Снижается ли производительность при выполнении циклов, число операций которых не кратно ширине процессора?
Мне интересно, как циклы различных размеров работают на последних процессорах x86, как функция числа мопов.
Вот цитата из Питера Кордеса, который поднял проблему подсчетов не кратных 4 в другом вопросе:
Я также обнаружил, что пропускная способность uop из буфера цикла не является постоянной 4 за цикл, если цикл не кратен 4 мопам. (то есть это abc, abc, ...; не abca, bcab, ...). Документ микроархиста Агнера Фога, к сожалению, не ясно об этом ограничении буфера петли.
Вопрос заключается в том, должно ли число циклов быть кратным N мопам для выполнения с максимальной пропускной способностью мопов, где N - ширина процессора. (т.е. 4 для последних процессоров Intel). Есть много усложняющих факторов, когда речь идет о "ширине" и числе мопов, но я в основном хочу их игнорировать. В частности, не предполагайте микро или макро-слияния.
Питер приводит следующий пример цикла с 7 мопами в теле:
Цикл с 7 uop выдаст группы по 4|3|4|3|... Я не тестировал большие циклы (которые не помещаются в буфер цикла), чтобы посмотреть, возможно ли выполнить первую инструкцию из следующей итерацию выдавать в той же группе, что и взятая ветка к ней, но я предполагаю, что нет.
В более общем смысле утверждение состоит в том, что каждая итерация цикла с x мопс в его теле займет минимум ceil(x / 4) итерации, а не просто x / 4,
Это правда для некоторых или всех последних x86-совместимых процессоров?
2 ответа
Я провел некоторое исследование с Linux perf чтобы помочь ответить на этот вопрос на моей коробке Skylake i7-6700HQ, а результаты Haswell любезно предоставлены другим пользователем. Приведенный ниже анализ относится к Skylake, но за ним следует сравнение с Haswell.
Другие архитектуры могут отличаться от0 - и я приветствую дополнительные результаты - источник доступен).
Этот вопрос в основном касается внешнего интерфейса, поскольку в последних архитектурах именно внешний интерфейс накладывает жесткое ограничение на четыре мопа слитых доменов за цикл.
Краткое изложение правил для циклического исполнения
Во-первых, я обобщу результаты в терминах нескольких "правил производительности", которые следует учитывать при работе с небольшими циклами. Существует также множество других правил производительности - они дополняют их (т. Е. Вы, вероятно, не нарушаете другое правило, чтобы просто удовлетворить его). Эти правила наиболее применимы непосредственно к Haswell и более поздним архитектурам - см. Другой ответ для обзора различий по более ранним архитектурам.
Сначала посчитайте количество слитых макросов в вашем цикле. Вы можете использовать таблицы инструкций Агнера, чтобы искать их непосредственно для каждой инструкции, за исключением того, что операция ALU и сразу после перехода обычно объединяются в одну операцию. Затем на основании этого подсчета:
- Если счетчик кратен 4, то все в порядке: эти циклы выполняются оптимально.
- Если число четное и меньше 32, все в порядке, за исключением случаев, когда это число равно 10, и в этом случае вам следует развернуть другое четное число, если это возможно.
- Для нечетных чисел вы должны попытаться развернуть на четное число меньше 32 или кратное 4, если можете.
- Для циклов больше 32 мопов, но меньше 64, вы можете развернуть, если оно не кратно 4: с более чем 64 мопами вы получите эффективную производительность при любом значении на Скляке и почти на всех значениях на Haswell (с некоторыми отклонениями, возможно, связанные с выравниванием). Неэффективность этих циклов все еще относительно мала: значения, которых следует избегать, являются
4N + 1рассчитывает, а затем4N + 2на счет.
Резюме выводов
Для кода, обслуживаемого из кэша UOP, не существует явных эффектов, кратных 4. Циклы любого числа мопов могут выполняться с пропускной способностью 4 мопов слитых доменов за цикл.
Для кода, обработанного унаследованными декодерами, верно обратное: время выполнения цикла ограничено целым числом циклов, и, следовательно, циклы, не кратные 4 моп, не могут достичь 4 моп / цикл, поскольку они тратят некоторые слоты выдачи / выполнения,
Для кода, выданного из детектора петлевого потока (LSD), ситуация представляет собой сочетание двух и более подробно поясняется ниже. В целом, циклы менее 32 мопов и с четным числом мопов выполняются оптимально, в то время как петли нечетного размера - нет, а для больших циклов требуется оптимальное число миль-4.
Что говорит Intel
У Intel есть примечание об этом в их руководстве по оптимизации, подробности в другом ответе.
подробности
Как известно любому хорошо осведомленному в последнее время архитектуре x86-64, в любой момент часть извлечения и декодирования внешнего интерфейса может работать в нескольких различных режимах, в зависимости от размера кода и других факторов. Как оказалось, все эти разные режимы имеют разное поведение по отношению к размеру цикла. Я расскажу о них отдельно.
Legacy Decoder
Устаревший декодер1 - это полныйдекодер машинного кода в uops, который используется2, когда код не помещается в механизмы кэширования uop (LSD или DSB). Основная причина, по которой это может произойти, заключается в том, что рабочий набор кода больше, чем кэш-память UOP (в идеальном случае приблизительно ~1500 UOP, на практике меньше). Однако для этого теста мы воспользуемся тем фактом, что устаревший декодер также будет использоваться, если выровненный 32-байтовый блок содержит более 18 инструкций 3.
Чтобы проверить поведение устаревшего декодера, мы используем цикл, который выглядит следующим образом:
short_nop:
mov rax, 100_000_000
ALIGN 32
.top:
dec rax
nop
...
jnz .top
ret
В основном, тривиальный цикл, который отсчитывает доrax это ноль. Все инструкции представляют собой один моп 4 и количество nopинструкции различны (в месте, указанном как ...) для проверки петель разных размеров (так что петля с 4 моп будет иметь 2 nops, плюс две инструкции управления петлей). Здесь нет макро-синтеза, так как мы всегда разделяем decа такжеjnzпо крайней мере с однимnop, а также без микросинтеза. Наконец, нет доступа к памяти в (вне подразумеваемого доступа к icache).
Обратите внимание, что этот цикл очень плотный - около 1 байта на инструкцию (так как nop инструкции по 1 байту каждая) - поэтому мы будем запускать> 18 инструкций в состоянии блока 32B, как только нажмем 19 инструкций в цикле. На основании изучения perf счетчики производительностиlsd.uopsа такжеidq.mite_uops это именно то, что мы видим: по существу, 100% инструкций поступают из LSD5 вплоть до цикла 18 моп, включая 100 моп и более, а 100% - из устаревшего декодера.
В любом случае, вот циклы / итерации для всех размеров цикла от 3 до 99 моп6:

Синие точки - это петли, которые вписываются в ЛСД и показывают довольно сложное поведение. Мы рассмотрим это позже.
Красные точки (начиная с 19 моп / итерация) обрабатываются устаревшим декодером и показывают очень предсказуемый шаблон:
- Все петли с
Nупс точноceiling(N/4)итерации
Так, по крайней мере, для унаследованного декодера, наблюдение Питера в точности относится к Skylake: циклы с кратным 4 мопам могут выполняться при IPC 4, но любое другое количество мопов будет тратить 1, 2 или 3 слота выполнения (для циклов с 4N+3,4N+2,4N+1инструкции соответственно).
Мне не понятно, почему это происходит. Хотя это может показаться очевидным, если учесть, что декодирование происходит в смежных блоках по 16В, и поэтому при скорости декодирования 4 цикла в моп / цикл не кратное 4 всегда будет иметь некоторые конечные (потерянные) слоты в циклеjnz инструкция встречается. Однако фактический модуль извлечения и декодирования состоит из фаз предварительного кодирования и декодирования с промежуточной очередью. Фаза предварительного кода фактически имеет пропускную способность6 команд, но декодирует только до конца 16-байтовой границы в каждом цикле. Похоже, это подразумевает, что пузырь, возникающий в конце цикла, может быть поглощен очередью предварительного кодирования -> декодирования, так как предварительный кодер имеет среднюю пропускную способность выше 4.
Поэтому я не могу полностью объяснить это, основываясь на моем понимании того, как работает предкодер. Может быть, что существует некоторое дополнительное ограничение в декодировании или предварительном декодировании, которое предотвращает подсчет неинтегральных циклов. Например, возможно, унаследованные декодеры не могут декодировать инструкции с обеих сторон перехода, даже если инструкции после перехода доступны в предварительно кодированной очереди. Возможно, это связано с необходимостью справиться с макро-синтезом.
Вышеприведенный тест показывает поведение, при котором вершина цикла выравнивается по 32-байтовой границе. Ниже приведен тот же график, но с добавленной серией, которая показывает эффект, когда вершина цикла перемещается на 2 байта вверх (т.е. теперь смещена по границе 32N + 30):

Большинство циклов теперь имеют штраф в 1 или 2 цикла. Случай с 1 штрафом имеет смысл, когда вы рассматриваете декодирование границ 16B и декодирование с 4 командами за цикл, и случаи с 2 штрафами за цикл происходят для циклов, где по какой-то причине DSB используется для 1 инструкции в цикле (вероятно,decинструкция, которая появляется в его собственном 32-байтовом фрагменте), и некоторые штрафы DSB<->MITE налагаются.
В некоторых случаях рассогласование не повредит, когда оно заканчивается, лучше выравнивая конец цикла. Я проверил смещение, и оно сохраняется таким же образом до 200 петель UOP. Если вы возьмете описание прекодеров за чистую монету, может показаться, что, как и выше, они должны быть в состоянии скрыть пузырь извлечения для смещения, но этого не происходит (возможно, очередь недостаточно велика).
DSB (Uop Cache)
Кэш UOP (Intel любит называть его DSB) способен кэшировать большинство циклов умеренного количества инструкций. В типичной программе вы надеетесь, что большинство ваших инструкций будут отправлены из этого кэша 7.
Мы можем повторить тест выше, но теперь обслуживаем мопы из кеша мопов. Это простой вопрос увеличения размера наших nops до 2 байтов, поэтому мы больше не достигаем ограничения в 18 инструкций. Мы используем 2-байтовый nopxchg ax, axв нашем цикле:
long_nop_test:
mov rax, iters
ALIGN 32
.top:
dec eax
xchg ax, ax ; this is a 2-byte nop
...
xchg ax, ax
jnz .top
ret
Здесь результаты очень просты. Для всех протестированных размеров контуров, доставленных из DSB, требуемое количество циклов былоN/4- т.е. циклы выполняются с максимальной теоретической пропускной способностью, даже если они не были кратны 4 мопам. Таким образом, в общем случае на Skylake петли умеренного размера, обслуживаемые из DSB, не должны беспокоиться о том, чтобы счетчик мопов соответствовал определенному кратному.
Вот график до 1000 моп циклов. Если вы щуритесь, вы можете увидеть неоптимальное поведение до 64 мопов (когда цикл находится в ЛСД). После этого, это прямой выстрел, 4 IPC на всем протяжении до 1000 мопов (с проблеском около 900, который, вероятно, был вызван нагрузкой на мой ящик):

Далее мы рассмотрим производительность для циклов, которые достаточно малы, чтобы поместиться в кэш UOP.
LSD (паровой детектор петли)
Важное примечание: Intel, по-видимому, отключила LSD на микросхемах Skylake (SKL150 erratum) и Kaby Lake (KBL095, KBW095 erratum) с помощью обновления микрокода и из коробки из- за ошибки, связанной с взаимодействием между гиперпоточностью и ЛСД. Для этих чипов на приведенном ниже графике, вероятно, не будет интересного региона до 64 моп; скорее это будет выглядеть так же, как регион после 64 мопов.
Детектор петлевого потока может кэшировать небольшие циклы до 64 мопов (на Skylake). В недавней документации Intel он позиционируется скорее как механизм энергосбережения, чем как функция производительности, хотя, безусловно, нет никаких недостатков в производительности, упомянутых при использовании LSD.
Запустив это для размеров цикла, которые должны вписываться в LSD, мы получаем следующие циклы / итерацию:

Красная линия - это процент мопов, доставленных с ЛСД. Он выравнивается на 100% для всех размеров петель от 5 до 56 моп.
Для циклов 3 и 4 мопов мы имеем необычное поведение, когда 16% и 25% мопов, соответственно, доставляются из устаревшего декодера. А? К счастью, это не влияет на пропускную способность цикла, так как в обоих случаях достигается максимальная пропускная способность в 1 цикл / цикл - несмотря на то, что можно ожидать некоторых штрафов за переход MITE<->LSD.
Между размерами петель от 57 до 62 мопов число мопов, доставленных из ЛСД, демонстрирует странное поведение - примерно 70% мопов доставляется из ЛСД, а остальные из ЦСБ. Скайлэйк номинально имеет 64-мегапиксельную LSD, так что это какой-то переход прямо перед превышением размера LSD - возможно, есть какое-то внутреннее выравнивание в IDQ (на котором реализован LSD), которое вызывает только частичные попадания в ЛСД на этом этапе. Эта фаза короткая и, с точки зрения производительности, в основном представляет собой линейную комбинацию производительности full-in-LSD, которая предшествует ей, и производительности full-in-DSB, которая следует за ней.
Давайте посмотрим на основную часть результатов от 5 до 56 моп. Мы видим три разных региона:
Циклы от 3 до 10 мопов: здесь поведение сложное. Это единственная область, где мы видим количество циклов, которое не может быть объяснено статическим поведением за одну итерацию цикла 8. Диапазон достаточно короткий, поэтому трудно сказать, есть ли образец. Циклы по 4, 6 и 8 мопов выполняются оптимально, вN/4циклы (это тот же шаблон, что и в следующем регионе).
Цикл из 10 мопов, с другой стороны, выполняется за 2,66 циклов за итерацию, что делает его единственным четным размером цикла, который не выполняется оптимально, пока вы не достигнете размеров цикла 34 моп или выше (кроме выброса в 26), Это соответствует чему-то вроде повторного выполнения UOP / цикла4, 4, 4, 3, Для цикла из 5 мопов вы получаете 1,33 цикла на итерацию, очень близко, но не то же самое, что идеал 1,25. Это соответствует скорости выполнения4, 4, 4, 4, 3,
Эти результаты трудно объяснить. Результаты повторяются от прогона к прогону и устойчивы к изменениям, таким как замена nop для инструкции, которая фактически выполняет что-то вродеmov ecx, 123, Это может быть связано с лимитом в 1 взятую ветвь каждые 2 цикла, который применяется ко всем циклам, кроме тех, которые "очень малы". Может случиться так, что мопы иногда выстраиваются так, что это ограничение срабатывает, приводя к дополнительному циклу. Как только вы достигнете 12 моп или выше, это никогда не произойдет, поскольку вы всегда берете как минимум три цикла на итерацию.
Петли от 11 до 32 мопов: мы видим ступенчатую схему, но с периодом два. В основном все циклы с четным числом мопов работают оптимально, т.е.N/4циклы. Циклы с нечетным числом мопов тратят один "выпускной слот" и выполняют то же количество циклов, что и цикл с еще одним мопом (т. Е. Цикл из 17 моп занимает те же 4,5 цикла, что и цикл из 18 моп). Так что здесь у нас поведение лучше, чемceiling(N/4)по многим показателям числа операций, и у нас есть первое доказательство того, что Skylake по крайней мере может выполнять циклы за нецелое число циклов.
