PowerShell Core не распознает юникод
У меня есть простой сценарий PowerShell Core:
$Message = [IO.File]::ReadAllText("$PSScriptRoot\русский.txt", [System.Text.Encoding]::Default)
$Message
Насколько я знаю, PowerShell Core по умолчанию является UTF-8. Однако, как вы можете видеть в выводе, он на самом деле опасается хуже, чем PowerShell 5.1 в отношении символов юникода.
Тот же скрипт отлично работает на PowerShell 5.1
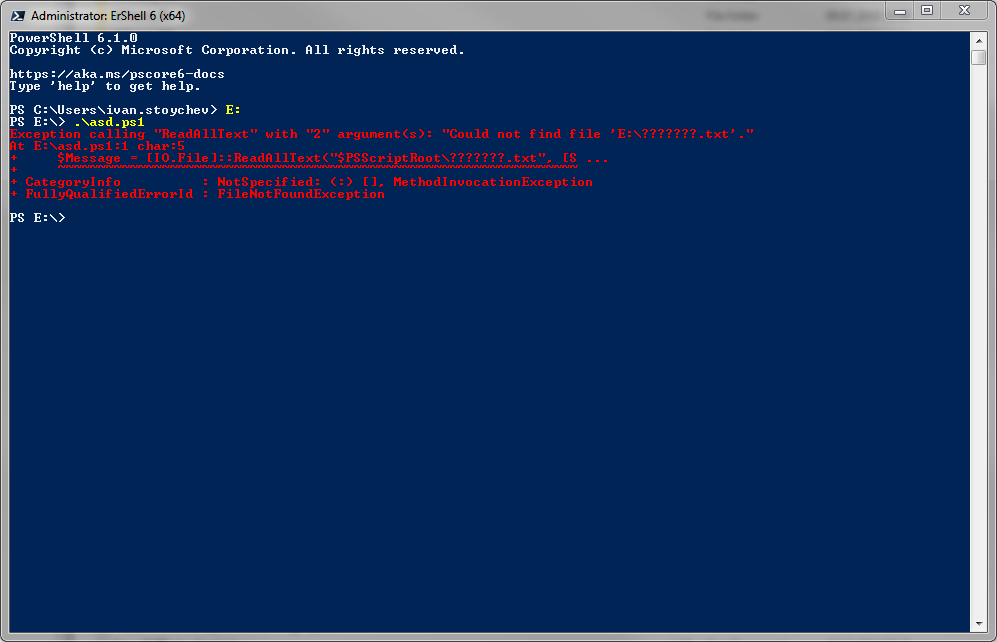
Изменение "ReadAllText" на
$Message = [IO.File]::ReadAllText("$PSScriptRoot\русский.txt")
ничего не изменится (как и не должно быть, так как это кодировка для операции чтения, но для ясности:)).
2 ответа
Файлы не содержат символов, они содержат байты. Чтобы получить символы из байтов, вам нужно применить некоторую кодировку. Если вы применяете разные кодировки для одних и тех же байтов, вы можете получить разные символы в результатах.
Взяв вашу байтовую строку в качестве примера:
PS> $ByteArray = [Byte[]]('24-4D-65-73-73-61-67-65-20-3D-20-5B-49-4F-2E-46-69-6C-65-5D-3A-3A-52-65-61-64-41-6C-6C-54-65-78-74-28-22-24-50-53-53-63-72-69-70-74-52-6F-6F-74-5C-F0-F3-F1-F1-EA-E8-E9-2E-74-78-74-22-2C-20-5B-53-79-73-74-65-6D-2E-54-65-78-74-2E-45-6E-63-6F-64-69-6E-67-5D-3A-3A-44-65-66-61-75-6C-74-29-0D-0A-24-4D-65-73-73-61-67-65' -split '-' | % { [Byte]::Parse($_, 'HexNumber') })
PS> [Text.Encoding]::UTF8.GetString($ByteArray)
$Message = [IO.File]::ReadAllText("$PSScriptRoot\�������.txt", [System.Text.Encoding]::Default)
$Message
PS> [Text.Encoding]::GetEncoding(1251).GetString($ByteArray)
$Message = [IO.File]::ReadAllText("$PSScriptRoot\русский.txt", [System.Text.Encoding]::Default)
$Message
PS> [Text.Encoding]::GetEncoding(1252).GetString($ByteArray)
$Message = [IO.File]::ReadAllText("$PSScriptRoot\ðóññêèé.txt", [System.Text.Encoding]::Default)
$Message
При чтении файлов важно использовать правильную кодировку. И еще одна важная вещь: ваш файл скрипта использует кодовую страницу 1251, а не UTF-8. Также обратите внимание, что последовательность байтов F0-F3-F1-F1-EA-E8-E9 (которые представляют мир русский в кодовой странице 1251) недопустимая последовательность байтов согласно UTF-8, таким образом, вы получаете семь заменяющих символов (U+FFFD) вместо
Поскольку в PowerShell Core по умолчанию используется UTF-8, а в файле сценария нет спецификации, чтобы указать иное (хотя нет спецификации, которая позволяет PowerShell распознавать кодовую страницу 1251), PowerShell Core читает ваш файл с использованием кодировки UTF-8, поэтому пытаясь получить доступ �������.txt (которого у вас нет) вместо русский.txt,
Вы можете легко наблюдать это самостоятельно, если вы измените свой сценарий на запись файла вместо чтения.
