Как создать счетные и процентные таблицы и линейные графики с 1 независимой переменной и 3 зависимыми
Я неофит, и почему-то эта проблема кажется тривиальной. Но, к сожалению, я не смог сделать это после трех дней поиска и экспериментов.
Мои данные в форме, близкой к широкой:
color agegroup sex ses
red 2 Female A
blue 2 Female C
green 5 Male D
red 3 Female A
red 2 Male B
blue 1 Female B
...
Я пытаюсь создать презентабельные таблицы с количеством и процентами зависимой переменной (color здесь) организовано sex, ses а также agegroup, Мне нужен один стол, организованный ses а также sex для каждого agegroup со счетчиками рядом с процентами, вот так:
agegroup: 1
sex: Female Male
ses: A B C D A B C D
color:
red 2 1% 0 0% 8 4% 22 11% 16 8% 2 1% 8 4% 3 1.5%
blue 9 4.5% 6 3% 4 2% 2 1% 12 6% 32 16% 14 7% 6 3%
green 4 2% 12 6% 2 1% 8 4% 0 0% 22 11% 40 20% 0 0%
agegroup: 2
sex: Female Male
ses: A B C D A B C D
color:
red 2 1% 0 0% 8 4% 22 11% 16 8% 2 1% 8 4% 3 1.5%
blue 9 4.5% 6 3% 4 2% 2 1% 12 6% 32 16% 14 7% 6 3%
green 4 2% 12 6% 2 1% 8 4% 0 0% 22 11% 40 20% 0 0%
Я пытался сделать это со всем от datatables а также expss в gmodels, но я просто не могу понять, как получить вывод, как это. CrossTables от gmodels ближе всего, но это все еще довольно далеко - (1) он ставит проценты под счета, (2) я не могу получить его в гнездо sel под sex, (3) я не могу понять, как заставить его разбивать результаты по поколениям, и (4) выходные данные полны тире, вертикальных каналов и пробелов, которые делают помещение его в текстовый процессор или электронную таблицу подверженным ошибкам ручное дело.
РЕДАКТИРОВАТЬ: я удалил свой второй вопрос (о линейных графиках), потому что ответ на первый вопрос является идеальным и заслуживает похвалы, даже если он не касается второго. Я задам второй вопрос отдельно, как я должен был с самого начала.
2 ответа
Ближайший результат с expss пакет:
library(expss)
# generate example data
set.seed(123)
N = 300
df = data.frame(
color = sample(c("red", "blue", "green"), size = N, replace = TRUE),
agegroup = sample(1:5, size = N, replace = TRUE),
sex = sample(c("Male", "Female"), size = N, replace = TRUE),
ses = sample(c("A", "B", "C", "D"), size = N, replace = TRUE),
stringsAsFactors = FALSE
)
# redirect output to RStudio HTML viewer
expss_output_viewer()
res = df %>%
tab_cells("|" = color) %>% # dependent variable, "|" used to suppress label
tab_cols(sex %nest% ses) %>% # column variable
tab_rows(agegroup) %>%
tab_total_row_position("none") %>% # we don't need total
tab_stat_cases(label = "Cases") %>% # calculate cases
tab_stat_cpct(label = "%") %>% # calculate percent
tab_pivot(stat_position = "inside_columns") %>% # finalize table
make_subheadings(number_of_columns = 2)
# difficult part - add percent sign
for(i in grep("%", colnames(res))){
res[[i]] = ifelse(trimws(res[[i]])!="",
paste0(round(res[[i]], 1), "%"),
res[[i]]
)
}
# additionlly remove stat labels
colnames(res) = gsub("\\|Cases|%", "", colnames(res), perl = TRUE)
res
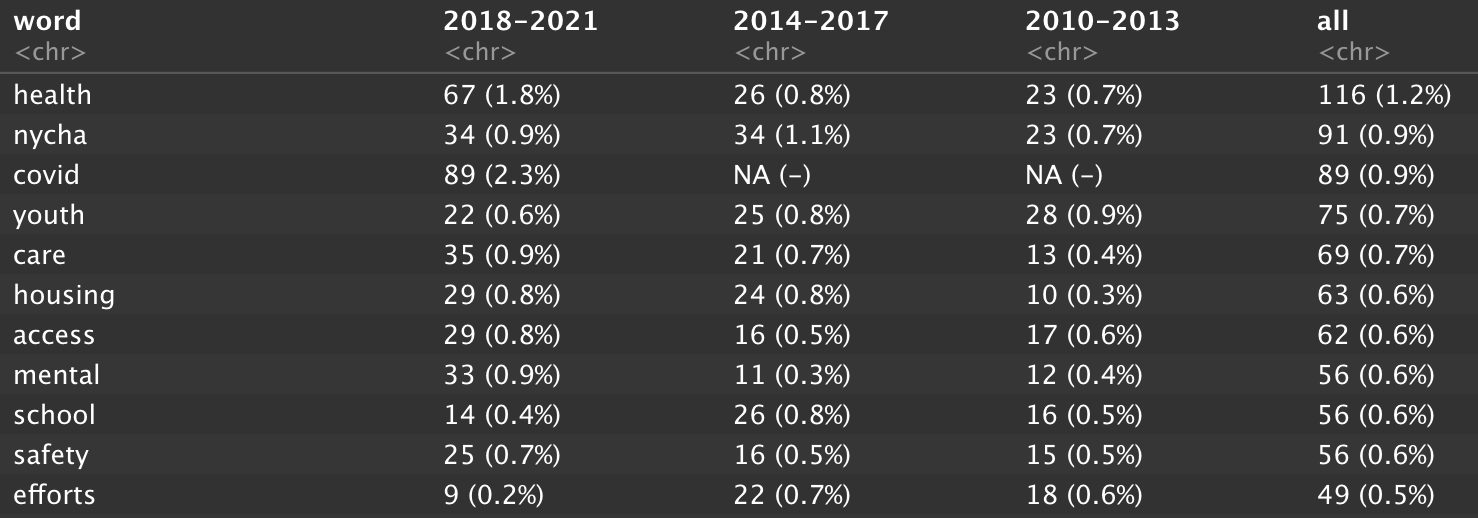
В RStudio Viewer результат будет в формате HTML (см. Изображение). К сожалению, я не могу проверить, как это будет вставлено в MS Word.  Отказ от ответственности: я автор
Отказ от ответственности: я автор expss пакет.
Вы можете использовать
adorn_ns(position = "front")из пакета дворник. Это даст вам количество и проценты вместе.
Например, этот код:
df %>%
arrange(desc(all)) %>%
adorn_percentages("col") %>%
adorn_pct_formatting() %>%
adorn_ns(position = "front") %>%
as.data.frame()
дает этот вывод: