Внутренняя работа искры
Сейчас дни Spark в процессе. Spark использовал язык Scala для загрузки и выполнения программы, а также Python и Java. СДР используется для хранения данных. Но я не могу понять архитектуру Spark, как она работает внутри.
Скажите, пожалуйста, Spark Architecture и как она работает внутри?
3 ответа
Даже когда я искал в Интернете, чтобы узнать о внутренностях Spark, вот что я мог бы узнать и поделиться здесь,
Spark вращается вокруг концепции отказоустойчивого распределенного набора данных (RDD), который представляет собой отказоустойчивый набор элементов, с которыми можно работать параллельно. СДР поддерживают два типа операций: преобразования, которые создают новый набор данных из существующего, и действия, которые возвращают значение программе драйвера после выполнения вычисления в наборе данных.
Spark преобразует преобразования RDD в нечто, называемое DAG (направленный ациклический граф), и начинает выполнение,
На высоком уровне, когда в RDD вызывается какое-либо действие, Spark создает группу DAG и отправляет ее планировщику DAG.
Планировщик DAG делит операторов на этапы задач. Этап состоит из задач, основанных на разделах входных данных. Планировщик DAG объединяет операторов. Например, многие операторы карты могут быть запланированы в один этап. Конечный результат планировщика DAG - это набор этапов.
Этапы передаются планировщику задач. Планировщик задач запускает задачи через диспетчер кластеров (Spark Standalone/Yarn/Mesos). Планировщик задач не знает о зависимостях этапов.
Работник выполняет задачи на Рабе.
Давайте рассмотрим, как Spark создает DAG.
На высоком уровне есть два преобразования, которые могут быть применены к СДР, а именно узкое преобразование и широкое преобразование. Широкие преобразования в основном приводят к границам стадии.
Узкое преобразование - не требует перетасовки данных между разделами. например, карта, фильтр и т. д.
широкое преобразование - требует, чтобы данные были перетасованы, например, lowerByKey и т. д.
Давайте рассмотрим пример подсчета количества сообщений журнала на каждом уровне серьезности,
Ниже приведен файл журнала, который начинается с уровня серьезности,
INFO I'm Info message
WARN I'm a Warn message
INFO I'm another Info message
и создайте следующий код Scala для извлечения того же самого,
val input = sc.textFile("log.txt")
val splitedLines = input.map(line => line.split(" "))
.map(words => (words(0), 1))
.reduceByKey{(a,b) => a + b}
Эта последовательность команд неявно определяет группу DAG объектов RDD (линия RDD), которая будет использоваться позже при вызове действия. Каждый СДР поддерживает указатель на одного или нескольких родителей, а также метаданные о том, какие у него отношения с родителем. Например, когда мы вызываем val b = a.map() в RDD, RDD b сохраняет ссылку на своего родителя a, это линия.
Чтобы отобразить происхождение RDD, Spark предоставляет метод отладки toDebugString(). Например, выполнение toDebugString() для RDD splitedLines выведет следующее:
(2) ShuffledRDD[6] at reduceByKey at <console>:25 []
+-(2) MapPartitionsRDD[5] at map at <console>:24 []
| MapPartitionsRDD[4] at map at <console>:23 []
| log.txt MapPartitionsRDD[1] at textFile at <console>:21 []
| log.txt HadoopRDD[0] at textFile at <console>:21 []
Первая строка (снизу) показывает вход RDD. Мы создали этот RDD, вызвав sc.textFile(). Ниже приведено более схематичное представление графика DAG, созданного из данного СДР.

После того как группа DAG собрана, планировщик Spark создает физический план выполнения. Как упоминалось выше, планировщик DAG разбивает график на несколько этапов, этапы создаются на основе преобразований. Узкие преобразования будут сгруппированы (выстроены в трубу) вместе в одну стадию. Так что для нашего примера Spark создаст два этапа выполнения следующим образом:

Планировщик DAG затем передает этапы в планировщик задач. Количество отправленных задач зависит от количества разделов, присутствующих в текстовом файле. В примере с Fox мы рассмотрим 4 раздела в этом примере, тогда будет 4 набора задач, которые будут создаваться и передаваться параллельно при условии наличия достаточного количества подчиненных устройств / ядер. Ниже диаграмма иллюстрирует это более подробно,

Для получения более подробной информации я предлагаю вам просмотреть следующие видеоролики на YouTube, где создатели Spark подробно рассказывают о DAG, плане выполнения и сроке службы.
