UniQuery - Как найти наибольшую длину поля в файле
Я пытаюсь выяснить, как найти наибольшую длину записей для поля в файле в базе данных Unidata на основе Unix в системе MRP Manage2000 (M2k). В настоящее время у меня есть "Использование Uniquery" и "Справочник команд Uniquery" как для v7.2, так и самое близкое, что я обнаружил, это использование "LIKE" и "UNLIKE", но оно работает не совсем так, как я надеялся.
По сути, у нас есть файл QUOTES со словарем "Part_Nbr", и мне нужно найти длину самой большой записи "Part_Nbr" в этом файле. Максимальная длина поля словаря составляет 19 символов. Выполняя произвольный список записей, я вижу, что некоторые записи имеют длину данных 7 символов, а некоторые - 13 символов, но мне нужно найти наибольшую длину данных.
Заранее спасибо за вашу помощь и предложения.
С уважением,
--Ken
2 ответа
Сначала я уточню некоторые термины, чтобы мы говорили на одном языке. Вы, кажется, используете поле и запись взаимозаменяемо.
ФАЙЛ (он же TABLE for SQL folk, в данном случае "QUOTES") содержит 0 или более записей. Каждая запись состоит из нескольких ATTRIBUTES (также известный как FIELD). Вы можете ссылаться на эти атрибуты, используя элементы словаря (которые также могут создавать производные поля)
В этом случае вы хотите найти самую длинную длину данных, доступ к которым осуществляется через словарь Part_Nbr, правильно?
Предполагая, что это правильно, вы можете сделать это следующим образом
Используйте словарь
Шаг 1. Создайте элемент словаря I-типа (производное поле). Давайте назовем это Part_Nbr_Len. Вы можете сделать это в командной строке, используя UNIENTRY DICT QUOTES Part_Nbr_Len согласно изображению ниже.
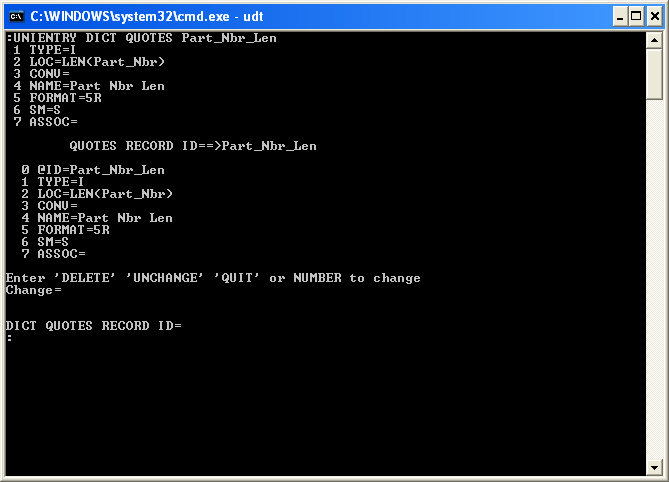
- Тип = I (он же производное поле)
- LOC = LEN (Part_Nbr) (поле представляет собой количество 1-байтовых символов в поле Part_Nbr)
- FORMAT = 5R (выравнивание по правому краю делает это поле числовым для сортировки)
- SM = S (это поле является одним значением)
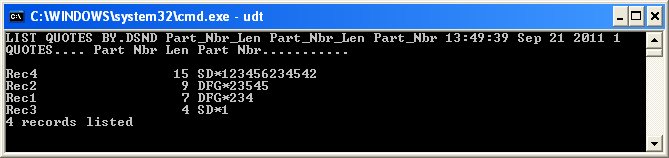
Шаг 2: Перечислите файл в порядке убывания по Part_Nbr_Len и, при желании, также укажите фактическое поле Part_Nbr. Вы делаете это с помощью следующей команды.