PS> $ByteArray2 = [Byte[]](91, 73, 79, 46, 70, 105, 108, 101, 93, 58, 58, 87, 114, 105, 116, 101, 65, 108, 108, 84, 101, 120, 116, 40, 34, 36, 80, 83, 83, 99, 114, 105, 112, 116, 82, 111, 111, 116, 92, 240, 243, 241, 241, 234, 232, 233, 46, 116, 120, 116, 34, 44, 32, 91, 68, 97, 116, 101, 84, 105, 109, 101, 93, 58, 58, 85, 116, 99, 78, 111, 119, 41)
PS> # Representing `[IO.File]::WriteAllText("$PSScriptRoot\русский.txt", [DateTime]::UtcNow)` in codepage 1251
PS> [IO.File]::WriteAllBytes("$(Convert-Path .)\write.ps1", $ByteArray2)
PS> .\write.ps1
Теперь вы можете прочитать файл обратно с вашим оригинальным скриптом:
PS> [IO.File]::WriteAllBytes("$(Convert-Path .)\asd.ps1", $ByteArray)
PS> .\asd.ps1
01/18/2019 17:13:15
Вызов обоих скриптов с помощью PowerShell Core:
PS> pwsh -Command ".\write.ps1; .\asd.ps1"
01/18/2019 17:21:02
Как видите, ваш скрипт успешно выполнен в PowerShell Core. Если вы просматриваете текущий каталог, то вы можете видеть, что он имеет оба русский.txt а также �������.txt в этом и их содержание совпадает с тем, что было напечатано на консоли.
На самом деле проблема не в том, чтобы делать чтение / запись файлов (кроме самого файла скрипта). Это можно продемонстрировать простым скриптом, который просто печатает коды символов строкового литерала:
PS> $ByteArray3 = [Byte[]](40, 39, 240, 243, 241, 241, 234, 232, 233, 39, 46, 71, 101, 116, 69, 110, 117, 109, 101, 114, 97, 116, 111, 114, 40, 41, 32, 124, 32, 37, 32, 84, 111, 73, 110, 116, 51, 50, 32, 36, 110, 117, 108, 108, 32, 124, 32, 37, 32, 84, 111, 83, 116, 114, 105, 110, 103, 32, 88, 52, 41, 32, 45, 106, 111, 105, 110, 32, 39, 45, 39)
PS> # Representing `('русский'.GetEnumerator() | % ToInt32 $null | % ToString X4) -join '-'` in codepage 1251
PS> [IO.File]::WriteAllBytes("$(Convert-Path .)\test.ps1", $ByteArray3)
Вызов его в Windows PowerShell даст один результат:
PS> .\test.ps1
0440-0443-0441-0441-043A-0438-0439
В то время как PowerShell Core даст другой:
PS> pwsh -Command ".\test.ps1"
FFFD-FFFD-FFFD-FFFD-FFFD-FFFD-FFFD
Одним из способов решения этой проблемы является использование UTF-8 с спецификацией, которая гарантирует, что и Windows PowerShell, и PowerShell Core будут использовать одинаковую кодировку при чтении файлов сценариев.
Ответ написан с предположением, что [Text.Encoding]::Default.CodePage верните 1251, как кажется в случае с ОП.
Windows использует специфичную для Windows кодировку символов cp1252. Чтобы использовать символы Юникода, вам нужно выполнить эту команду до того, как вы впервые захотите что-то сделать с этим файлом:
chcp 65001 | Out-Null # set codepage to UTF-8
$Message = [System.IO.File]::ReadAllText("$PSScriptRoot\русский.txt")
или же
chcp 65001 | Out-Null # set codepage to UTF-8
$Message = Get-Content "$PSScriptRoot\русский.txt"
надеюсь, это поможет