Попытка сегментировать символы и сохранить их для того, чтобы файлы изображений. Но контуры рисуются в другом порядке?
Это входное изображение.
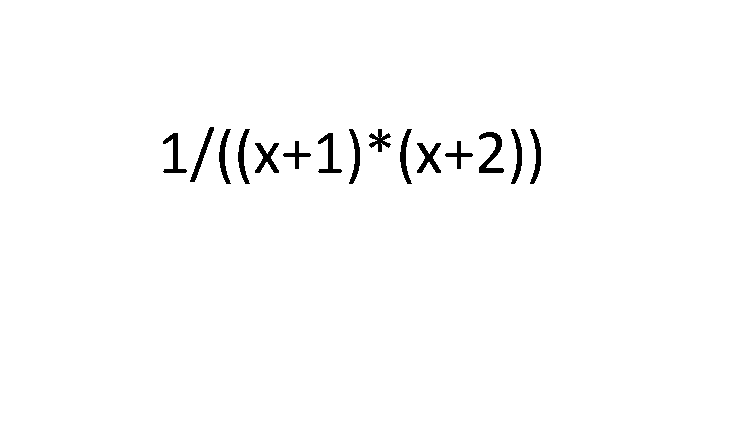
Использование python opencv. Я сделал некоторую предварительную обработку и нашел контуры, используя
contours,hierarchy = cv2.findContours(thresh,cv2.RETR_LIST,cv2.CHAIN_APPROX_SIMPLE)
Затем я сделал следующее, чтобы сохранить каждого персонажа
img1 = cv2.imread("test26.png")
nu = 1
fin = "final"
for cnt in contours:
x,y,w,h = cv2.boundingRect(cnt)
img2 = img1[y:y+h, x:x+w]
img3 = Image.fromarray(img2)
filename = fin + str(nu) + ".png"
nu = nu + 1
img3.save(filename)
Но символы сохраняются в виде дерева в порядке. Я не понимаю порядок.
Мое намерение состоит в том, чтобы получить символ за символом и записать его по порядку и сохранить как текст.
3 ответа
Вы можете попытаться найти местоположение буквы, используя центр контуров.
M = cv2.moments(contours)
cX = int(M["m10"] / M["m00"])
cY = int(M["m01"] / M["m00"])
Затем вы можете найти порядок символов с помощью cX и cY (если только одна строка, вы используете только cX)
Этот код сортирует ограничивающие рамки и достигает того, что, вероятно, было задумано, не так ли?
import cv2
strFormula="1!((x+1)*(x+2))" # '!' means a character is not allowed in file name
img = cv2.imread("test26.png")
imgGray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
ret, imgThresh = cv2.threshold(imgGray, 127, 255, 0)
(major_ver, minor_ver, subminor_ver) = (cv2.__version__).split('.')
if int(major_ver) < 3 :
contours , hierarchy = cv2.findContours(imgThresh, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
else :
image, contours , _ = cv2.findContours(imgThresh, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
#:if
lstBoundingBoxes = []
for cnt in contours: lstBoundingBoxes.append(cv2.boundingRect(cnt))
lstBoundingBoxes.sort()
charNo=0
for item in lstBoundingBoxes[1:]: # skip first element ('bounding box' == entire image)
charNo += 1
fName = "charAtPosNo-" + str(charNo).zfill(2) + "_is_[ " + strFormula[charNo-1] + " ]"+ ".png";
x,y,w,h = item
cv2.imwrite(fName, img[y:y+h, x:x+w])
Качество вашего изображения очень хорошее. Так что, если вы заботитесь только о решении проблемы (а не о том, как сделать это самостоятельно;-) - тогда вы можете использовать, например, OCR.space free ocr api ( код Python здесь). Я проверил это с вашим изображением, и оно работает хорошо - никакой предварительной обработки не требуется. Облачное зрение Google ocr, вероятно, также работает (не проверено).
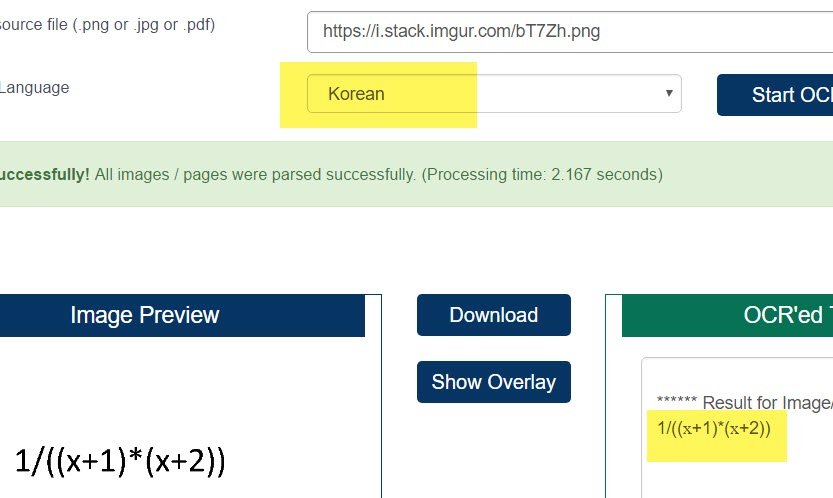
Обратите внимание, что для этого важно установить язык OCR на "Корейский". Этот язык OCR лучше подходит для обнаружения чисел и других математических символов. Если вы используете английский, API утверждает, что на изображении нет текста.