SQL-соединение: где предложение по сравнению с предложением
После прочтения, это не дубликат явных и неявных объединений SQL. Ответ может быть связан (или даже один и тот же), но вопрос в другом.
Какая разница и что должно быть в каждом?
Если я правильно понимаю теорию, оптимизатор запросов должен быть в состоянии использовать оба взаимозаменяемо.
23 ответа
Они не одно и то же.
Рассмотрим эти запросы:
SELECT *
FROM Orders
LEFT JOIN OrderLines ON OrderLines.OrderID=Orders.ID
WHERE Orders.ID = 12345
а также
SELECT *
FROM Orders
LEFT JOIN OrderLines ON OrderLines.OrderID=Orders.ID
AND Orders.ID = 12345
Первый вернет заказ и его строки, если таковые имеются, для номера заказа 12345, Второй вернет все заказы, но только заказ 12345 будет иметь любые строки, связанные с ним.
С INNER JOINпункты эффективно эквивалентны. Однако только то, что они функционально одинаковы, поскольку они дают одинаковые результаты, не означает, что два вида предложений имеют одинаковое семантическое значение.
- Не имеет значения для внутренних соединений
Вопросы для внешних объединений
а.
WHEREпункт: после вступления. Записи будут отфильтрованы после объединения.б.
ONоговорка - до присоединения. Записи (из правой таблицы) будут отфильтрованы перед присоединением. Это может закончиться как нуль в результате (так как OUTER join).
Пример: рассмотрим приведенные ниже таблицы:
1. documents:
| id | name |
--------|-------------|
| 1 | Document1 |
| 2 | Document2 |
| 3 | Document3 |
| 4 | Document4 |
| 5 | Document5 |
2. downloads:
| id | document_id | username |
|------|---------------|----------|
| 1 | 1 | sandeep |
| 2 | 1 | simi |
| 3 | 2 | sandeep |
| 4 | 2 | reya |
| 5 | 3 | simi |
а) внутри WHERE пункт:
SELECT documents.name, downloads.id
FROM documents
LEFT OUTER JOIN downloads
ON documents.id = downloads.document_id
WHERE username = 'sandeep'
For above query the intermediate join table will look like this.
| id(from documents) | name | id (from downloads) | document_id | username |
|--------------------|--------------|---------------------|-------------|----------|
| 1 | Document1 | 1 | 1 | sandeep |
| 1 | Document1 | 2 | 1 | simi |
| 2 | Document2 | 3 | 2 | sandeep |
| 2 | Document2 | 4 | 2 | reya |
| 3 | Document3 | 5 | 3 | simi |
| 4 | Document4 | NULL | NULL | NULL |
| 5 | Document5 | NULL | NULL | NULL |
After applying the `WHERE` clause and selecting the listed attributes, the result will be:
| name | id |
|--------------|----|
| Document1 | 1 |
| Document2 | 3 |
б) внутри JOIN пункт
SELECT documents.name, downloads.id
FROM documents
LEFT OUTER JOIN downloads
ON documents.id = downloads.document_id
AND username = 'sandeep'
For above query the intermediate join table will look like this.
| id(from documents) | name | id (from downloads) | document_id | username |
|--------------------|--------------|---------------------|-------------|----------|
| 1 | Document1 | 1 | 1 | sandeep |
| 2 | Document2 | 3 | 2 | sandeep |
| 3 | Document3 | NULL | NULL | NULL |
| 4 | Document4 | NULL | NULL | NULL |
| 5 | Document5 | NULL | NULL | NULL |
Notice how the rows in `documents` that did not match both the conditions are populated with `NULL` values.
After Selecting the listed attributes, the result will be:
| name | id |
|------------|------|
| Document1 | 1 |
| Document2 | 3 |
| Document3 | NULL |
| Document4 | NULL |
| Document5 | NULL |
На INNER JOINs они взаимозаменяемы, и оптимизатор переставит их по своему желанию.
На OUTER JOINs, они не обязательно взаимозаменяемы, в зависимости от того, от какой стороны соединения они зависят.
Я помещаю их в любом месте в зависимости от читабельности.
Я делаю это так:
Всегда ставьте условия соединения в
ONпункт, если вы делаетеINNER JOIN, Поэтому не добавляйте условия WHERE в предложение ON, поместите их вWHEREпункт.Если вы делаете
LEFT JOIN, добавьте любые условия WHERE кONпредложение для таблицы в правой части соединения. Это необходимо, потому что добавление предложения WHERE, которое ссылается на правую сторону объединения, преобразует соединение в INNER JOIN.Исключение составляют случаи, когда вы ищете записи, которых нет в конкретной таблице. Вы бы добавили ссылку на уникальный идентификатор (который никогда не равен NULL) в таблице RIGHT JOIN к предложению WHERE следующим образом:
WHERE t2.idfield IS NULL, Таким образом, единственный раз, когда вы должны ссылаться на таблицу с правой стороны объединения, это найти те записи, которых нет в таблице.
На внутреннем соединении они означают одно и то же. Однако во внешнем соединении вы получите разные результаты в зависимости от того, поместите ли вы условие соединения в предложение WHERE против ON. Взгляните на этот связанный вопрос и этот ответ (мной).
Я думаю, что имеет смысл иметь привычку всегда помещать условие соединения в предложение ON (если только это не внешнее соединение, а вы действительно хотите его в предложении where), поскольку оно делает его понятнее любому, кто читает ваш запрос на каких условиях объединяются таблицы, а также помогает предотвратить появление в предложении WHERE десятков строк.
Эта статья ясно объясняет разницу. Это также объясняет "ON join_condition против WHERE join_condition или join_alias имеет значение null".
Предложение WHERE фильтрует как левую, так и правую сторону JOIN, а предложение ON всегда фильтрует только правую сторону.
- Если вы всегда хотите получить строки с левой стороны и только ПРИСОЕДИНИТЬСЯ, если какое-либо условие соответствует, тогда вам следует использовать предложение ON.
- Если вы хотите отфильтровать продукт объединения обеих сторон, вам следует использовать предложение WHERE.
Давайте рассмотрим эти таблицы:
id | SomeData
В
id | id_A | SomeOtherData
id_A быть внешним ключом к таблице A
Написание этого запроса:
SELECT *
FROM A
LEFT JOIN B
ON A.id = B.id_A;
Предоставим такой результат:
/ : part of the result
B
+---------------------------------+
A | |
+---------------------+-------+ |
|/////////////////////|///////| |
|/////////////////////|///////| |
|/////////////////////|///////| |
|/////////////////////|///////| |
|/////////////////////+-------+-------------------------+
|/////////////////////////////|
+-----------------------------+
То, что находится в A, но не в B, означает, что есть нулевые значения для B.
Теперь давайте рассмотрим конкретную часть в B.id_Aи выделите его из предыдущего результата:
/ : part of the result
* : part of the result with the specific B.id_A
B
+---------------------------------+
A | |
+---------------------+-------+ |
|/////////////////////|///////| |
|/////////////////////|///////| |
|/////////////////////+---+///| |
|/////////////////////|***|///| |
|/////////////////////+---+---+-------------------------+
|/////////////////////////////|
+-----------------------------+
Написание этого запроса:
SELECT *
FROM A
LEFT JOIN B
ON A.id = B.id_A
AND B.id_A = SpecificPart;
Предоставим такой результат:
/ : part of the result
* : part of the result with the specific B.id_A
B
+---------------------------------+
A | |
+---------------------+-------+ |
|/////////////////////| | |
|/////////////////////| | |
|/////////////////////+---+ | |
|/////////////////////|***| | |
|/////////////////////+---+---+-------------------------+
|/////////////////////////////|
+-----------------------------+
Потому что это удаляет во внутреннем соединении значения, которые не находятся в B.id_A = SpecificPart
Теперь давайте изменим запрос на это:
SELECT *
FROM A
LEFT JOIN B
ON A.id = B.id_A
WHERE B.id_A = SpecificPart;
Результат сейчас:
/ : part of the result
* : part of the result with the specific B.id_A
B
+---------------------------------+
A | |
+---------------------+-------+ |
| | | |
| | | |
| +---+ | |
| |***| | |
| +---+---+-------------------------+
| |
+-----------------------------+
Потому что весь результат фильтруется против B.id_A = SpecificPart удаление частей B.id_A = NULL, которые находятся в A, которые не находятся в B
Существует большое различие между предложением where и предложением on, когда речь идет о левом соединении.
Вот пример:
mysql> desc t1;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | NO | | NULL | |
| fid | int(11) | NO | | NULL | |
| v | varchar(20) | NO | | NULL | |
+-------+-------------+------+-----+---------+-------+
Там есть идентификатор таблицы t2.
mysql> desc t2;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | NO | | NULL | |
| v | varchar(10) | NO | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)
Запрос на "на оговорку":
mysql> SELECT * FROM `t1` left join t2 on fid = t2.id AND t1.v = 'K'
-> ;
+----+-----+---+------+------+
| id | fid | v | id | v |
+----+-----+---+------+------+
| 1 | 1 | H | NULL | NULL |
| 2 | 1 | B | NULL | NULL |
| 3 | 2 | H | NULL | NULL |
| 4 | 7 | K | NULL | NULL |
| 5 | 5 | L | NULL | NULL |
+----+-----+---+------+------+
5 rows in set (0.00 sec)
Запрос "где оговорка":
mysql> SELECT * FROM `t1` left join t2 on fid = t2.id where t1.v = 'K';
+----+-----+---+------+------+
| id | fid | v | id | v |
+----+-----+---+------+------+
| 4 | 7 | K | NULL | NULL |
+----+-----+---+------+------+
1 row in set (0.00 sec)
Ясно, что первый запрос возвращает запись от t1 и ее зависимую строку от t2, если таковая имеется, для строки t1.v = 'K'.
Второй запрос возвращает строки из t1, но только для t1.v = 'K' будет иметь любую связанную строку с ним.
С точки зрения оптимизатора, не должно иметь значения, определяете ли вы свои предложения соединения с помощью ON или WHERE.
Однако, IMHO, я думаю, что гораздо проще использовать предложение ON при выполнении объединений. Таким образом, у вас есть определенный раздел вашего запроса, который определяет, как обрабатывается соединение, а не смешивается с остальными предложениями WHERE.
Вы пытаетесь объединить данные или отфильтровать данные?
Для удобства чтения имеет смысл выделить эти варианты использования в ON и WHERE соответственно.
- объединить данные в ПО
- фильтровать данные в ГДЕ
Это может стать очень трудным для чтения запроса, в котором в условии WHERE существуют условие JOIN и условие фильтрации.
С точки зрения производительности разницы не должно быть, хотя разные типы SQL иногда обрабатывают планирование запросов по-разному, поэтому стоит попробовать ¯\_(ツ)_/¯ (Имейте в виду, что кэширование влияет на скорость запроса)
Также, как отметили другие, если вы используете внешнее объединение, вы получите другие результаты, если вы поместите условие фильтра в предложение ON, поскольку оно влияет только на одну из таблиц.
Я написал более подробный пост об этом здесь: https://dataschool.com/learn/difference-between-where-and-on-in-sql
В SQL предложения "WHERE" и "ON" являются своего рода условными выражениями состояния, но основное отличие между ними заключается в том, что выражение "Where" используется в операторах выбора / обновления для указания условий, тогда как предложение "ON" используется в соединениях, где он проверяет или проверяет, совпадают ли записи в таблицах назначения и источника, до объединения таблиц
Например: - "ГДЕ"
ВЫБРАТЬ * ОТ сотрудника, ГДЕ employee_id=101
Например: - "ВКЛ"
* Есть две таблицы employee и employee_details, соответствующие столбцы - employee_id.*
ВЫБЕРИТЕ * ИЗ СОТРУДНИКА ВНУТРЕННЕГО СОЕДИНЕНИЯ employee_details ON employee.employee_id = employee_details.employee_id
Надеюсь, я ответил на ваш вопрос. Вернемся за разъяснениями.
Я думаю, что это различие лучше всего объяснить с помощью логического порядка операций в SQL, который упрощен:
FROM(включая присоединения)WHEREGROUP BY- Скопления
HAVINGWINDOWSELECTDISTINCTUNION,INTERSECT,EXCEPTORDER BYOFFSETFETCH
Объединения - это не предложение оператора select, а оператор внутри FROM, Таким образом, все ON пункты, принадлежащие к соответствующему JOIN оператор "уже произошел" логически к тому времени, когда логическая обработка достигает WHERE пункт. Это означает, что в случае LEFT JOINНапример, семантика внешнего соединения уже произошла к тому времени, когда WHERE пункт прилагается.
Я объяснил следующий пример более подробно в этом блоге. При выполнении этого запроса:
SELECT a.actor_id, a.first_name, a.last_name, count(fa.film_id)
FROM actor a
LEFT JOIN film_actor fa ON a.actor_id = fa.actor_id
WHERE film_id < 10
GROUP BY a.actor_id, a.first_name, a.last_name
ORDER BY count(fa.film_id) ASC;
LEFT JOIN на самом деле не имеет никакого полезного эффекта, потому что даже если актер не сыграл в фильме, он будет отфильтрован, так как его FILM_ID будет NULL и WHERE предложение отфильтрует такую строку. Результат примерно такой:
ACTOR_ID FIRST_NAME LAST_NAME COUNT
--------------------------------------
194 MERYL ALLEN 1
198 MARY KEITEL 1
30 SANDRA PECK 1
85 MINNIE ZELLWEGER 1
123 JULIANNE DENCH 1
Т.е. как будто мы внутренне соединили две таблицы. Если мы переместим предикат фильтра в ON предложение теперь становится критерием для внешнего соединения:
SELECT a.actor_id, a.first_name, a.last_name, count(fa.film_id)
FROM actor a
LEFT JOIN film_actor fa ON a.actor_id = fa.actor_id
AND film_id < 10
GROUP BY a.actor_id, a.first_name, a.last_name
ORDER BY count(fa.film_id) ASC;
Значение результата будет содержать актеров без каких-либо фильмов или без каких-либо фильмов с FILM_ID < 10
ACTOR_ID FIRST_NAME LAST_NAME COUNT
-----------------------------------------
3 ED CHASE 0
4 JENNIFER DAVIS 0
5 JOHNNY LOLLOBRIGIDA 0
6 BETTE NICHOLSON 0
...
1 PENELOPE GUINESS 1
200 THORA TEMPLE 1
2 NICK WAHLBERG 1
198 MARY KEITEL 1
Короче
Всегда ставьте свой предикат там, где это логично.
Для лучшей производительности таблицы должны иметь специальный индексированный столбец для использования в JOINS .
так что если столбец, к которому вы относитесь, не является одним из тех проиндексированных столбцов, то я подозреваю, что лучше хранить его в ГДЕ
поэтому вы ПРИСОЕДИНЯЕТЕСЬ, используя индексированные столбцы, затем после СОЕДИНЕНИЯ вы запускаете условие для неиндексированного столбца.
Обычно фильтрация обрабатывается в предложении WHERE, когда две таблицы уже объединены. Однако возможно, что вы захотите отфильтровать одну или обе таблицы перед тем, как присоединиться к ним. то есть предложение where применяется ко всему набору результатов, тогда как предложение on относится только к рассматриваемому соединению.
Для внутреннего соединения WHERE а также ON могут быть использованы взаимозаменяемо. На самом деле, можно использовать ON в коррелированном подзапросе. Например:
update mytable
set myscore=100
where exists (
select 1 from table1
inner join table2
on (table2.key = mytable.key)
inner join table3
on (table3.key = table2.key and table3.key = table1.key)
...
)
Это (ИМХО) совершенно запутывает человека, и очень легко забыть связать table1 к чему-либо (потому что в таблице "driver" нет предложения "on"), но это допустимо.
Они буквально эквивалентны.
В большинстве баз данных с открытым исходным кодом (наиболее известные примеры в MySql и postgresql) планирование запросов является вариантом классического алгоритма, представленного в разделе " Выбор пути доступа в системе управления реляционными базами данных" (Селинджер и др., 1979). В этом подходе условия бывают двух типов
- условия, относящиеся к одной таблице (используются для фильтрации)
- условия, относящиеся к двум таблицам (обрабатываются как условия соединения, независимо от того, где они появляются)
В частности, в MySql, отслеживая оптимизатор, вы можете убедиться, что
join .. onпри разборе условия заменяются эквивалентными
whereусловия. Похожая вещь происходит в postgresql (хотя нет возможности увидеть это в журнале, вы должны прочитать описание источника).
В любом случае, суть в том, что разница между двумя вариантами синтаксиса теряется на этапе синтаксического анализа / перезаписи запроса, она даже не достигает фазы планирования и выполнения запроса. Таким образом, нет никаких сомнений в том, эквивалентны ли они с точки зрения производительности, они становятся идентичными задолго до того, как достигают фазы выполнения.
Вы можете использовать
explain, чтобы убедиться, что они создают идентичные планы. Например, в postgres план будет содержать
join предложение, даже если вы не использовали
join..onсинтаксис где угодно.
Oracle и SQL-сервер не являются открытым исходным кодом, но, насколько мне известно, они основаны на правилах эквивалентности (аналогичных правилам в реляционной алгебре), и они также создают идентичные планы выполнения в обоих случаях.
Очевидно, что эти два стиля синтаксиса не эквивалентны для внешних объединений, для тех, которые вам нужно использовать
join ... onсинтаксис
Я думаю, что это эффект последовательности соединения. В верхнем левом случае объединения сначала выполняется левое соединение SQL, а затем - фильтр там. В случае сбоя сначала найдите Orders.ID=12345, а затем присоединитесь.
Что касается вашего вопроса,
Это одно и то же как 'on', так и 'where' для внутреннего соединения, если ваш сервер может это получить:
select * from a inner join b on a.c = b.c
а также
select * from a inner join b where a.c = b.c
Вариант "где" известен не всем переводчикам, поэтому, возможно, его следует избегать. И, конечно же, оговорка о включении более ясна.
Чтобы добавить в ответ Джоэла Кохорна, я добавлю некоторую информацию об оптимизации, специфичную для sqlite (другие варианты SQL могут вести себя иначе). В исходном примере LEFT JOINs имеют разный результат в зависимости от того, используете ли вы или. Вот немного измененный пример для иллюстрации:
SELECT *
FROM Orders
LEFT JOIN OrderLines ON Orders.ID = OrderLines.OrderID
WHERE Orders.Username = OrderLines.Username
против
SELECT *
FROM Orders
LEFT JOIN OrderLines ON Orders.ID = OrderLines.OrderID
AND Orders.Username = OrderLines.Username
Теперь в исходном ответе говорится, что если вы используете простое внутреннее соединение вместо левого соединения, результат обоих запросов будет одинаковым, но план выполнения будет отличаться. Недавно я понял, что семантическая разница между ними заключается в том, что первый заставляет оптимизатор запросов использовать индекс, связанный с
Иногда оптимизатор угадывает неверно, и вам нужно принудительно установить определенный план выполнения. В этом случае предположим, что оптимизатор SQLite ошибочно приходит к выводу, что самый быстрый способ выполнить это соединение - это использовать индекс, когда вы знаете из эмпирического тестирования, что индекс по нему доставит ваш запрос быстрее.
В этом случае бывший
а. Предложение WHERE: после присоединения записи будут отфильтрованы.
б. Предложение ON - перед присоединением записи (из правой таблицы) будут отфильтрованы.
Это важно: посмотрите, например, это когда вы используете предложение WHERE в конце,
где cat.category имеет значение null или cat.category <> 'OTHER'
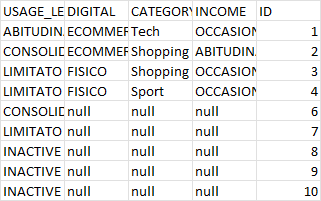
и здесь вы используете предложение AND при присоединении
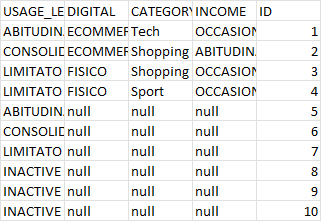
категория «ДРУГОЕ» или категория имеет значение null (я не знаю, почему она не показывает знак равенства).
Поскольку, когда вы присоединяетесь к ней, вы принимаете отфильтрованное значение как NULL
Принятый ответ идеален. Просто чтобы облегчить понимание на более наглядном примере.
CREATE TABLE menu (
id INTEGER,
item_name VARCHAR(45)
);
CREATE TABLE orders (
menu_id INTEGER,
customer_name VARCHAR(45)
);
insert into
menu(id, item_name)
values (1, 'burger'), (2, 'sandwich'), (3, 'cake');
insert into
orders(menu_id, customer_name)
values (1, 'ben'), (1, 'betty'), (2, 'sandra'), (3, 'cathy');
menu
+----+------------+
| id | item_name |
+----+------------+
| 1 | burger |
| 2 | sandwich |
| 3 | cake |
+----+------------+
orders
+---------+----------------+
| menu_id | customer_name |
+---------+----------------+
| 1 | ben |
| 1 | betty |
| 2 | sandra |
| 3 | cathy |
+---------+----------------+
SELECT *
FROM menu
LEFT JOIN orders
ON menu.id = orders.menu_id
WHERE
menu.id = 1;
+----+------------+----------+----------------+
| id | item_name | menu_id | customer_name |
+----+------------+----------+----------------+
| 1 | burger | 1 | ben |
| 1 | burger | 1 | betty |
+----+------------+----------+----------------+
SELECT *
FROM menu
LEFT JOIN orders
ON menu.id = orders.menu_id AND
menu.id = 1;
+----+------------+----------+----------------+
| id | item_name | menu_id | customer_name |
+----+------------+----------+----------------+
| 1 | burger | 1 | ben |
| 1 | burger | 1 | betty |
| 2 | sandwich | NULL | NULL |
| 3 | cake | NULL | NULL |
+----+------------+----------+----------------+
Это мое решение.
SELECT song_ID,songs.fullname, singers.fullname
FROM music JOIN songs ON songs.ID = music.song_ID
JOIN singers ON singers.ID = music.singer_ID
GROUP BY songs.fullname
Вы должны иметь GROUP BY заставить его работать.
Надеюсь, это поможет.