Единственными выбросами являются N=25 и N=26, которые занимают примерно на 1,5% больше времени, чем ожидалось. Это небольшой, но воспроизводимый и надежный способ перемещения функции в файле. Это слишком мало, чтобы объяснять его эффектом итерации, если только у него нет гигантского периода, так что, возможно, это что-то другое.
Общее поведение здесь точно соответствует (за исключением аномалии 25/26) с аппаратным обеспечением,развертывающим цикл в 2 раза.
Циклы от 33 до ~64 моп. Мы снова видим схему ступеньки, но с периодом 4 и худшей средней производительностью, чем в случае до 32 моп. Поведение точноceiling(N/4)- то же самое, что и унаследованный корпус декодера. Таким образом, для циклов от 32 до 64 моп, LSD не дает очевидного преимущества по сравнению с традиционными декодерамис точки зрения пропускной способности внешнего интерфейса для этого конкретного ограничения. Конечно, есть много других способов улучшить LSD - он избегает многих потенциальных узких мест декодирования, которые возникают для более сложных или более длинных команд, и экономит электроэнергию и т. Д.
Все это довольно удивительно, потому что это означает, что циклы, доставляемые из кэша UOP, обычно работаютлучше во внешнем интерфейсе, чем циклы, доставляемые из LSD, несмотря на то, что LSD обычно позиционируется как строго лучший источник UOP, чем DSB (например, как часть совета, старайтесь держать петли достаточно маленькими, чтобы поместиться в ЛСД).
Вот еще один способ взглянуть на те же данные - с точки зрения потери эффективности для данного количества мопов по сравнению с теоретической максимальной пропускной способностью 4 моп за цикл. 10% эффективности означает, что у вас есть только 90% пропускной способности, которую вы рассчитываете из простогоN/4формула.
Общее поведение здесь согласуется с тем, что оборудование не выполняет развертывание, что имеет смысл, поскольку цикл из более чем 32 моп не может быть развернут вообще в буфере из 64 моп.

Три области, обсужденные выше, окрашены по-разному, и, по крайней мере, видны конкурирующие эффекты:
При прочих равных условиях, чем больше задействованных мопов, тем ниже эффективность удара. Хит является фиксированной стоимостью только один раз за итерацию, поэтому большие циклы платят меньшуюотносительную стоимость.
При переходе в область 33+ мопов наблюдается значительный скачок неэффективности: увеличивается как размер потери пропускной способности, так и число затронутых мопов увеличивается вдвое.
Первый регион несколько хаотичен, и 7 моп - это наихудшее общее количество мопов.
центровка
Приведенный выше анализ DSB и LSD относится к элементам цикла, выровненным по 32-байтовой границе, но случай с невыровненными значениями, похоже, не страдает ни в одном случае: нет существенных отличий от случая с выравниванием (кроме, возможно, небольшого отклонения) менее 10 мопов, которые я больше не расследовал).
Вот невыровненные результаты для32N-2а также32N+2(т. е. верхние 2 байта цикла до и после границы 32B):

ИдеалN/4линия также показана для справки.
Haswell
Далее следуем взглянуть на предыдущую микроархитектуру: Haswell. Цифры здесь любезно предоставлены пользователем Iwillnotexist Idonotexist.
LSD + Legacy Decode Pipeline
Во-первых, результаты теста "плотного кода", который проверяет LSD (для малых количеств uop) и устаревший конвейер (для больших количеств uop, поскольку цикл "вылетает" из DSB из-за плотности команд.
Сразу же мы видим разницу с точки зрения того, когда каждая архитектура доставляет мопы из LSD для плотного цикла. Ниже мы сравниваем Skylake и Haswell для коротких цикловплотного кода (1 байт на инструкцию).

Как описано выше, цикл Skylake перестает доставляться из LSD ровно с 19 моп, как и ожидалось из области ограничения кода 18-моп на 32 байта. С другой стороны, Haswell, похоже, прекратил надежную доставку из ЛСД для петель 16 и 17 мопов. У меня нет никаких объяснений этому. Существует также различие в случае с 3 мопами: странным образом оба процессора доставляют тольконекоторые из своих мопов из ЛСД в случаях 3 и 4 моп, но точное количество одинаково для 4 моп и отличается от 3.
Мы в основном заботимся о реальных показателях, правда? Итак, давайте посмотрим на циклы / итерации для случаяплотного кода с 32-байтовым выравниванием:

Это те же данные, что и выше, для Скайлэйка (смещенный ряд был удален), вместе с Хасвеллом. Сразу же вы замечаете, что картина для Haswellпохожа, но не одинакова. Как и выше, здесь есть два региона:
Legacy Decode
Циклы, превышающие ~16-18 моп (неопределенность описана выше), доставляются от устаревших декодеров. Шаблон для Haswell несколько отличается от Skylake.