LIST QUOTES BY.DSND Part_Nbr_Len Part_Nbr_Len Part_Nbr
Временный взлом командной строки
В качестве альтернативы, если вы не хотите что-то постоянное, вы можете сделать небольшой взлом в командной строке:
list QUOTES BY.DSND EVAL "10000+LEN(Part_Nbr)" EVAL "LEN(Part_Nbr)" Part_Nbr
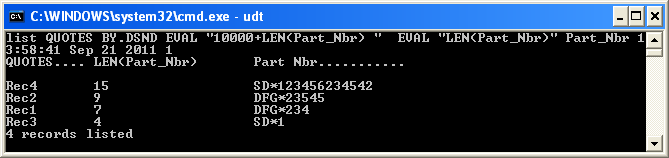
Хорошо, давайте разберемся с этим:
list-> Может или не важно, что это строчные буквы. Это позволяет вам использовать "EVAL" независимо от вашего аккаунта.EVAL-> Сделать производное поле на лету10000+LEN(Part_Nbr)-> Сортировка производного поля производится по порядку ASCII. Это означает, что 9 будет указано до 15 при сортировке по убыванию. + 10000 - это хак, означающий, что порядок ASCII будет таким же, как порядок чисел для чисел от 0 до 9999, что должно охватывать возможный диапазон в вашем случаеEVAL "LEN(Part_Nbr)"-> Показать фактическую длину поля для вас.
РЕДАКТИРОВАТЬ
Решить с помощью кода для многозначных списков
Если у вас есть атрибут MultiValued (и / или Sub-MultiValued), вам потребуется использовать подпрограмму для определения длины самого большого отдельного элемента. К счастью, вы можете иметь элемент словаря I-типа, вызывающий подпрограмму.
Первым шагом будет написать, скомпилировать и каталогизировать простую подпрограмму UniBASIC, чтобы выполнить обработку для вас:
SUBROUTINE SR.MV.MAXLEN(OUT.MAX.LEN, IN.DATA)
* OUT.MAX.LEN : Returns the length of the longest MV/SMV value
* IN.ATTRIBUTE : The multivalued list to process
OUT.MAX.LEN = 0
IN.DATA = IN.DATA<1> ;* Sanity Check. Ensure only one attribute
IF NOT(LEN(IN.DATA)) THEN RETURN ;* No Data to check
LOOP
REMOVE ELEMENT FROM IN.DATA SETTING DELIM
IF LEN(ELEMENT) > OUT.MAX.LEN THEN OUT.MAX.LEN = LEN(ELEMENT)
WHILE DELIM
REPEAT
RETURN
Для компиляции программы она должна быть в файле типа DIR. Например, если у вас есть код в файле "BP", вы можете скомпилировать его с помощью этой команды:
BASIC BP SR.MV.MAXLEN
Как вы каталогизируете это зависит от ваших потребностей. Это 3 метода:
- НЕПОСРЕДСТВЕННЫЙ
- LOCAL -> Мое предложение, если вы хотите его только в текущем аккаунте
- GLOBAL -> Мое предложение, если вы хотите, чтобы он работал во всех аккаунтах
Если у вас есть программа, скомпилированная в файле 'BP', каталогом команд для вышеупомянутого будет:
CATALOG BP SR.MV.MAXLEN DIRECTCATALOG BP SR.MV.MAXLEN LOCALCATALOG BP SR.MV.MAXLEN
После того, как подпрограмма была каталогизирована, вам нужно будет иметь LOC поле (атрибут 2) элемента словаря Part_Nbr_Len (согласно первой части этого ответа) обновлено для вызова подпрограммы и передачи ей поля для обработки:
SUBR("SR.MV.MAXLEN", Part_Nbr)
Что дает вам:
Это фантастический ответ. В более поздних версиях Unidata есть немного более простой и эффективный способ проверки самого длинного поля MV.
Если элемент DICT становится:
SUBR('-LENS', Part_Nbr);SUBR('SR.MV.MAXLEN',@1)
Основная программа может стать проще и просто найти значение MAXIMUM из многозначного списка длин:
SUBROUTINE SR.MV.MAXLEN(OUT.MAX.LEN, IN.DATA)
OUT.MAX.LEN=MAXIMUM(IN.DATA)
RETURN
Жаль, что нет встроенной функции -MAXIMUMS, чтобы полностью пропустить основную программу! Стоит прочитать раздел 5.9 документации по UniQuery по адресу: