Как искать содержимое нескольких файлов PDF?
Как я могу искать содержимое файлов PDF в каталоге / подкаталоге? Я ищу некоторые инструменты командной строки. Кажется, что grep не могу искать файлы PDF.
15 ответов
Ваш дистрибутив должен предоставлять утилиту под названием pdftotext:
find /path -name '*.pdf' -exec sh -c 'pdftotext "{}" - | grep --with-filename --label="{}" --color "your pattern"' \;
"-" необходимо для вывода pdftotext на стандартный вывод, а не на файлы. --with-filename а также --label= Опции поместят имя файла в вывод grep. Необязательный --color флажок хороший и говорит grep выводить используя цвета на терминале.
(В Ubuntu pdftotext предоставляется пакетом xpdf-utils или же poppler-utils.)
Этот метод, используя pdftotext а также grepимеет преимущество перед pdfgrep если вы хотите использовать функции GNU grep тот pdfgrep не поддерживает Примечание: pdfgrep-1.3.x поддерживает -C опция для печати строки контекста.
Существует pdfgrep, который делает именно то, что предполагает его название.
pdfgrep -R 'a pattern to search recursively from path' /some/path
Я использовал его для простых поисков, и он работал нормально.
(Есть пакеты в Debian, Ubuntu и Fedora.)
Начиная с версии 1.3.0 pdfgrep поддерживает рекурсивный поиск. Эта версия доступна в Ubuntu начиная с Ubuntu 12.10 (Quantal).
Recoll - это фантастическое приложение для полнотекстового поиска с графическим интерфейсом для Unix/Linux, которое поддерживает десятки различных форматов, включая PDF. Он может даже передавать точный номер страницы и поисковый запрос в просмотрщик документов и, таким образом, позволяет переходить к результату прямо из его графического интерфейса.
Recoll также поставляется с жизнеспособным интерфейсом командной строки и интерфейсом веб-браузера.
Есть еще одна утилита под названием ripgrep-all, основанная на ripgrep.
Он может обрабатывать не только PDF-документы, такие как документы и фильмы Office, и автор утверждает, что это быстрее, чемpdfgrep.
Синтаксис команды для рекурсивного поиска в текущем каталоге, а второй ограничивается только файлами PDF:
rga 'pattern' .
rga --type pdf 'pattern' .
Моя актуальная версия pdfgrep (1.3.0) позволяет следующее:
pdfgrep -HiR 'pattern' /path
При выполнении pdfgrep --help:
- H: Напечатайте имя файла для каждого совпадения.
- я: игнорировать различия в регистре
- Р: Поиск по каталогам рекурсивно.
Это хорошо работает на моем Ubuntu.
Я сделал этот разрушительный маленький сценарий. Веселитесь с этим.
function pdfsearch()
{
find . -iname '*.pdf' | while read filename
do
#echo -e "\033[34;1m// === PDF Document:\033[33;1m $filename\033[0m"
pdftotext -q -enc ASCII7 "$filename" "$filename."; grep -s -H --color=always -i $1 "$filename."
# remove it! rm -f "$filename."
done
}
Мне нравится ответ @sjr, но я предпочитаю xargs vs -exec. Я считаю Xargs более универсальным. Например, с помощью -P мы можем использовать преимущества нескольких процессоров, когда это имеет смысл.
find . -name '*.pdf' | xargs -P 5 -I % pdftotext % - | grep --with-filename --label="{}" --color "pattern"
Если вы хотите увидеть имена файлов с помощью pdftotext, используйте следующую команду:
find . -name '*.pdf' -exec echo {} \; -exec pdftotext {} - \; | grep "pattern\|pdf"
Сначала преобразуйте все ваши PDF-файлы в текстовые файлы:
for file in *.pdf;do pdftotext "$file"; done
Тогда используйте grep как обычно. Это особенно хорошо, поскольку это быстро, когда у вас есть несколько запросов и много файлов PDF.
У меня была та же проблема, и поэтому я написал скрипт, который ищет строку во всех файлах pdf в указанной папке и печатает файлы PDF, которые соответствуют строке запроса.
Может быть, это будет полезно для вас.
Вы можете скачать его здесь
Существует общедоступная утилита grep с открытым исходным кодом crgrep, которая выполняет поиск в файлах PDF, а также в других ресурсах, таких как содержимое, вложенное в архивы, таблицы базы данных, метаданные изображений, зависимости файлов POM и веб-ресурсы - и их комбинации, включая рекурсивный поиск.
Полное описание на вкладке Файлы в значительной степени охватывает то, что поддерживает инструмент.
Я разработал crgrep как инструмент с открытым исходным кодом.