Для диапазона от 19 до 30 мопов они идентичны, но после этого Хасвелл нарушает схему. Скайлэйк взял ceil(N/4)циклы для циклов, доставленных от устаревших декодеров. Haswell, с другой стороны, кажется, что-то вродеceil((N+1)/4) + ceil((N+2)/12) - ceil((N+1)/12), Хорошо, это грязно (более короткая форма, кто-нибудь?) - но в основном это означает, что в то время как Skylake выполняет циклы с 4*N циклами оптимально (т. Е. При 4 моп / цикл), такие циклы (локально) обычно являются наименьшим оптимальным числом (по крайней мере, локально) - для выполнения таких циклов требуется больше цикла, чем в Skylake. Таким образом, на самом деле вам лучше всего использовать петли 4N-1 мопов на Haswell, за исключением того, что 25% таких петель, которыетакже имеют форму 16-1N (31, 47, 63 и т. Д.), Выполняют один дополнительный цикл. Это начинает звучать как расчет високосного года - но модель, вероятно, лучше понять визуально выше.
Я не думаю, что этот паттерн свойственен отправке сообщений в Хасвелл, поэтому мы не должны вдаваться в подробности. Кажется, это объясняется
0000000000455a80 <short_nop_aligned35.top>:
16B cycle
1 1 455a80: ff c8 dec eax
1 1 455a82: 90 nop
1 1 455a83: 90 nop
1 1 455a84: 90 nop
1 2 455a85: 90 nop
1 2 455a86: 90 nop
1 2 455a87: 90 nop
1 2 455a88: 90 nop
1 3 455a89: 90 nop
1 3 455a8a: 90 nop
1 3 455a8b: 90 nop
1 3 455a8c: 90 nop
1 4 455a8d: 90 nop
1 4 455a8e: 90 nop
1 4 455a8f: 90 nop
2 5 455a90: 90 nop
2 5 455a91: 90 nop
2 5 455a92: 90 nop
2 5 455a93: 90 nop
2 6 455a94: 90 nop
2 6 455a95: 90 nop
2 6 455a96: 90 nop
2 6 455a97: 90 nop
2 7 455a98: 90 nop
2 7 455a99: 90 nop
2 7 455a9a: 90 nop
2 7 455a9b: 90 nop
2 8 455a9c: 90 nop
2 8 455a9d: 90 nop
2 8 455a9e: 90 nop
2 8 455a9f: 90 nop
3 9 455aa0: 90 nop
3 9 455aa1: 90 nop
3 9 455aa2: 90 nop
3 9 455aa3: 75 db jne 455a80 <short_nop_aligned35.top>
Здесь я отметил блок декодирования 16B (1-3), в котором появляется каждая инструкция, и цикл, в котором она будет декодирована. Правило в основном заключается в том, что до следующих 4 инструкций декодируются до тех пор, пока они попадают в текущий блок 16B. В противном случае они должны ждать до следующего цикла. Для N=35 мы видим, что в цикле 4 потеряно 1 слот декодирования (в блоке 16B осталось только 3 инструкции), но в противном случае цикл выстраивается очень хорошо с границами 16B и даже с последним циклом (9) может декодировать 4 инструкции.
Вот усеченный взгляд на N=36, который идентичен за исключением конца цикла:
0000000000455b20 <short_nop_aligned36.top>:
16B cycle
1 1 455a80: ff c8 dec eax
1 1 455b20: ff c8 dec eax
1 1 455b22: 90 nop
... [29 lines omitted] ...
2 8 455b3f: 90 nop
3 9 455b40: 90 nop
3 9 455b41: 90 nop
3 9 455b42: 90 nop
3 9 455b43: 90 nop
3 10 455b44: 75 da jne 455b20 <short_nop_aligned36.top>
Теперь есть 3 инструкции для декодирования в 3-м и последнем 16B-блоках, поэтому необходим один дополнительный цикл. В основном, 35 команд для этого конкретного шаблона команд лучше соответствуют границам 16B битов и сохраняют один цикл при декодировании. Это не значит, что N=35 лучше, чем N = 36 в целом! Разные инструкции будут иметь разное количество байтов и будут выстраиваться по-разному. Подобная проблема выравнивания объясняет также дополнительный цикл, который требуется каждые 16 байтов:
16B cycle
...
2 7 45581b: 90 nop
2 8 45581c: 90 nop
2 8 45581d: 90 nop
2 8 45581e: 90 nop
3 8 45581f: 75 df jne 455800 <short_nop_aligned31.top>
Здесь финалjneпроскользнул в следующий блок 16B (если инструкция охватывает границу 16B, она фактически находится в последнем фрагменте), вызывая дополнительную потерю цикла. Это происходит только каждые 16 байтов.
Таким образом, результаты устаревшего декодера Haswell прекрасно объясняются устаревшим декодером, который ведет себя так, как описано, например, в документе по микроархитектуре Agner Fog. Фактически, это также объясняет результаты Skylake, если вы предполагаете, что Skylake может декодировать 5 команд за цикл (обеспечивая до 5 моп) 9. Предполагая, что это возможно, пропускная способность асимптотического унаследованного декодированияв этом коде для Skylake по-прежнему равна 4 мопам, так как блок из 16 нопов декодирует 5-5-5-1, а не 4-4-4-4 в Haswell, поэтому вы получаете только преимущества по краям: например, в вышеприведенном случае N = 36 Skylake может декодировать все оставшиеся 5 инструкций против 4-1 для Haswell, сохраняя цикл.
В результате кажется, что обычное поведение декодера можно понять довольно просто, и основной совет по оптимизации заключается в том, чтобы продолжать наращивать код так, чтобы он "умело" попадал в выровненные фрагменты 16B (возможно, это NP- тяжело как упаковка бина?).
DSB (и снова LSD)
Далее давайте посмотрим на сценарий, в котором код подается из LSD или DSB - с помощью теста "long nop", который позволяет избежать превышения лимита порции 18-моп на 32B и таким образом остается в DSB.
Haswell против Skylake:

Обратите внимание на поведение ЛСД - здесь Хэсвелл прекращает подачу ЛСД ровно с 57 моп, что полностью соответствует опубликованному размеру ЛСД 57 моп. Там нет странного "переходного периода", как мы видим на Skylake. Haswell также имеет странное поведение для 3 и 4 мопов, где только ~0% и ~40% мопов, соответственно, происходят от ЛСД.
Что касается производительности, Haswell обычно соответствует Skylake с несколькими отклонениями, например, около 65, 77 и 97 моп, где он округляется до следующего цикла, тогда как Skylake всегда способен выдержать 4 моп / цикл, даже когда это приводит к результатам в нецелом числе циклов. Небольшое отклонение от ожидаемого на 25 и 26 моп исчезло. Возможно, 6-мегапиксельная скорость доставки Skylake поможет ему избежать проблем с выравниванием моп-кэша, которые Haswell страдает со своей 4-мегапиксельной скоростью доставки.
Другие Архитектуры
Результаты для следующих дополнительных архитектур были любезно предоставлены пользователем Андреасом Абелем, но нам придется использовать другой ответ для дальнейшего анализа, поскольку мы находимся здесь на пределе количества символов.
Нужна помощь
Хотя результаты для многих платформ были любезно предоставлены сообществом, мне все еще интересны результаты на чипах старше Nehalem и новее, чем Coffee Lake (в частности, Cannon Lake, который является новым uarch). Код для генерации этих результатов является общедоступным. Кроме того, результаты выше доступны в.odsформат в GitHub, а также.
В частности, максимальная пропускная способность унаследованного декодера, очевидно, увеличилась с 4 до 5 моп в Skylake, а максимальная пропускная способность для кэш-памяти моп возросла с 4 до 6. Оба эти параметра могут повлиять на результаты, описанные здесь.
1 Intel на самом деле нравится называть устаревший декодер MITE (механизмом перевода микро-инструкций), возможно, потому, что это ненадежно - пометить любую часть вашей архитектуры устаревшей коннотацией.
2 Технически существует другой, даже более медленный, источник мопов - MS (механизм секвенирования микрокодов), который используется для реализации любой команды с более чем 4 мопами, но мы здесь это игнорируем, поскольку ни один из наших циклов не содержит микрокодированных инструкций.
3 Это работает, потому что любой выровненный 32-байтовый блок может использовать не более 3-х каналов в своем слоте UOP-кэша, и каждый слот может содержать до 6 UOP. Так что если вы используете больше, чем 3 * 6 = 18 моп в 32-битном блоке, код вообще не может быть сохранен в кеш моп. Вероятно, на практике это редко встречается, поскольку код должен быть очень плотным (менее 2 байтов на инструкцию), чтобы вызвать это.
4 nop инструкции декодируются до одного мопа, но не удаляются до выполнения (т. е. они не используют порт выполнения), но по-прежнему занимают место во внешнем интерфейсе и, таким образом, учитывают различные ограничения, которые нас интересуют.
5 LSD - это детектор петлевого потока, который кэширует небольшие циклы до 64 мопов (Skylake) непосредственно в IDQ. На более ранних архитектурах он может содержать 28 мопов (оба активных логических ядра) или 56 мопов (одно активное логическое ядро).
6 Мы не можем легко вписать петлю 2 моп в этот шаблон, так как это будет означать ноль nop инструкции, означающие dec а также jnz инструкции будут макро-плавкими, с соответствующим изменением в счетчике мопов. Просто поверьте мне на слово, что все циклы с 4 или менее мопами выполняются в лучшем случае за 1 цикл / итерацию.
7 Ради интереса я просто побежал perf stat против короткого запуска Firefox, где я открыл вкладку и щелкнул несколько вопросов о переполнении стека. За доставленные инструкции я получил 46% от DSB, 50% от устаревшего декодера и 4% для LSD. Это показывает, что по крайней мере для большого, ветвящегося кода, такого как браузер, DSB все еще не может захватить большую часть кода (к счастью, унаследованные декодеры не так уж плохи).
8 Под этим я подразумеваю, что все остальные циклы можно объяснить, просто взяв "эффективную" стоимость интегрального цикла в мопах (которая может быть больше, чем фактический размер мопов) и разделив на 4. Для этих очень коротких петель, это не работает - вы не можете получить 1,333 цикла за итерацию, разделив любое целое число на 4. Иначе говоря, во всех других регионах затраты имеют форму N/4 для некоторого целого числа N.
