использоваться как в лх, так и в правой части уравнения.
[2017-03-08] @elarry Отредактируйте, чтобы более точно ответить на исходный вопрос, показывая, как добавить запятую между метками уравнения и R2.
p <- ggplot(data = df, aes(x = x, y = y)) +
geom_smooth(method = "lm", se=FALSE, color="black", formula = my.formula) +
stat_poly_eq(formula = my.formula,
eq.with.lhs = "italic(hat(y))~`=`~",
aes(label = paste(..eq.label.., ..rr.label.., sep = "*plain(\",\")~")),
parse = TRUE) +
geom_point()
p

Я изменил несколько строк источника stat_smooth и связанные функции, чтобы создать новую функцию, которая добавляет уравнение соответствия и значение R в квадрате. Это будет работать и на фасетных участках!
library(devtools)
source_gist("524eade46135f6348140")
df = data.frame(x = c(1:100))
df$y = 2 + 5 * df$x + rnorm(100, sd = 40)
df$class = rep(1:2,50)
ggplot(data = df, aes(x = x, y = y, label=y)) +
stat_smooth_func(geom="text",method="lm",hjust=0,parse=TRUE) +
geom_smooth(method="lm",se=FALSE) +
geom_point() + facet_wrap(~class)
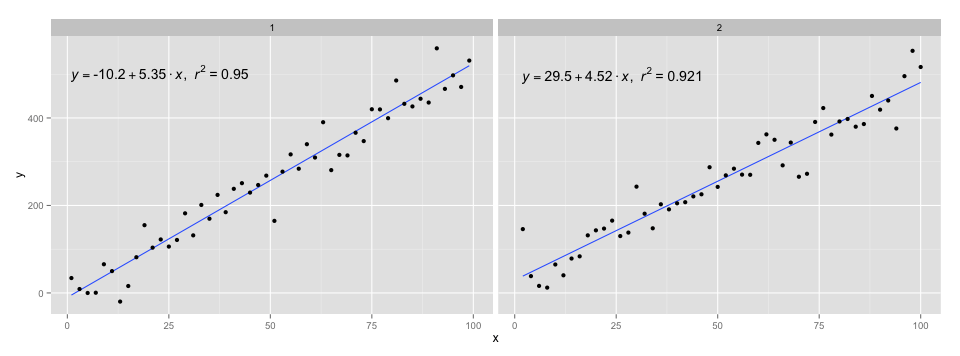
Я использовал код в ответе @Ramnath для форматирования уравнения. stat_smooth_func Функция не очень надежна, но с ней не должно быть проблем.
https://gist.github.com/kdauria/524eade46135f6348140. Попробуйте обновить ggplot2 если вы получили ошибку.
Я изменил пост Рамната: а) сделать более общим, чтобы он принимал линейную модель в качестве параметра, а не фрейм данных, и б) отображал негативы более подходящим образом.
lm_eqn = function(m) {
l <- list(a = format(coef(m)[1], digits = 2),
b = format(abs(coef(m)[2]), digits = 2),
r2 = format(summary(m)$r.squared, digits = 3));
if (coef(m)[2] >= 0) {
eq <- substitute(italic(y) == a + b %.% italic(x)*","~~italic(r)^2~"="~r2,l)
} else {
eq <- substitute(italic(y) == a - b %.% italic(x)*","~~italic(r)^2~"="~r2,l)
}
as.character(as.expression(eq));
}
Использование изменится на:
p1 = p + geom_text(aes(x = 25, y = 300, label = lm_eqn(lm(y ~ x, df))), parse = TRUE)
Вот самый простой код для всех
Примечание. Показан Ро Пирсона, а не R^2.
library(ggplot2)
library(ggpubr)
df <- data.frame(x = c(1:100)
df$y <- 2 + 3 * df$x + rnorm(100, sd = 40)
p <- ggplot(data = df, aes(x = x, y = y)) +
geom_smooth(method = "lm", se=FALSE, color="black", formula = y ~ x) +
geom_point()+
stat_cor(label.y = 35)+ #this means at 35th unit in the y axis, the r squared and p value will be shown
stat_regline_equation(label.y = 30) #this means at 30th unit regresion line equation will be shown
p
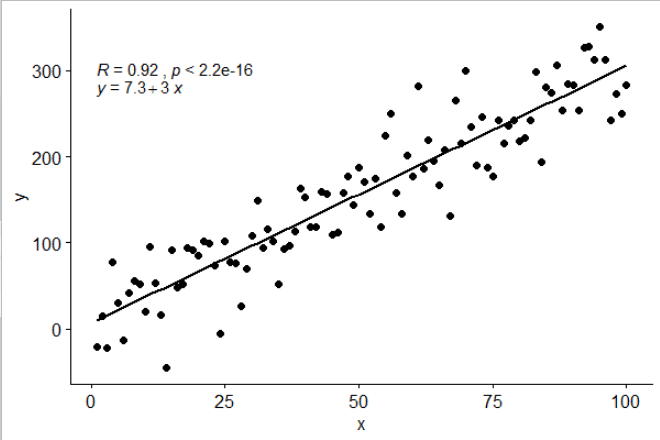
Используя ggpubr:
library(ggpubr)
# reproducible data
set.seed(1)
df <- data.frame(x = c(1:100))
df$y <- 2 + 3 * df$x + rnorm(100, sd = 40)
# By default showing Pearson R
ggscatter(df, x = "x", y = "y", add = "reg.line") +
stat_cor(label.y = 300) +
stat_regline_equation(label.y = 280)
# Use R2 instead of R
ggscatter(df, x = "x", y = "y", add = "reg.line") +
stat_cor(label.y = 300,
aes(label = paste(..rr.label.., ..p.label.., sep = "~`,`~"))) +
stat_regline_equation(label.y = 280)
## compare R2 with accepted answer
# m <- lm(y ~ x, df)
# round(summary(m)$r.squared, 2)
# [1] 0.85
Действительно люблю решение @Ramnath. Чтобы разрешить использование для настройки формулы регрессии (вместо того, чтобы фиксировать как y и x как литеральные имена переменных), а также добавить p-значение в распечатку (как прокомментировал @Jerry T), вот мод:
lm_eqn <- function(df, y, x){
formula = as.formula(sprintf('%s ~ %s', y, x))
m <- lm(formula, data=df);
# formating the values into a summary string to print out
# ~ give some space, but equal size and comma need to be quoted
eq <- substitute(italic(target) == a + b %.% italic(input)*","~~italic(r)^2~"="~r2*","~~p~"="~italic(pvalue),
list(target = y,
input = x,
a = format(as.vector(coef(m)[1]), digits = 2),
b = format(as.vector(coef(m)[2]), digits = 2),
r2 = format(summary(m)$r.squared, digits = 3),
# getting the pvalue is painful
pvalue = format(summary(m)$coefficients[2,'Pr(>|t|)'], digits=1)
)
)
as.character(as.expression(eq));
}
geom_point() +
ggrepel::geom_text_repel(label=rownames(mtcars)) +
geom_text(x=3,y=300,label=lm_eqn(mtcars, 'hp','wt'),color='red',parse=T) +
geom_smooth(method='lm')
 К сожалению, это не работает с facet_wrap или facet_grid.
К сожалению, это не работает с facet_wrap или facet_grid.
Другой вариант - создать пользовательскую функцию, генерирующую уравнение, используя
dplyr и
broom библиотеки:
get_formula <- function(model) {
broom::tidy(model)[, 1:2] %>%
mutate(sign = ifelse(sign(estimate) == 1, ' + ', ' - ')) %>% #coeff signs
mutate_if(is.numeric, ~ abs(round(., 2))) %>% #for improving formatting
mutate(a = ifelse(term == '(Intercept)', paste0('y ~ ', estimate), paste0(sign, estimate, ' * ', term))) %>%
summarise(formula = paste(a, collapse = '')) %>%
as.character
}
lm(y ~ x, data = df) -> model
get_formula(model)
#"y ~ 6.22 + 3.16 * x"
scales::percent(summary(model)$r.squared, accuracy = 0.01) -> r_squared
Теперь нам нужно добавить текст к сюжету:
p +
geom_text(x = 20, y = 300,
label = get_formula(model),
color = 'red') +
geom_text(x = 20, y = 285,
label = r_squared,
color = 'blue')
https:https://stackru.com/images/4f0ad9fe228da1ffd24aeade79788e934c85a768.png
Вдохновленный стилем уравнений, представленным в этом ответе, более общий подход (более одного предиктора + вывод латекса в качестве опции) может быть:
print_equation= function(model, latex= FALSE, ...){
dots <- list(...)