Вам нужны некоторые инструменты, такие как pdf2text, чтобы сначала преобразовать ваш pdf в текстовый файл, а затем искать внутри текста. (Вы, вероятно, пропустите некоторую информацию или символы).
Если вы используете язык программирования, вероятно, для этой цели написаны библиотеки pdf. например, http://search.cpan.org/dist/CAM-PDF/ для Perl
Попробуйте использовать 'acroread' в простом скрипте, подобном приведенному выше
Спасибо за все хорошие идеи здесь!
Я попробовал метод xargs, но, как указано здесь, xargs сделает невозможным (или очень сложным) включение печати фактического имени файла...
Поэтому я попробовал все это с GNU parallel.
parallel "pdftotext -q {} - | grep --with-filename --label='['{}']' --color=always --context=5 'pattern'" ::: *.pdf
- При этом печатается не только шаблон, но и
--context=5также 5 строк выше и ниже, а также для контекста. - С
-qpdftotext не будет печатать никаких сообщений об ошибках или предупреждений (тихо). - я использую скобки
[]как метки вместо фигурных скобок. Если вы хотели брекеты--label='{'{}'}'заставит это случиться. Обратите внимание, что фактическое имя файла заменяется параллельным GNU, например'Example portable document file name with spaces.pdf'({}уже использует одинарные кавычки'). - Используя
--label={}будет напечатано только имя файла, что может быть предпочтительным способом отображения имени файла. - Я также заметил, что вывод был без цвета, когда я пробовал, за исключением случаев, когда он был принудительно добавлен
--color=alwaysс грэп. - Может быть полезно добавить в команду grep поиск по ключевым словам без учета регистра.
Если все файлы PDF должны обрабатываться рекурсивно, включая все подкаталоги в текущем каталоге (
.), это можно сделать с помощью find:
find . -type f -iname '*.pdf' -print0 | parallel -0 "pdftotext -q {} - | grep --with-filename --label='['{}']' --color=always --context=5 'pattern'"
- С находкой,
-iname '*.pdf'действует без учета регистра. С-name '*.pdf'будут включены только файлы .pdf в нижнем регистре (обычный случай). Поскольку я иногда также сталкивался с файлами Windows PDF с расширением файла .PDF в верхнем регистре, я предпочитаю-iname... - Приведенная выше команда также работает с
-printнайти вариант (вместо-print0), поэтому он будет основан на строках (одно имя файла в строке), затем-0(разделитель NUL) должен быть опущен в параллельной команде. - Опять же, в том числе
--ignore-caseв команде grep сделает поиск нечувствительным к регистру.
В качестве общей рекомендации при игре со всей командной строкой,
parallel --dry-runнапечатает, какие команды будут выполнены.
$ find . -type f -iname '*.pdf' -print0 | parallel --dry-run -0 "pdftotext -q {} - | grep --with-filename --label='['{}']' --color=always --ignore-case --context=5 'pattern'"
pdftotext -q ./test PDF file 1.pdf - | grep --with-filename --label='['./test PDF file 1.pdf']' --color=always --ignore-case --context=5 'pattern'
pdftotext -q ./subdir1/test PDF file 2.pdf - | grep --with-filename --label='['./subdir1/test PDF file 2.pdf']' --color=always --ignore-case --context=5 'pattern'
pdftotext -q ./subdir2/test PDF file 3.pdf - | grep --with-filename --label='['./subdir2/test PDF file 3.pdf']' --color=always --ignore-case --context=5 'pattern'
Использовать:
pdfgrep -HinR 'FWCOSP' DatenModel/
В этой команде я ищу слово
FWCOSPвнутри папки
DatenModel/.
Как вы можете видеть в выводе, вы можете получить имя файла с номерами строк:
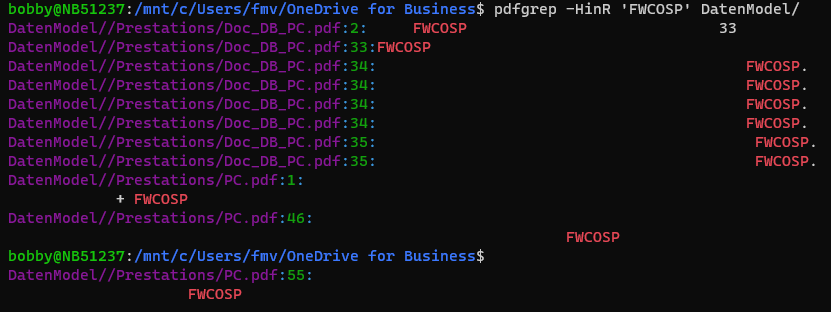
Варианты, которые я использую:
-i : Ignores, case for matching
-H : print the file name for each match
-n : prefix each match with the number of the page where it is found
-R : same as -r, but it also follows all symlinks.