Уточнение списка тегов для использования с утренней звездой на пандах
Итак, у меня есть список тегов, которые я удалил с nasdaq.com для nyse.
import urllib.request
from bs4 import BeautifulSoup
import re
target = "NYSE"
def nyseTags():
ret = []
for k in range(1,64):
source = "https://www.nasdaq.com/screening/companies-by-industry.aspx?exchange=NYSE&page="+str(k)
print("ReadingPage:"+source)
filehandle = urllib.request.urlopen(source)
soup = BeautifulSoup(filehandle.read(), "html.parser")
lines = soup.findAll("tr",{})
#print(len(lines))
temp = []
for n,k in enumerate(lines):
if(n == 0):
continue
try:
tds = k.findAll("td",{})
pattern = re.compile(r'\s+')
temp.append(re.sub(pattern, '', tds[1].getText()))
print(str(n)+" : "+temp[-1])
except:
pass
ret += temp
return(ret)
def arrToCsv(arr,fn):
strRep = "\n".join(arr)
fh = open(fn,"w")
fh.write(strRep)
fh.close()
arrToCsv(nyseTags(),"nyseTags.lst")
Который предоставляет мой начальный список:
DDD
MMM
WBAI
...
XOXO
XPO
XYL
AUY
YELP
YEXT
YRD
YPF
YUMC
YUM
ZAYO
ZEN
ZBH
ZB^A
ZB^G
ZB^H
ZBK
ZOES
ZTS
ZTO
ZUO
ZYME
Теперь я знаю, что это не все good теги для моих нужд, так как я ищу, у меня есть доступ к 2-летним дневным окнам для моих целей.
Поэтому я написал следующий скрипт, чтобы отфильтровать теги, для которых я не мог получить данные 2 года назад, но он зависает после того, что выглядит как многообещающее начало.
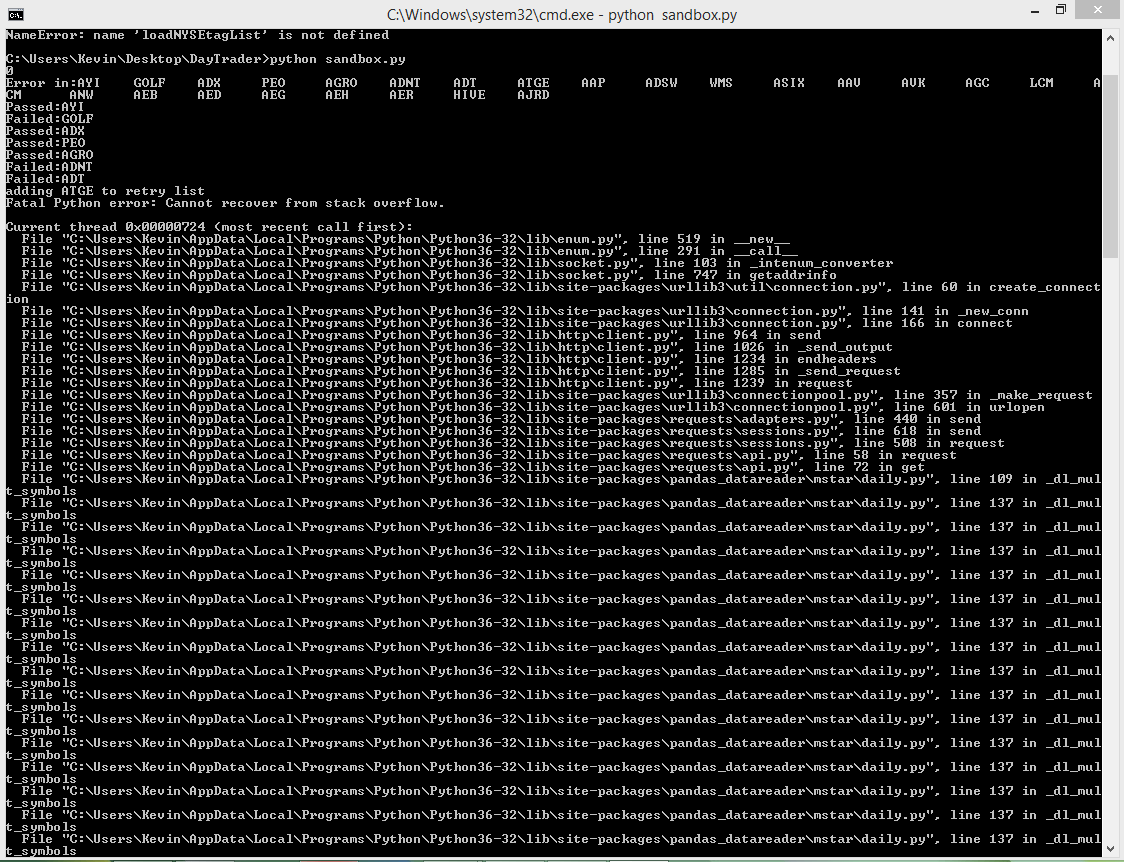
Я не уверен, почему этот сценарий не проходит через весь список, но любой вход был бы хорош!
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
import pandas as pd
import pandas_datareader.data as web
import os
import operator
#C:\Users\Kevin\AppData\Local\Programs\Python\Python36-32\lib\site-packages\pandas_datareader\fred.py
style.use('ggplot')
__NOW__ = dt.datetime.now()
__2YearsAgo1__ = __NOW__ - dt.timedelta(days=725)
__2YearsAgo__ = __NOW__ - dt.timedelta(days=731)
def fetch(tag,start,end):# start and end should be dt.datetime(), tag can be a string or array of strings
if(type(tag) == str):
df = web.DataReader(tag, 'morningstar', start, end)
return(df)
else:
df = web.DataReader(tag, 'morningstar', start, end)
ret = {}
for tag, data in df.groupby(level=0):
if(type(data)==pd.core.frame.DataFrame):
ret[tag]=data
return(ret)
def scrubTags(tagList):
ret = []
fails = []
for n in range(0,int(len(tagList)/25)+1):
if(n==len(tagList)/25):
propTags = tagList[n*25:len(tagList)]
else:
propTags = tagList[n*25:n*25+25]
try:
temp = fetch(propTags,__2YearsAgo__,__2YearsAgo1__)
ret += propTags
print(str(n))
except:
print("Error in:"+"\t".join(propTags))
for k in propTags:
try:
temp = fetch(k,__2YearsAgo__,__2YearsAgo1__)
print("Passed:"+k)
ret.append(k)
except:
fails.append(k)
print("Failed:"+k)
#fails += propTags
return((ret,fails))
def arrToCsv(arr,fn):
strRep = "\n".join(arr)
fh = open(fn,"w")
fh.write(strRep)
fh.close()
def loadNYSEtagList():
fh = open("NYSETags.lst","r")
text = fh.read()
fh.close()
return(text.split("\n"))
tagList = loadNYSEtagList()
scrubTags = scrubTags(tagList)
arrToCsv(scrubTags[0],"Scrubed_505_nyseTags.lst")
arrToCsv(scrubTags[1],"Failed_505_nyseTags.lst")
Кроме того -> Я знаю, что странно иметь словарь, полный фреймов данных вместо использования мультииндексации, но я не думаю, что это является причиной моей проблемы.