cc= model$coefficients
var_sign= as.character(sign(cc[-1]))%>%gsub("1","",.)%>%gsub("-"," - ",.)
var_sign[var_sign==""]= ' + '
f_args_abs= f_args= dots
f_args$x= cc
f_args_abs$x= abs(cc)
cc_= do.call(format, args= f_args)
cc_abs= do.call(format, args= f_args_abs)
pred_vars=
cc_abs%>%
paste(., x_vars, sep= star)%>%
paste(var_sign,.)%>%paste(., collapse= "")
if(latex){
star= " \\cdot "
y_var= strsplit(as.character(model$call$formula), "~")[[2]]%>%
paste0("\\hat{",.,"_{i}}")
x_vars= names(cc_)[-1]%>%paste0(.,"_{i}")
}else{
star= " * "
y_var= strsplit(as.character(model$call$formula), "~")[[2]]
x_vars= names(cc_)[-1]
}
equ= paste(y_var,"=",cc_[1],pred_vars)
if(latex){
equ= paste0(equ," + \\hat{\\varepsilon_{i}} \\quad where \\quad \\varepsilon \\sim \\mathcal{N}(0,",
summary(MetamodelKdifEryth)$sigma,")")%>%paste0("$",.,"$")
}
cat(equ)
}
model аргумент ожидает lm объект, latex аргумент является логическим, чтобы попросить простой символ или уравнение в латексном формате, и ... аргумент передать свои значения format функция.
Я также добавил опцию для вывода его в виде латекса, чтобы вы могли использовать эту функцию в rmarkdown следующим образом:
```{r echo=FALSE, results='asis'}
print_equation(model = lm_mod, latex = TRUE)
```
Теперь, используя его:
df <- data.frame(x = c(1:100))
df$y <- 2 + 3 * df$x + rnorm(100, sd = 40)
df$z <- 8 + 3 * df$x + rnorm(100, sd = 40)
lm_mod= lm(y~x+z, data = df)
print_equation(model = lm_mod, latex = FALSE)
Этот код дает: y = 11.3382963933174 + 2.5893419 * x + 0.1002227 * z
И если мы попросим уравнение латекса, округляем параметры до 3 цифр:
print_equation(model = lm_mod, latex = TRUE, digits= 3)
Это дает: 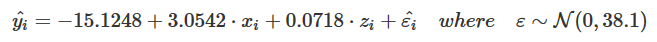
Аналогично ответам @zx8754 и @kdauria, за исключением использованияggplot2и . я предпочитаю использоватьggpubrпотому что он не требует пользовательских функций, таких как главный ответ на этот вопрос.
library(ggplot2)
library(ggpubr)
df <- data.frame(x = c(1:100))
df$y <- 2 + 3 * df$x + rnorm(100, sd = 40)
ggplot(data = df, aes(x = x, y = y)) +
stat_smooth(method = "lm", se=FALSE, color="black", formula = y ~ x) +
geom_point() +
stat_cor(aes(label = paste(..rr.label..)), # adds R^2 value
r.accuracy = 0.01,
label.x = 0, label.y = 375, size = 4) +
stat_regline_equation(aes(label = ..eq.label..), # adds equation to linear regression
label.x = 0, label.y = 400, size = 4)
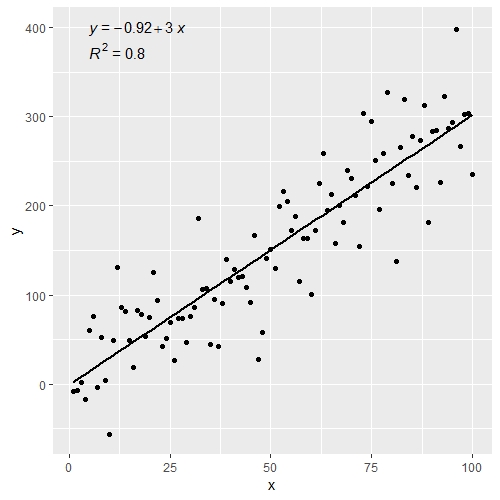
Можно также добавить p-значение к рисунку выше.