9 На самом деле мы знаем, что Skylake может доставлять 5 моп за цикл от устаревшего декодера, но мы не знаем, могут ли эти 5 моп поступать из 5 разных инструкций или только из 4 или менее. То есть мы ожидаем, что Skylake сможет декодировать по шаблону 2-1-1-1, но я не уверен, что он может декодировать в шаблоне 1-1-1-1-1, Приведенные выше результаты свидетельствуют о том, что он действительно может декодировать 1-1-1-1-1,
Это продолжение первоначального ответа, чтобы проанализировать поведение для пяти дополнительных архитектур на основе результатов теста, представленных Andreas Abel:
- Nehalem
- Песчаный Мост
- Ivy Bridge
- Бродуэлла
- Кофейное озеро
Мы кратко рассмотрим результаты на этих архитектурах в дополнение к Skylake и Haswell. Это только должен быть "быстрый" взгляд, так как все архитектуры, кроме Nehalem, следуют одному из существующих шаблонов, обсужденных выше.
Во-первых, короткий случай nop, в котором используется устаревший декодер (для циклов, которые не вписываются в LSD) и LSD. Вот циклы / итерации для этого сценария для всех 7 архитектур.
Рисунок 2.1: Плотная производительность всех архитектур:

Этот график действительно занят (щелкните для увеличения), и его немного сложно прочитать, поскольку результаты для многих архитектур лежат друг на друге, но я постарался убедиться, что выделенный читатель сможет отследить линию для любой архитектуры.
Во-первых, давайте обсудим большой выброс: Nehalem. Все остальные архитектуры имеют наклон, который примерно следует линии 4 мопа / цикла, но Nehalem имеет почти ровно 3 мопа за цикл, поэтому быстро отстает от всех других архитектур. За пределами начальной области ЛСД линия также является абсолютно гладкой, без появления "ступеньки" в других архитектурах.
Это полностью согласуется с тем, что Nehalem имеет предел выхода на пенсию в меру 3 моп / цикл. Это узкое место для мопов за пределами ЛСД: все они выполняют примерно по 3 мопа за цикл, узкое место при выходе на пенсию. Внешний интерфейс не является узким местом, поэтому точный счетчик мопов и порядок декодирования не имеют значения, поэтому ступенька отсутствует.
Кроме Nehalem, другие архитектуры, кроме Broadwell, довольно четко разделены на группы: Haswell-подобные или Skylake-подобные. То есть все Sandy Bridge, Ivy Bridge и Haswell ведут себя как Haswell, для циклов больше, чем около 15 мопов (поведение Haswell обсуждается в другом ответе). Несмотря на то, что они представляют собой разные микроархитектуры, они ведут себя в основном одинаково, поскольку их традиционные возможности декодирования одинаковы. Ниже примерно 15 мопов мы видим, что Haswell несколько быстрее для любого количества мертвеев, не кратного 4. Возможно, он получает дополнительное развёртывание в LSD из-за большего LSD, или есть другие оптимизации "малого цикла". Для Sandy Bridge и Ivy Bridge это означает, что маленькие циклы должны определенно нацеливаться на число мопов, кратное 4.
Кофейное озеро ведет себя подобно Skylake1. Это имеет смысл, поскольку микроархитектура одинакова. Кофе Лейк выглядит лучше, чем Скайлэйк, ниже примерно 16 мопов, но это всего лишь эффект отключенного ЛСД в Кофе Лэйк по умолчанию. Skylake был протестирован с включенным LSD, прежде чем Intel отключил его с помощью обновления микрокода из-за проблемы безопасности. Кофейное Озеро было выпущено после того, как эта проблема была известна, поэтому ЛСД был отключен из коробки. Таким образом, для этого теста Coffee Lake использует либо DSB (для циклов ниже примерно 18 моп, который все еще может поместиться в DSB), либо устаревший декодер (для остальных циклов), что приводит к лучшим результатам при небольшом числе мопов. Циклы, где LSD накладывает накладные расходы (интересно, что для больших циклов LSD и устаревший декодер накладывают одинаковые издержки по очень разным причинам).
Наконец, мы рассмотрим 2-байтовые NOP, которые недостаточно плотны, чтобы предотвратить использование DSB (поэтому этот случай больше отражает типичный код).
Рисунок 2.1: производительность 2-байтового nop:

Опять же, результат в том же направлении, что и на предыдущем графике. Nehalem по-прежнему является узким местом с 3 мопами за цикл. Для диапазона до примерно 60-ти мопов все архитектуры, кроме Coffee Lake, используют LSD, и мы видим, что Sandy Bridge и Ivy Bridge работают немного хуже, округляясь до следующего цикла и, таким образом, достигая максимальной пропускной способности 4 моп / цикл, если число мопов в цикле кратно 4. Выше 32 мопов функция "развёртывания" в Haswell и новых уархах не имеет никакого эффекта, поэтому все примерно привязано.
Sandy Bridge на самом деле имеет несколько диапазонов мопов (например, от 36 до 44 мопов), где он работает лучше, чем новые архитектуры. Похоже, это происходит потому, что не все петли обнаруживаются LSD, и в этих диапазонах петли обслуживаются вместо DSB. Поскольку DSB, как правило, быстрее, то и Sandy Bridge в этих случаях.
Что говорит Intel
На самом деле вы можете найти раздел, специально посвященный этой теме, в Руководстве по оптимизации Intel, раздел 3.4.2.5, как отметил Андреас Абель в комментариях. Там Intel говорит:
LSD содержит микрооперации, которые создают маленькие "бесконечные" петли. Микрооперации от ЛСД распределяются в неработающем двигателе. Цикл в LSD заканчивается взятой ветвью к началу цикла. Взятая ветвь в конце цикла всегда является последней микрооперацией, выделенной в цикле. Инструкция в начале цикла всегда выделяется в следующем цикле. Если производительность кода ограничена полосой пропускания внешнего интерфейса, неиспользуемые временные интервалы выделения приводят к появлению пузыря в распределении и могут привести к снижению производительности. Пропускная способность распределения в кодовом названии микроархитектуры Intel Sandy Bridge составляет четыре микрооперации за цикл. Производительность лучше всего, когда количество микроопераций в LSD приводит к наименьшему количеству неиспользуемых слотов распределения. Вы можете использовать развёртывание цикла, чтобы контролировать количество микроопераций в LSD.
Далее они показывают пример, в котором развертывание цикла в два раза не способствует повышению производительности из-за "округления" LSD, но разворачивается тремя работами. Этот пример сильно сбивает с толку, поскольку он фактически смешивает два эффекта, так как развертывание more также уменьшает накладные расходы цикла и, следовательно, количество мопов за итерацию. Более интересный пример был бы, когда развертывание цикла меньше раз приводило к увеличению производительности из-за эффектов округления LSD.
Этот раздел, кажется, точно описывает поведение в Sandy Bridge и Ivy Bridge. Приведенные выше результаты показывают, что обе эти архитектуры работают так, как описано, и вы теряете 1, 2 или 3 слота выполнения мопов для циклов с 4N+3, 4N+2 или 4N+1 мопов соответственно.
Это не было обновлено с новым выступлением для Haswell и позже однако. Как описано в другом ответе, производительность улучшилась по сравнению с простой моделью, описанной выше, и поведение более сложное.
1 В 16 мопах есть странный выброс, когда Coffee Lake работает хуже, чем все другие архитектуры, даже Nehalem (регрессия около 50%), но, может быть, это шум измерения?
TL;DR: для плотных петель, состоящих ровно из 7 мопов, это приводит к неэффективному использованию пропускной способности при выводе из эксплуатации. Рассмотрите возможность развертывания цикла вручную, чтобы он состоял из 12 мопов.
Недавно я столкнулся с ухудшением пропускной способности при выходе на пенсию из-за петель, состоящих из 7 мопов. После того, как я провел небольшое исследование самостоятельно, быстрый поиск в Google привел меня к этой теме. А вот мои 2 цента, относящиеся к процессору Kaby Lake i7-8550U:
Как отметил @BeeOnRope, LSD отключен на таких чипах, как KbL i7-8550U.
Рассмотрим следующий макрос NASM
;rdi = 1L << 31
%macro nops 1
align 32:
%%loop:
times %1 nop
dec rdi
ja %%loop
%endmacro
Вот как "средний пенсионный коэффициент" uops_retired.retire_slots/uops_retired.total_cycle похоже:
Здесь следует отметить деградацию вывода на пенсию, когда цикл состоит из 7 мопов. Это приводит к списанию 3,5 мопов за цикл.
Среднее idq скорость доставки idq.all_dsb_cycles_any_uops / idq.dsb_cycles выглядит как
Для циклов из 7 мопов это приводит к доставке 3,5 мопов на idq за цикл. Судя только по этому счетчику, невозможно сделать вывод, доставляет ли кеш-память 4|3 или 6|1 группу.
Для циклов, состоящих из 6 мопов, это приводит к эффективному использованию пропускной способности кэша мопов - 6 мопов /c. Когда IDQ переполняется, кэш мопов бездействует, пока снова не сможет доставить 6 мопов.
Чтобы проверить, как кеш-память простаивает, давайте сравним idq.all_dsb_cycles_any_uops и циклы
Количество циклов, доставленных мопов к idq, равно количеству полных циклов для циклов из 7 мопов. Напротив, для петли в 6 мопс счетчики заметно отличаются.
Ключевые счетчики для проверки: idq_uops_not_delivered.*
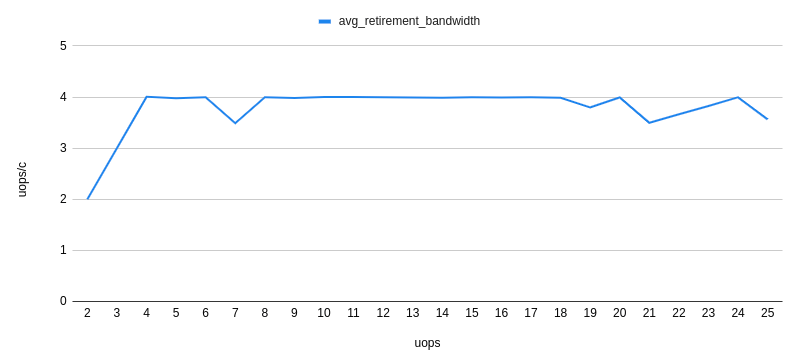
Как можно видеть для цикла из 7 мопов, Renamer принимает 4|3 группы, что приводит к неэффективному использованию пропускной способности вывода на пенсию.