Удалить все повторяющиеся строки в Python Pandas
pandasdrop_duplicates Функция отлично подходит для "унификации" данных. Тем не менее, один из ключевых аргументов для передачи является take_last=True или же take_last=Falseв то время как я хотел бы отбросить все строки, которые являются дубликатами в подмножестве столбцов. Это возможно?
A B C
0 foo 0 A
1 foo 1 A
2 foo 1 B
3 bar 1 A
Как пример, я хотел бы отбросить строки, которые соответствуют столбцам A а также C так что это должно отбросить строки 0 и 1.
8 ответов
Теперь это намного проще в пандах с помощью drop_duplicates и параметра keep.
import pandas as pd
df = pd.DataFrame({"A":["foo", "foo", "foo", "bar"], "B":[0,1,1,1], "C":["A","A","B","A"]})
df.drop_duplicates(subset=['A', 'C'], keep=False)
Просто хочу добавить ответ Бена на drop_duplicates:
keep: {'first', 'last', False}, по умолчанию 'first'
первый: отбросьте дубликаты за исключением первого вхождения.
последний: удалить дубликаты, кроме последнего вхождения.
False: отбросить все дубликаты.
Так установить keep Ложь, мы даем вам желаемый ответ.
DataFrame.drop_duplicates (* args, ** kwargs) Возвращает DataFrame с удаленными дублирующимися строками, опционально только с учетом определенных столбцов
Параметры: subset: метка столбца или последовательность меток, необязательно. Учитывать только определенные столбцы для выявления дубликатов, по умолчанию использовать все столбцы keep: {'first', 'last', False}, по умолчанию 'first' first: удалить дубликаты, кроме за первое вхождение. последний: удалить дубликаты, кроме последнего вхождения. False: отбросить все дубликаты. take_last: устарел inplace: логический, по умолчанию False Удалять ли дубликаты на месте или возвращать копию cols: аргумент только для kwargs подмножества [устарел] Возвраты: дедуплицированный: DataFrame
Если вы хотите, чтобы результат был сохранен в другом наборе данных:
df.drop_duplicates(keep=False)
или же
df.drop_duplicates(keep=False, inplace=False)
Если тот же набор данных необходимо обновить:
df.drop_duplicates(keep=False, inplace=True)
Приведенные выше примеры удалят все дубликаты и сохранят один, аналогичный DISTINCT * в SQL
Использование groupby а также filter
import pandas as pd
df = pd.DataFrame({"A":["foo", "foo", "foo", "bar"], "B":[0,1,1,1], "C":["A","A","B","A"]})
df.groupby(["A", "C"]).filter(lambda df:df.shape[0] == 1)
Попробуйте эти разные вещи
df = pd.DataFrame({"A":["foo", "foo", "foo", "bar","foo"], "B":[0,1,1,1,1], "C":["A","A","B","A","A"]})
>>>df.drop_duplicates( "A" , keep='first')
или
>>>df.drop_duplicates( keep='first')
или
>>>df.drop_duplicates( keep='last')
На самом деле, удаление строк 0 и 1 требует только (любые наблюдения, содержащие совпадающие A и C. сохраняются.):
In [335]:
df['AC']=df.A+df.C
In [336]:
print df.drop_duplicates('C', take_last=True) #this dataset is a special case, in general, one may need to first drop_duplicates by 'c' and then by 'a'.
A B C AC
2 foo 1 B fooB
3 bar 1 A barA
[2 rows x 4 columns]
Но я подозреваю, что вы действительно хотите этого (одно наблюдение, содержащее совпадающие А и С., сохраняется):
In [337]:
print df.drop_duplicates('AC')
A B C AC
0 foo 0 A fooA
2 foo 1 B fooB
3 bar 1 A barA
[3 rows x 4 columns]
Редактировать:
Теперь это намного понятнее, поэтому:
In [352]:
DG=df.groupby(['A', 'C'])
print pd.concat([DG.get_group(item) for item, value in DG.groups.items() if len(value)==1])
A B C
2 foo 1 B
3 bar 1 A
[2 rows x 3 columns]
Вы можете использоватьduplicated()чтобы пометить все дубликаты и отфильтровать помеченные строки. Если вам нужно назначить столбцыnew_dfпозже обязательно позвоните.copy()так что вы не получитеSettingWithCopyWarningпозже.
new_df = df[~df.duplicated(subset=['A', 'C'], keep=False)].copy()
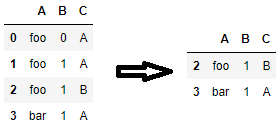
Одна приятная особенность этого метода заключается в том, что с его помощью вы можете условно удалять дубликаты. Например, чтобы удалить все повторяющиеся строки, только если столбец A равен'foo', вы можете использовать следующий код.
new_df = df[~( df.duplicated(subset=['A', 'B', 'C'], keep=False) & df['A'].eq('foo') )].copy()
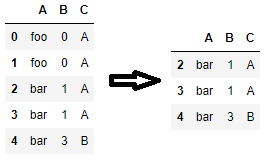
Кроме того, если вы не хотите записывать столбцы по имени, вы можете передать фрагментыdf.columnsкsubset=. Это верно и дляdrop_duplicates()также.
# to consider all columns for identifying duplicates
df[~df.duplicated(subset=df.columns, keep=False)].copy()
# the same is true for drop_duplicates
df.drop_duplicates(subset=df.columns, keep=False)
# to consider columns in positions 0 and 2 (i.e. 'A' and 'C') for identifying duplicates
df.drop_duplicates(subset=df.columns[[0, 2]], keep=False)
Если вы хотите проверить 2 столбца с помощью операторов try и exclude, это может помочь.
if "column_2" in df.columns:
try:
df[['column_1', "column_2"]] = df[['header', "column_2"]].drop_duplicates(subset = ["column_2", "column_1"] ,keep="first")
except:
df[["column_2"]] = df[["column_2"]].drop_duplicates(subset="column_2" ,keep="first")
print(f"No column_1 for {path}.")
try:
df[["column_1"]] = df[["column_1"]].drop_duplicates(subset="column_1" ,keep="first")
except:
print(f"No column_1 or column_2 for {path}.")