ggplot(data = df, aes(x = x, y = y)) +
stat_smooth(method = "lm", se=FALSE, color="black", formula = y ~ x) +
geom_point() +
stat_cor(aes(label = paste(..rr.label.., ..p.label.., sep = "~`,`~")), # adds R^2 and p-value
r.accuracy = 0.01,
p.accuracy = 0.001,
label.x = 0, label.y = 375, size = 4) +
stat_regline_equation(aes(label = ..eq.label..), # adds equation to linear regression
label.x = 0, label.y = 400, size = 4)
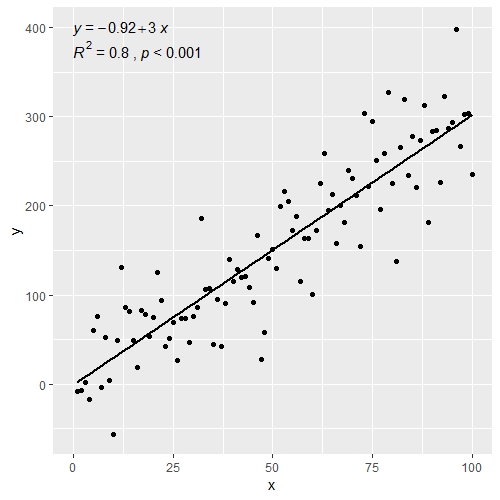
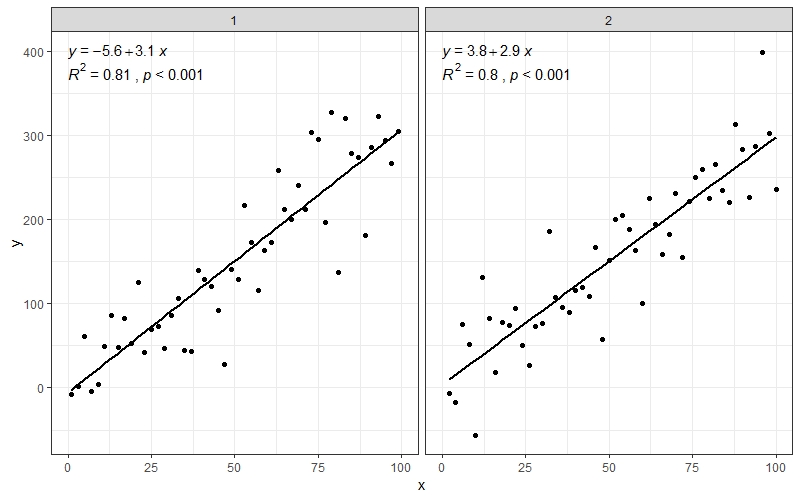
Также хорошо работает сfacet_wrap()когда у вас несколько групп
df$group <- rep(1:2,50)
ggplot(data = df, aes(x = x, y = y)) +
stat_smooth(method = "lm", se=FALSE, color="black", formula = y ~ x) +
geom_point() +
stat_cor(aes(label = paste(..rr.label.., ..p.label.., sep = "~`,`~")),
r.accuracy = 0.01,
p.accuracy = 0.001,
label.x = 0, label.y = 375, size = 4) +
stat_regline_equation(aes(label = ..eq.label..),
label.x = 0, label.y = 400, size = 4) +
theme_bw() +
facet_wrap(~group)
Я сомневаюсь, как поставить в уравнение значительную статистику t.test для бхеты, используя ggpmisc::stat_poly_eq()?
пример: expression(hat(Y)== 0000*"**"+0000*"x"*"*"-0000*"x"^2*"**"~~~~"R"^2*":"~~0.000)