На диаграмме ниже показано, как Apache Spark работает внутри:
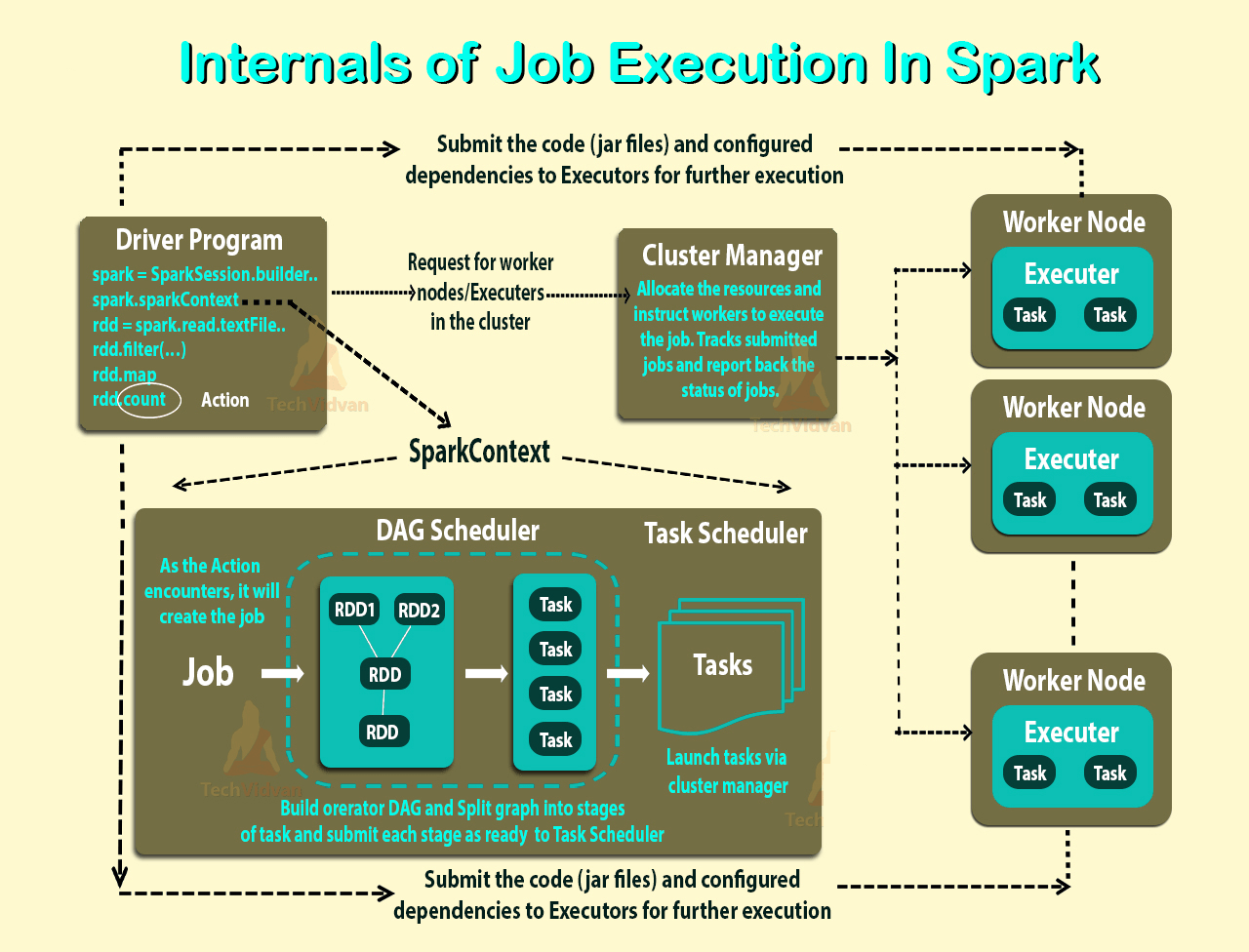
Вот некоторые ЖАРГОНЫ из Apache Spark, которые я буду использовать.
Задание:- Фрагмент кода, который считывает некоторый ввод из HDFS или локально, выполняет некоторые вычисления с данными и записывает некоторые выходные данные.
Этапы:- Работа разделена на этапы. Этапы классифицируются как карта или этапы сокращения (это легче понять, если вы работали с Hadoop и хотите сопоставить). Этапы разделены на основе вычислительных границ, все вычисления (операторы) не могут быть обновлены на одном этапе. Это происходит на многих стадиях.
Задачи:- На каждом этапе есть несколько задач, по одной задаче на раздел. Одна задача выполняется на одном разделе данных на одном исполнителе (машине).
DAG:- DAG означает направленный ациклический граф, в данном контексте это DAG операторов.
Исполнитель: процесс, ответственный за выполнение задачи.
Драйвер: программа/процесс, отвечающий за выполнение задания через Spark Engine.
Мастер: машина, на которой работает программа Драйвер.
Slave: машина, на которой работает программа Executor.
Все задания в spark состоят из серии операторов и выполняются на наборе данных. Все операторы в задании используются для построения DAG (направленного ациклического графа). DAG оптимизируется за счет перестановки и объединения операторов, где это возможно. Например, предположим, что вам нужно отправить задание Spark, содержащее операцию сопоставления, за которой следует операция фильтрации. Оптимизатор Spark DAG изменит порядок этих операторов, поскольку фильтрация уменьшит количество записей, подлежащих обработке карты.
Spark имеет небольшую кодовую базу, а система разделена на несколько уровней. У каждого слоя есть определенные обязанности. Слои независимы друг от друга.
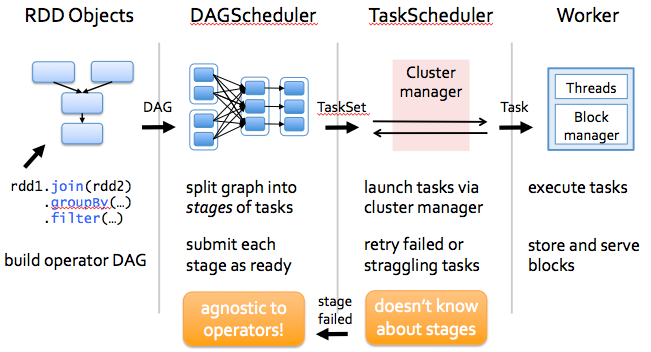
- Первый уровень — это интерпретатор, Spark использует интерпретатор Scala с некоторыми модификациями.
- Когда вы вводите свой код в консоль искры (создавая RDD и применяя операторы), Spark создает график операторов.
- Когда пользователь запускает действие (например, сбор), график отправляется планировщику DAG. Планировщик DAG делит граф оператора на этапы (сопоставление и сокращение).
- Этап состоит из задач, основанных на разделах входных данных. Планировщик DAG объединяет операторов вместе для оптимизации графа. Например, многие операторы карты могут быть запланированы в один этап. Эта оптимизация является ключом к производительности Sparks. Конечным результатом планировщика DAG является набор этапов.
- Этапы передаются планировщику заданий. Планировщик задач запускает задачи через менеджер кластера (Spark Standalone/Yarn/Mesos). Планировщик задач не знает о зависимостях между этапами.
- Worker выполняет задачи на Slave. Для каждого JOB запускается новая JVM. Рабочий знает только о коде, который ему передается.
Spark кэширует данные для обработки, что позволяет мне обрабатывать их в 100 раз быстрее, чем Hadoop. Spark обладает широкими возможностями настройки и может использовать существующие компоненты, уже существующие в экосистеме Hadoop. Это позволило искре расти в геометрической прогрессии, и вскоре многие организации уже используют ее в производственной среде.